 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe effect of Target Normalization and Momentum on Dying ReLU
May 13, 2020
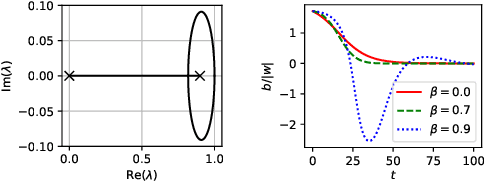
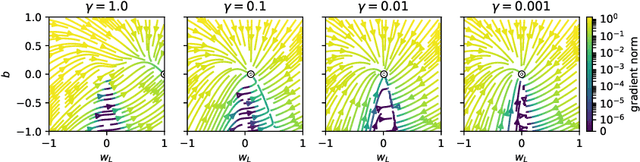
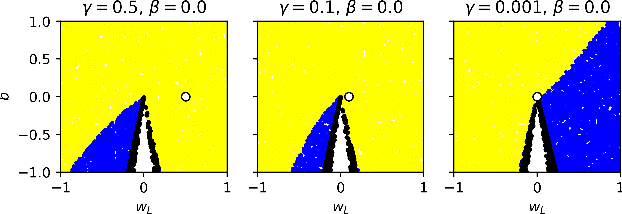
Optimizing parameters with momentum, normalizing data values, and using rectified linear units (ReLUs) are popular choices in neural network (NN) regression. Although ReLUs are popular, they can collapse to a constant function and "die", effectively removing their contribution from the model. While some mitigations are known, the underlying reasons of ReLUs dying during optimization are currently poorly understood. In this paper, we consider the effects of target normalization and momentum on dying ReLUs. We find empirically that unit variance targets are well motivated and that ReLUs die more easily, when target variance approaches zero. To further investigate this matter, we analyze a discrete-time linear autonomous system, and show theoretically how this relates to a model with a single ReLU and how common properties can result in dying ReLU. We also analyze the gradients of a single-ReLU model to identify saddle points and regions corresponding to dying ReLU and how parameters evolve into these regions when momentum is used. Finally, we show empirically that this problem persist, and is aggravated, for deeper models including residual networks.
[Re] Learning to Learn By Self-Critique
Dec 05, 2019![Figure 1 for [Re] Learning to Learn By Self-Critique](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F7e6471a725924938cbe0b5f9c124a46ecbcb345c%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for [Re] Learning to Learn By Self-Critique](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F7e6471a725924938cbe0b5f9c124a46ecbcb345c%2F7-Table1-1.png&w=640&q=75)
![Figure 3 for [Re] Learning to Learn By Self-Critique](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F7e6471a725924938cbe0b5f9c124a46ecbcb345c%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [Re] Learning to Learn By Self-Critique](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F7e6471a725924938cbe0b5f9c124a46ecbcb345c%2F7-Table2-1.png&w=640&q=75)
This work is a reproducibility study of the paper of Antoniou and Storkey [2019], published at NeurIPS 2019. Our results are in parts similar to the ones reported in the original paper, supporting the central claim of the paper that the proposed novel method, called Self-Critique and Adapt (SCA), improves the performance of MAML++. The conducted additional experiments on the Caltech-UCSD Birds 200 dataset confirm the superiority of SCA compared to MAML++. In addition, the reproduced paper suggests a novel high-end version of MAML++ for which we could not reproduce the same results. We hypothesize that this is due to the many implementation details that were omitted in the original paper.
Learning Manipulation States and Actions for Efficient Non-prehensile Rearrangement Planning
Jan 11, 2019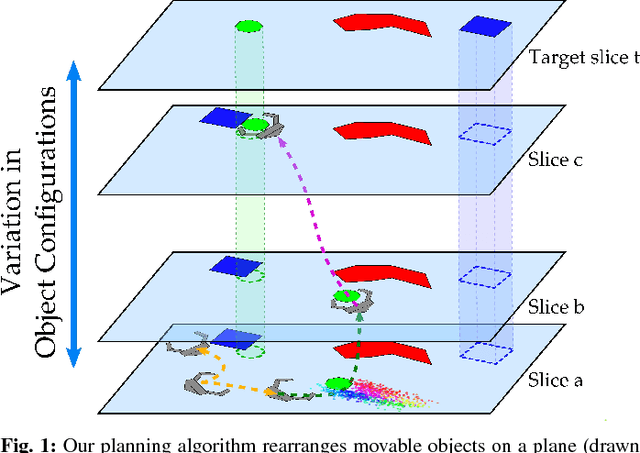
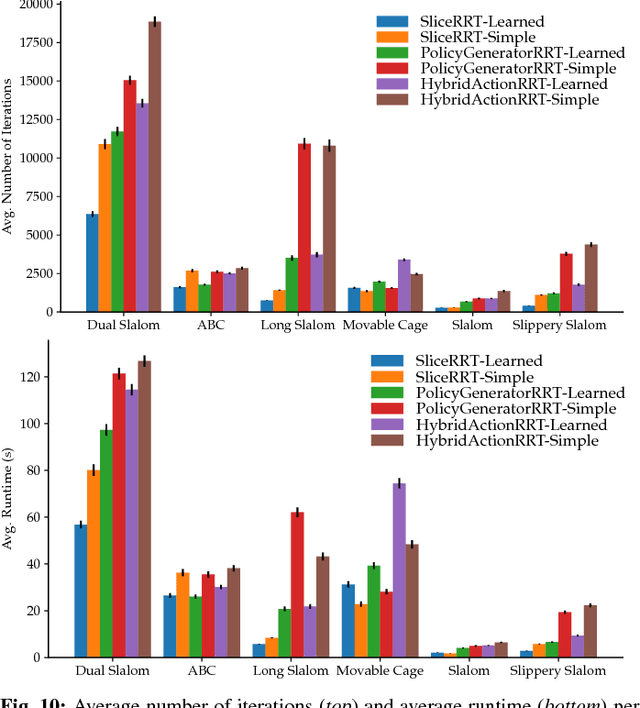
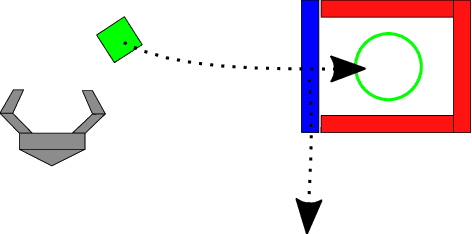
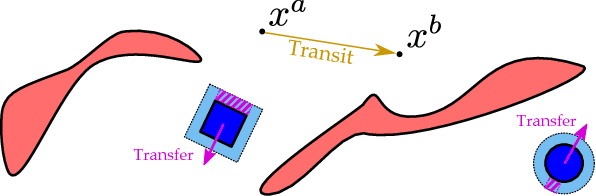
This paper addresses non-prehensile rearrangement planning problems where a robot is tasked to rearrange objects among obstacles on a planar surface. We present an efficient planning algorithm that is designed to impose few assumptions on the robot's non-prehensile manipulation abilities and is simple to adapt to different robot embodiments. For this, we combine sampling-based motion planning with reinforcement learning and generative modeling. Our algorithm explores the composite configuration space of objects and robot as a search over robot actions, forward simulated in a physics model. This search is guided by a generative model that provides robot states from which an object can be transported towards a desired state, and a learned policy that provides corresponding robot actions. As an efficient generative model, we apply Generative Adversarial Networks. We implement and evaluate our approach for robots endowed with configuration spaces in SE(2). We demonstrate empirically the efficacy of our algorithm design choices and observe more than 2x speedup in planning time on various test scenarios compared to a state-of-the-art approach.
VPE: Variational Policy Embedding for Transfer Reinforcement Learning
Sep 14, 2018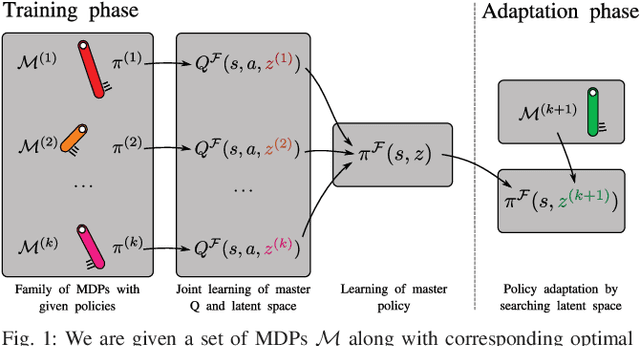

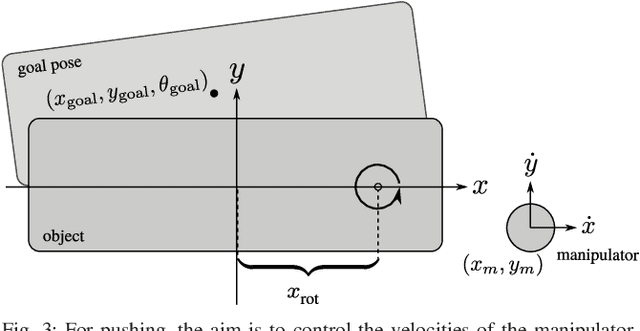

Reinforcement Learning methods are capable of solving complex problems, but resulting policies might perform poorly in environments that are even slightly different. In robotics especially, training and deployment conditions often vary and data collection is expensive, making retraining undesirable. Simulation training allows for feasible training times, but on the other hand suffers from a reality-gap when applied in real-world settings. This raises the need of efficient adaptation of policies acting in new environments. We consider this as a problem of transferring knowledge within a family of similar Markov decision processes. For this purpose we assume that Q-functions are generated by some low-dimensional latent variable. Given such a Q-function, we can find a master policy that can adapt given different values of this latent variable. Our method learns both the generative mapping and an approximate posterior of the latent variables, enabling identification of policies for new tasks by searching only in the latent space, rather than the space of all policies. The low-dimensional space, and master policy found by our method enables policies to quickly adapt to new environments. We demonstrate the method on both a pendulum swing-up task in simulation, and for simulation-to-real transfer on a pushing task.