 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Encoding of Declare Constraints in ASP
Dec 13, 2024Answer Set Programming (ASP), a well-known declarative logic programming paradigm, has recently found practical application in Process Mining. In particular, ASP has been used to model tasks involving declarative specifications of business processes. In this area, Declare stands out as the most widely adopted declarative process modeling language, offering a means to model processes through sets of constraints valid traces must satisfy, that can be expressed in Linear Temporal Logic over Finite Traces (LTLf). Existing ASP-based solutions encode Declare constraints by modeling the corresponding LTLf formula or its equivalent automaton which can be obtained using established techniques. In this paper, we introduce a novel encoding for Declare constraints that directly models their semantics as ASP rules, eliminating the need for intermediate representations. We assess the effectiveness of this novel approach on two Process Mining tasks by comparing it with alternative ASP encodings and a Python library for Declare. Under consideration in Theory and Practice of Logic Programming (TPLP).
Triple2Vec: Learning Triple Embeddings from Knowledge Graphs
May 28, 2019


Graph embedding techniques allow to learn high-quality feature vectors from graph structures and are useful in a variety of tasks, from node classification to clustering. Existing approaches have only focused on learning feature vectors for the nodes in a (knowledge) graph. To the best of our knowledge, none of them has tackled the problem of embedding of graph edges, that is, knowledge graph triples. The approaches that are closer to this task have focused on homogeneous graphs involving only one type of edge and obtain edge embeddings by applying some operation (e.g., average) on the embeddings of the endpoint nodes. The goal of this paper is to introduce Triple2Vec, a new technique to directly embed edges in (knowledge) graphs. Trple2Vec builds upon three main ingredients. The first is the notion of line graph. The line graph of a graph is another graph representing the adjacency between edges of the original graph. In particular, the nodes of the line graph are the edges of the original graph. We show that directly applying existing embedding techniques on the nodes of the line graph to learn edge embeddings is not enough in the context of knowledge graphs. Thus, we introduce the notion of triple line graph. The second is an edge weighting mechanism both for line graphs derived from knowledge graphs and homogeneous graphs. The third is a strategy based on graph walks on the weighted triple line graph that can preserve proximity between nodes. Embeddings are finally generated by adopting the SkipGram model, where sentences are replaced with graph walks. We evaluate our approach on different real world (knowledge) graphs and compared it with related work.
From Community Detection to Community Deception
Sep 01, 2016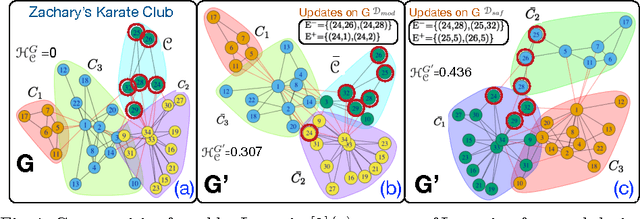

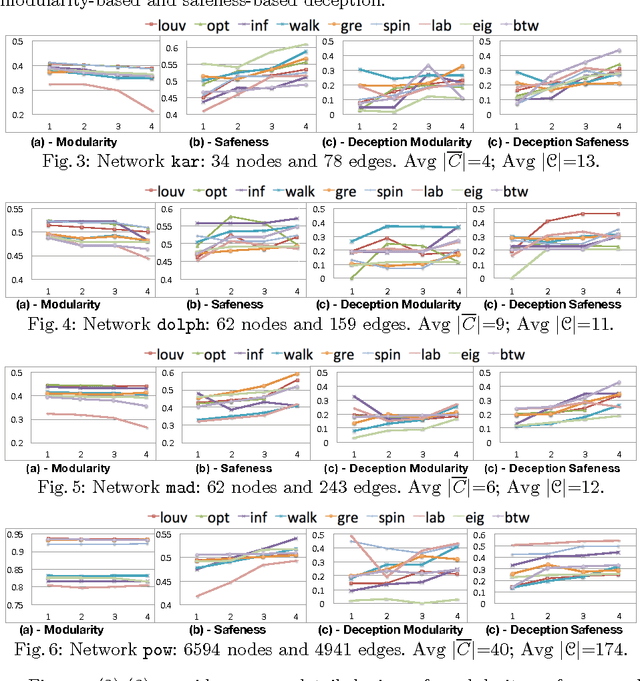
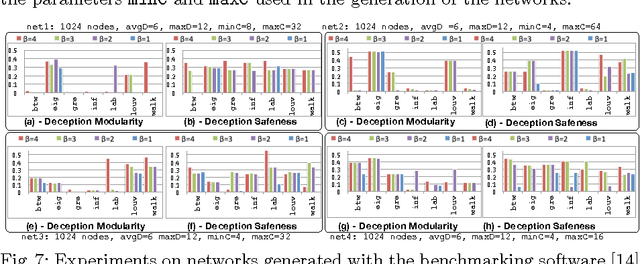
The community deception problem is about how to hide a target community C from community detection algorithms. The need for deception emerges whenever a group of entities (e.g., activists, police enforcements) want to cooperate while concealing their existence as a community. In this paper we introduce and formalize the community deception problem. To solve this problem, we describe algorithms that carefully rewire the connections of C's members. We experimentally show how several existing community detection algorithms can be deceived, and quantify the level of deception by introducing a deception score. We believe that our study is intriguing since, while showing how deception can be realized it raises awareness for the design of novel detection algorithms robust to deception techniques.
Semantic Navigation on the Web of Data: Specification of Routes, Web Fragments and Actions
Nov 18, 2011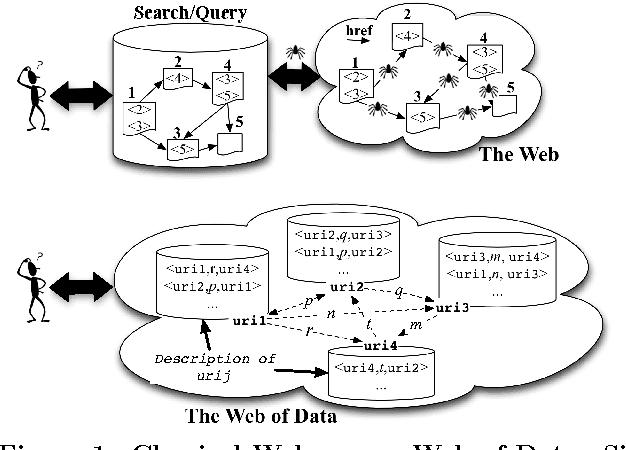
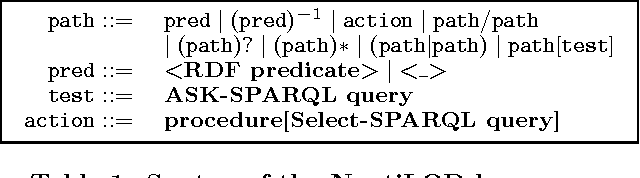
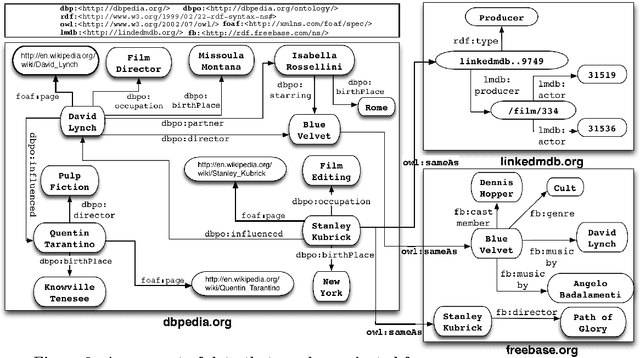
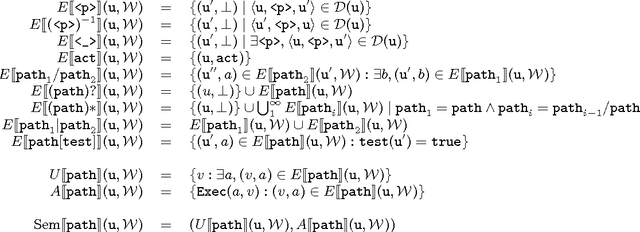
The massive semantic data sources linked in the Web of Data give new meaning to old features like navigation; introduce new challenges like semantic specification of Web fragments; and make it possible to specify actions relying on semantic data. In this paper we introduce a declarative language to face these challenges. Based on navigational features, it is designed to specify fragments of the Web of Data and actions to be performed based on these data. We implement it in a centralized fashion, and show its power and performance. Finally, we explore the same ideas in a distributed setting, showing their feasibility, potentialities and challenges.