 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynGraphy: Succinct Summarisation of Large Networks via Small Synthetic Representative Graphs
Feb 15, 2023
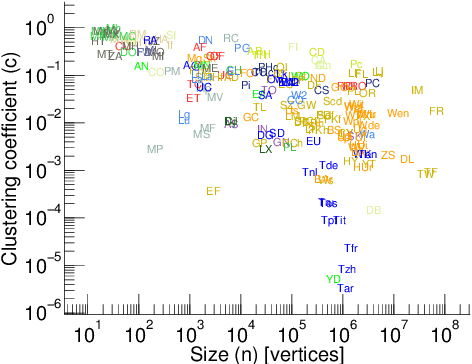
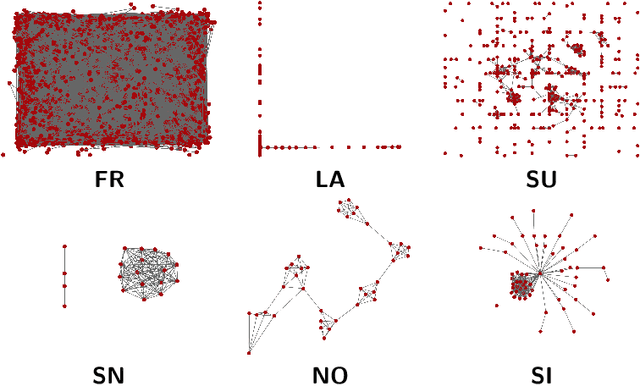
We describe SynGraphy, a method for visually summarising the structure of large network datasets that works by drawing smaller graphs generated to have similar structural properties to the input graphs. Visualising complex networks is crucial to understand and make sense of networked data and the relationships it represents. Due to the large size of many networks, visualisation is extremely difficult; the simple method of drawing large networks like those of Facebook or Twitter leads to graphics that convey little or no information. While modern graph layout algorithms can scale computationally to large networks, their output tends to a common "hairball" look, which makes it difficult to even distinguish different graphs from each other. Graph sampling and graph coarsening techniques partially address these limitations but they are only able to preserve a subset of the properties of the original graphs. In this paper we take the problem of visualising large graphs from a novel perspective: we leave the original graph's nodes and edges behind, and instead summarise its properties such as the clustering coefficient and bipartivity by generating a completely new graph whose structural properties match that of the original graph. To verify the utility of this approach as compared to other graph visualisation algorithms, we perform an experimental evaluation in which we repeatedly asked experimental subjects (professionals in graph mining and related areas) to determine which of two given graphs has a given structural property and then assess which visualisation algorithm helped in identifying the correct answer. Our summarisation approach SynGraphy compares favourably to other techniques on a variety of networks.
Modeling the Evolution of Networks as Shrinking Structural Diversity
Sep 21, 2020
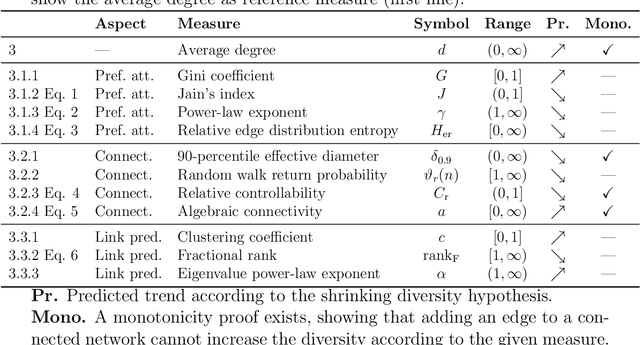


This article reviews and evaluates models of network evolution based on the notion of structural diversity. We show that diversity is an underlying theme of three principles of network evolution: the preferential attachment model, connectivity and link prediction. We show that in all three cases, a dominant trend towards shrinking diversity is apparent, both theoretically and empirically. In previous work, many kinds of different data have been modeled as networks: social structure, navigational structure, transport infrastructure, communication, etc. Almost all these types of networks are not static structures, but instead dynamic systems that change continuously. Thus, an important question concerns the trends observable in these networks and their interpretation in terms of existing network models. We show in this article that most numerical network characteristics follow statistically significant trends going either up or down, and that these trends can be predicted by considering the notion of diversity. Our work extends previous work observing a shrinking network diameter to measures such as the clustering coefficient, power-law exponent and random walk return probability, and justifies preferential attachment models and link prediction algorithms. We evaluate our hypothesis experimentally using a diverse collection of twenty-seven temporally evolving real-world network datasets.
Understanding Social Networks using Transfer Learning
Oct 16, 2019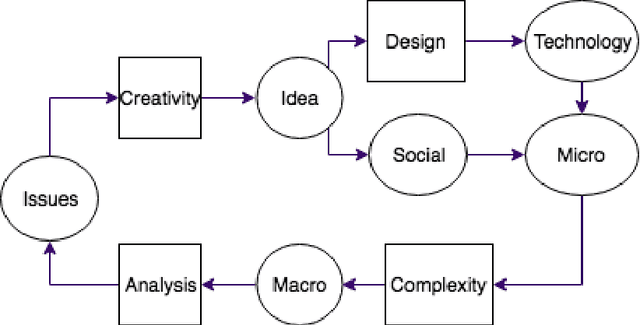
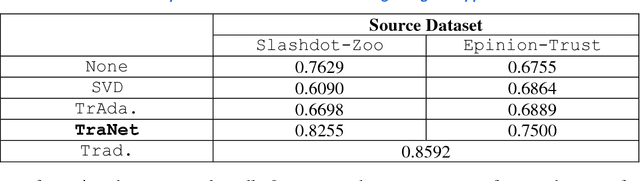
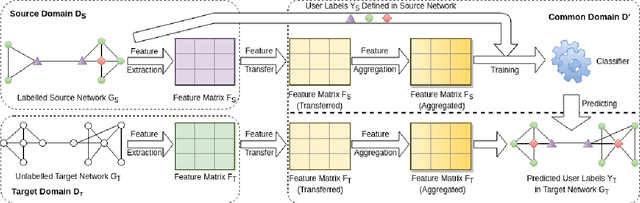
A detailed understanding of users contributes to the understanding of the Web's evolution, and to the development of Web applications. Although for new Web platforms such a study is especially important, it is often jeopardized by the lack of knowledge about novel phenomena due to the sparsity of data. Akin to human transfer of experiences from one domain to the next, transfer learning as a subfield of machine learning adapts knowledge acquired in one domain to a new domain. We systematically investigate how the concept of transfer learning may be applied to the study of users on newly created (emerging) Web platforms, and propose our transfer learning-based approach, TraNet. We show two use cases where TraNet is applied to tasks involving the identification of user trust and roles on different Web platforms. We compare the performance of TraNet with other approaches and find that our approach can best transfer knowledge on users across platforms in the given tasks.
* 11 pages, 4 figures, IEEE Computer. arXiv admin note: text overlap with arXiv:1611.02941
Predicting User Roles in Social Networks using Transfer Learning with Feature Transformation
Nov 09, 2016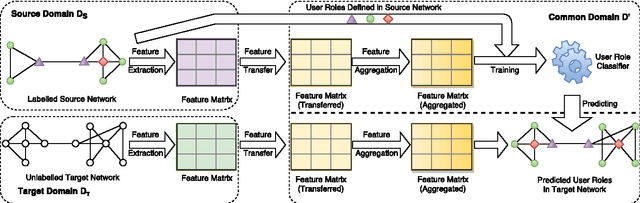
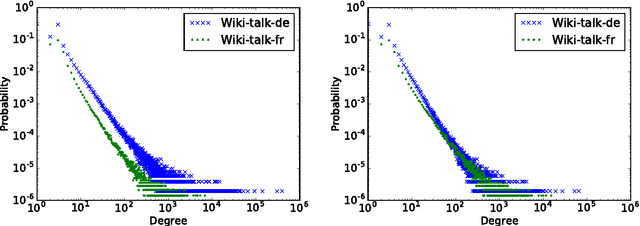
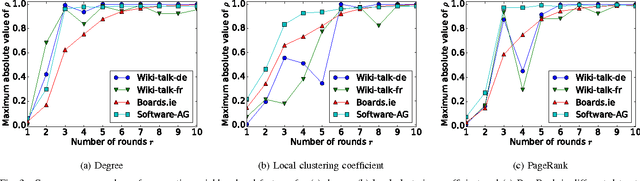
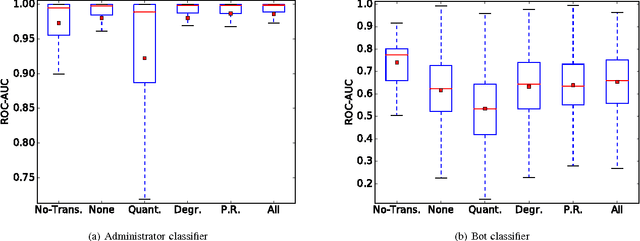
How can we recognise social roles of people, given a completely unlabelled social network? We present a transfer learning approach to network role classification based on feature transformations from each network's local feature distribution to a global feature space. Experiments are carried out on real-world datasets. (See manuscript for the full abstract.)
The Link Prediction Problem in Bipartite Networks
Jun 28, 2010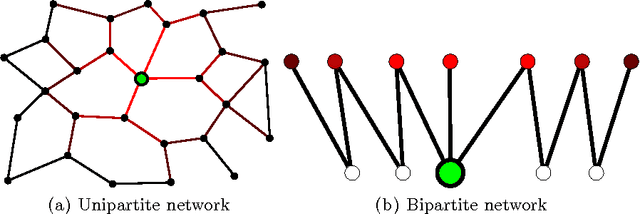
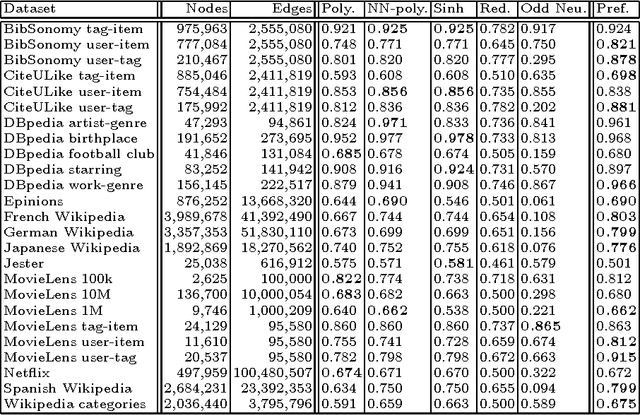
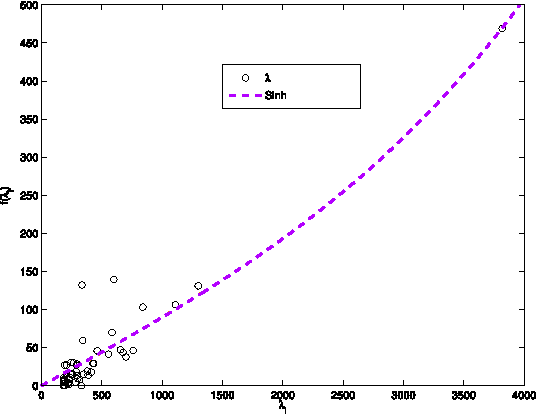
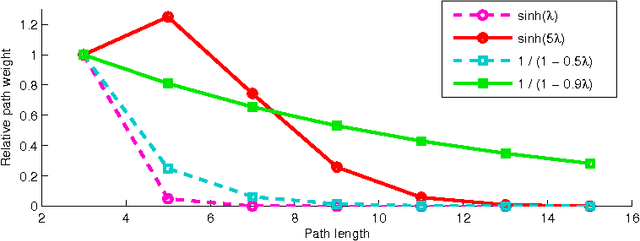
We define and study the link prediction problem in bipartite networks, specializing general link prediction algorithms to the bipartite case. In a graph, a link prediction function of two vertices denotes the similarity or proximity of the vertices. Common link prediction functions for general graphs are defined using paths of length two between two nodes. Since in a bipartite graph adjacency vertices can only be connected by paths of odd lengths, these functions do not apply to bipartite graphs. Instead, a certain class of graph kernels (spectral transformation kernels) can be generalized to bipartite graphs when the positive-semidefinite kernel constraint is relaxed. This generalization is realized by the odd component of the underlying spectral transformation. This construction leads to several new link prediction pseudokernels such as the matrix hyperbolic sine, which we examine for rating graphs, authorship graphs, folksonomies, document--feature networks and other types of bipartite networks.