 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Bayesian Logic
Jul 04, 2012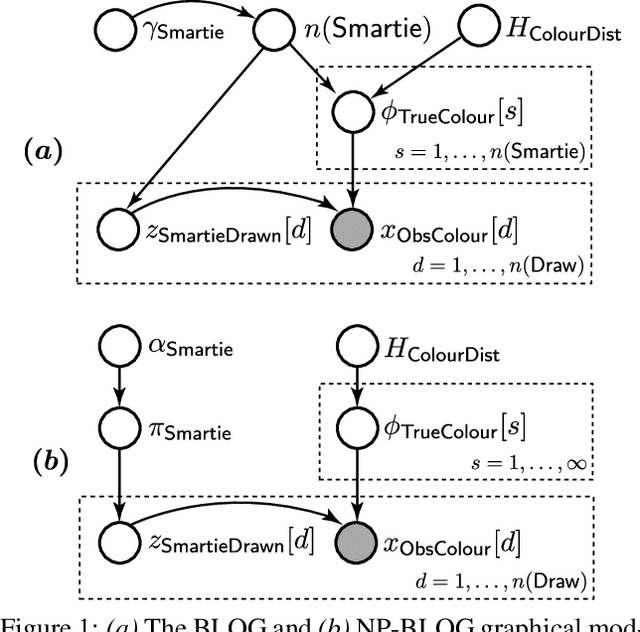
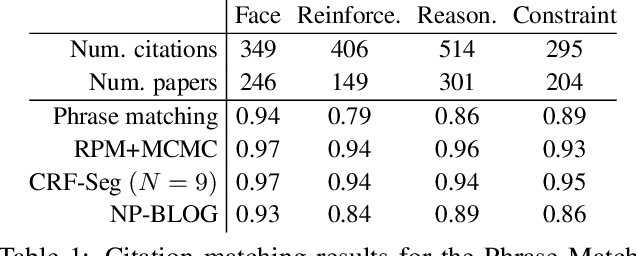
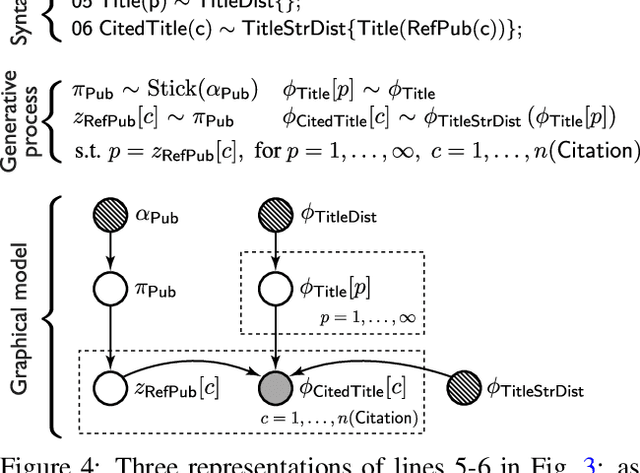
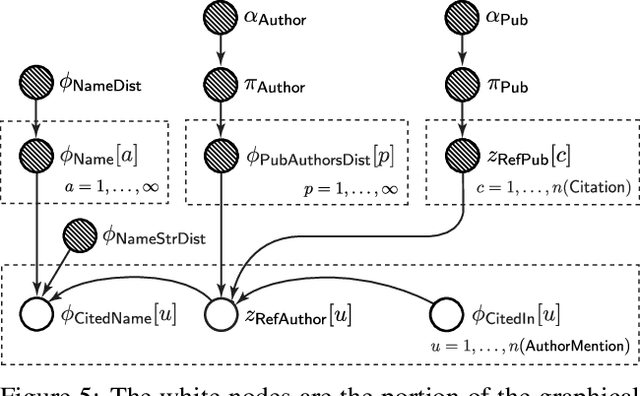
The Bayesian Logic (BLOG) language was recently developed for defining first-order probability models over worlds with unknown numbers of objects. It handles important problems in AI, including data association and population estimation. This paper extends BLOG by adopting generative processes over function spaces - known as nonparametrics in the Bayesian literature. We introduce syntax for reasoning about arbitrary collections of objects, and their properties, in an intuitive manner. By exploiting exchangeability, distributions over unknown objects and their attributes are cast as Dirichlet processes, which resolve difficulties in model selection and inference caused by varying numbers of objects. We demonstrate these concepts with application to citation matching.
Constraint Processing in Lifted Probabilistic Inference
May 09, 2012



First-order probabilistic models combine representational power of first-order logic with graphical models. There is an ongoing effort to design lifted inference algorithms for first-order probabilistic models. We analyze lifted inference from the perspective of constraint processing and, through this viewpoint, we analyze and compare existing approaches and expose their advantages and limitations. Our theoretical results show that the wrong choice of constraint processing method can lead to exponential increase in computational complexity. Our empirical tests confirm the importance of constraint processing in lifted inference. This is the first theoretical and empirical study of constraint processing in lifted inference.
Towards Completely Lifted Search-based Probabilistic Inference
Jul 21, 2011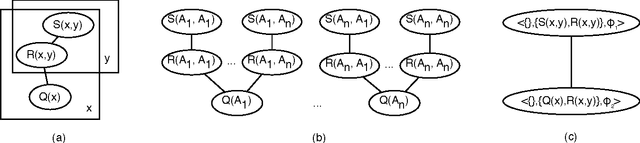

The promise of lifted probabilistic inference is to carry out probabilistic inference in a relational probabilistic model without needing to reason about each individual separately (grounding out the representation) by treating the undistinguished individuals as a block. Current exact methods still need to ground out in some cases, typically because the representation of the intermediate results is not closed under the lifted operations. We set out to answer the question as to whether there is some fundamental reason why lifted algorithms would need to ground out undifferentiated individuals. We have two main results: (1) We completely characterize the cases where grounding is polynomial in a population size, and show how we can do lifted inference in time polynomial in the logarithm of the population size for these cases. (2) For the case of no-argument and single-argument parametrized random variables where the grounding is not polynomial in a population size, we present lifted inference which is polynomial in the population size whereas grounding is exponential. Neither of these cases requires reasoning separately about the individuals that are not explicitly mentioned.