 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynGraphy: Succinct Summarisation of Large Networks via Small Synthetic Representative Graphs
Feb 15, 2023
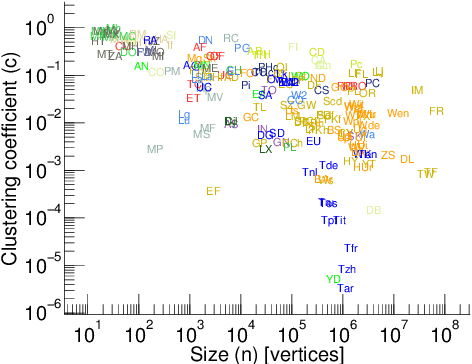
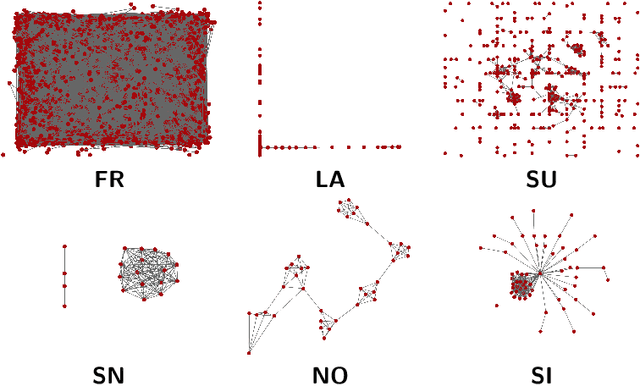
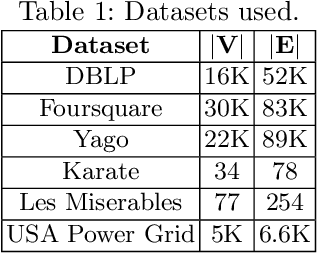
We describe SynGraphy, a method for visually summarising the structure of large network datasets that works by drawing smaller graphs generated to have similar structural properties to the input graphs. Visualising complex networks is crucial to understand and make sense of networked data and the relationships it represents. Due to the large size of many networks, visualisation is extremely difficult; the simple method of drawing large networks like those of Facebook or Twitter leads to graphics that convey little or no information. While modern graph layout algorithms can scale computationally to large networks, their output tends to a common "hairball" look, which makes it difficult to even distinguish different graphs from each other. Graph sampling and graph coarsening techniques partially address these limitations but they are only able to preserve a subset of the properties of the original graphs. In this paper we take the problem of visualising large graphs from a novel perspective: we leave the original graph's nodes and edges behind, and instead summarise its properties such as the clustering coefficient and bipartivity by generating a completely new graph whose structural properties match that of the original graph. To verify the utility of this approach as compared to other graph visualisation algorithms, we perform an experimental evaluation in which we repeatedly asked experimental subjects (professionals in graph mining and related areas) to determine which of two given graphs has a given structural property and then assess which visualisation algorithm helped in identifying the correct answer. Our summarisation approach SynGraphy compares favourably to other techniques on a variety of networks.
Triple2Vec: Learning Triple Embeddings from Knowledge Graphs
May 28, 2019


Graph embedding techniques allow to learn high-quality feature vectors from graph structures and are useful in a variety of tasks, from node classification to clustering. Existing approaches have only focused on learning feature vectors for the nodes in a (knowledge) graph. To the best of our knowledge, none of them has tackled the problem of embedding of graph edges, that is, knowledge graph triples. The approaches that are closer to this task have focused on homogeneous graphs involving only one type of edge and obtain edge embeddings by applying some operation (e.g., average) on the embeddings of the endpoint nodes. The goal of this paper is to introduce Triple2Vec, a new technique to directly embed edges in (knowledge) graphs. Trple2Vec builds upon three main ingredients. The first is the notion of line graph. The line graph of a graph is another graph representing the adjacency between edges of the original graph. In particular, the nodes of the line graph are the edges of the original graph. We show that directly applying existing embedding techniques on the nodes of the line graph to learn edge embeddings is not enough in the context of knowledge graphs. Thus, we introduce the notion of triple line graph. The second is an edge weighting mechanism both for line graphs derived from knowledge graphs and homogeneous graphs. The third is a strategy based on graph walks on the weighted triple line graph that can preserve proximity between nodes. Embeddings are finally generated by adopting the SkipGram model, where sentences are replaced with graph walks. We evaluate our approach on different real world (knowledge) graphs and compared it with related work.
Semantic Navigation on the Web of Data: Specification of Routes, Web Fragments and Actions
Nov 18, 2011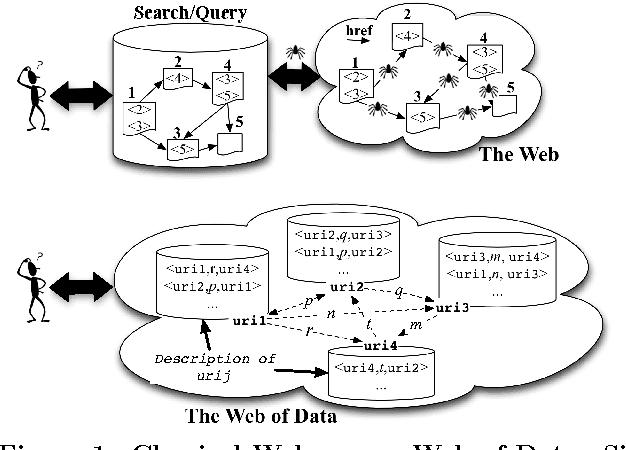
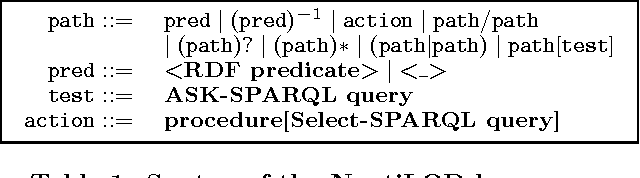
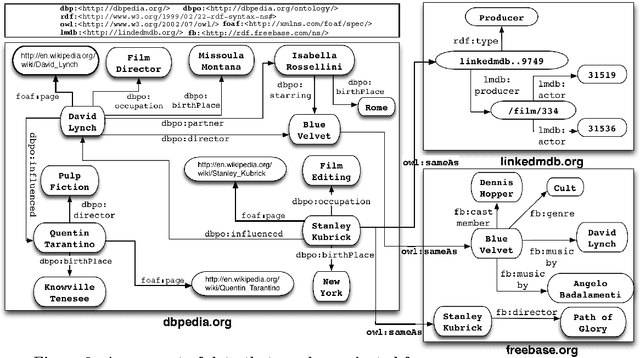
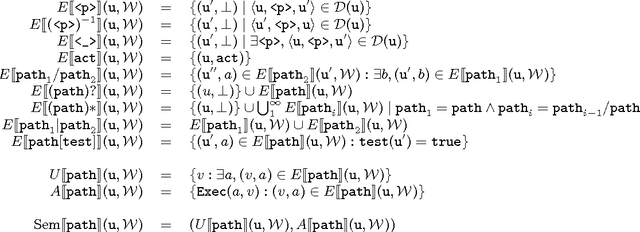
The massive semantic data sources linked in the Web of Data give new meaning to old features like navigation; introduce new challenges like semantic specification of Web fragments; and make it possible to specify actions relying on semantic data. In this paper we introduce a declarative language to face these challenges. Based on navigational features, it is designed to specify fragments of the Web of Data and actions to be performed based on these data. We implement it in a centralized fashion, and show its power and performance. Finally, we explore the same ideas in a distributed setting, showing their feasibility, potentialities and challenges.