 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined Policy Improvement Bounds for MDPs
Jul 16, 2021The policy improvement bound on the difference of the discounted returns plays a crucial role in the theoretical justification of the trust-region policy optimization (TRPO) algorithm. The existing bound leads to a degenerate bound when the discount factor approaches one, making the applicability of TRPO and related algorithms questionable when the discount factor is close to one. We refine the results in \cite{Schulman2015, Achiam2017} and propose a novel bound that is "continuous" in the discount factor. In particular, our bound is applicable for MDPs with the long-run average rewards as well.
A High-fidelity, Machine-learning Enhanced Queueing Network Simulation Model for Hospital Ultrasound Operations
Apr 12, 2021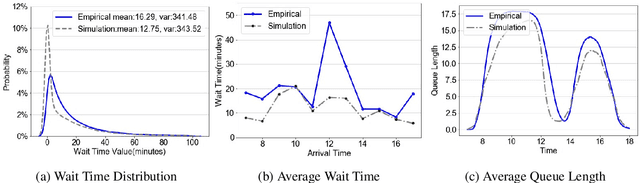

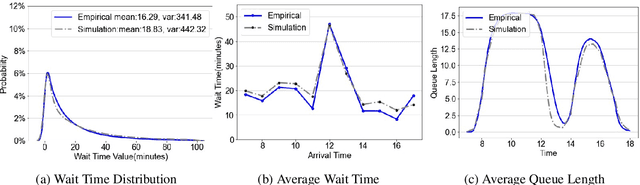

We collaborate with a large teaching hospital in Shenzhen, China and build a high-fidelity simulation model for its ultrasound center to predict key performance metrics, including the distributions of queue length, waiting time and sojourn time, with high accuracy. The key challenge to build an accurate simulation model is to understanding the complicated patient routing at the ultrasound center. To address the issue, we propose a novel two-level routing component to the queueing network model. We apply machine learning tools to calibrate the key components of the queueing model from data with enhanced accuracy.
Scalable Deep Reinforcement Learning for Ride-Hailing
Sep 27, 2020

Ride-hailing services, such as Didi Chuxing, Lyft, and Uber, arrange thousands of cars to meet ride requests throughout the day. We consider a Markov decision process (MDP) model of a ride-hailing service system, framing it as a reinforcement learning (RL) problem. The simultaneous control of many agents (cars) presents a challenge for the MDP optimization because the action space grows exponentially with the number of cars. We propose a special decomposition for the MDP actions by sequentially assigning tasks to the drivers. The new actions structure resolves the scalability problem and enables the use of deep RL algorithms for control policy optimization. We demonstrate the benefit of our proposed decomposition with a numerical experiment based on real data from Didi Chuxing.
Queueing Network Controls via Deep Reinforcement Learning
Aug 27, 2020

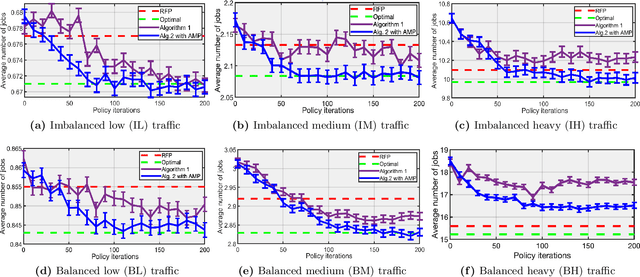
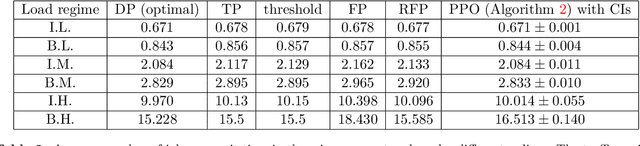
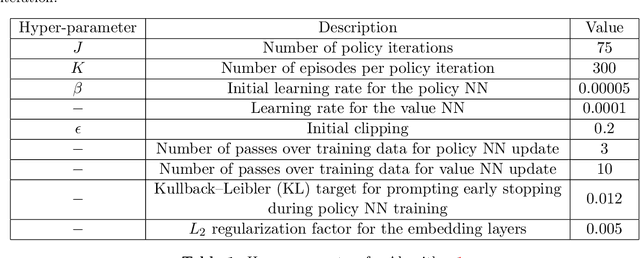
Novel advanced policy gradient (APG) methods, such as Trust Region policy optimization and Proximal policy optimization (PPO), have become the dominant reinforcement learning algorithms because of their ease of implementation and good practical performance. A conventional setup for notoriously difficult queueing network control problems is a Markov decision problem (MDP) that has three features: infinite state space, unbounded costs, and long-run average cost objective. We extend the theoretical framework of these APG methods for such MDP problems. The resulting PPO algorithm is tested on a parallel-server system and large-size multiclass queueing networks. The algorithm consistently generates control policies that outperform state-of-art heuristics in literature in a variety of load conditions from light to heavy traffic. These policies are demonstrated to be near-optimal when the optimal policy can be computed. A key to the successes of our PPO algorithm is the use of three variance reduction techniques in estimating the relative value function via sampling. First, we use a discounted relative value function as an approximation of the relative value function. Second, we propose regenerative simulation to estimate the discounted relative value function. Finally, we incorporate the approximating martingale-process method into the regenerative estimator.