 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Continual Learning = Catastrophic Forgetting?
Jan 18, 2021
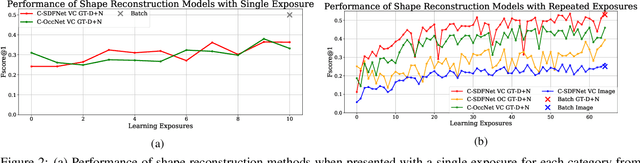
Continual learning is known for suffering from catastrophic forgetting, a phenomenon where earlier learned concepts are forgotten at the expense of more recent samples. In this work, we challenge the assumption that continual learning is inevitably associated with catastrophic forgetting by presenting a set of tasks that surprisingly do not suffer from catastrophic forgetting when learned continually. We attempt to provide an insight into the property of these tasks that make them robust to catastrophic forgetting and the potential of having a proxy representation learning task for continual classification. We further introduce a novel yet simple algorithm, YASS that outperforms state-of-the-art methods in the class-incremental categorization learning task. Finally, we present DyRT, a novel tool for tracking the dynamics of representation learning in continual models. The codebase, dataset and pre-trained models released with this article can be found at https://github.com/ngailapdi/CLRec.
Transformer-Based Neural Text Generation with Syntactic Guidance
Oct 05, 2020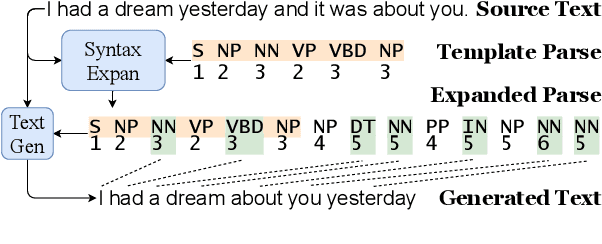
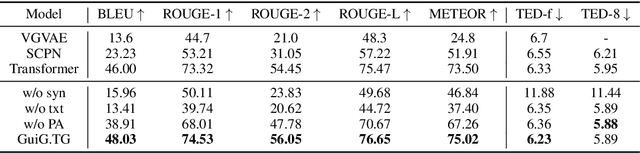
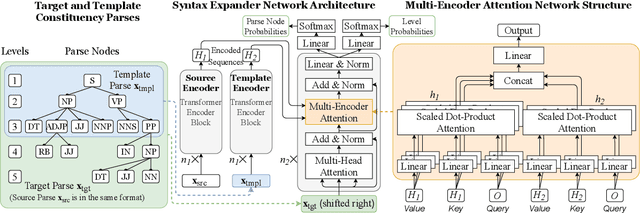
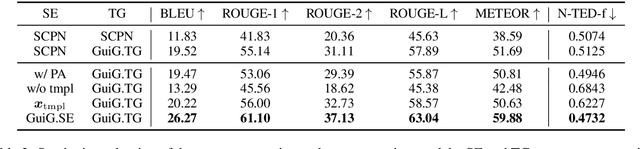
We study the problem of using (partial) constituency parse trees as syntactic guidance for controlled text generation. Existing approaches to this problem use recurrent structures, which not only suffer from the long-term dependency problem but also falls short in modeling the tree structure of the syntactic guidance. We propose to leverage the parallelism of Transformer to better incorporate parse trees. Our method first expands a partial template constituency parse tree to a full-fledged parse tree tailored for the input source text, and then uses the expanded tree to guide text generation. The effectiveness of our model in this process hinges upon two new attention mechanisms: 1) a path attention mechanism that forces one node to attend to only other nodes located in its path in the syntax tree to better incorporate syntax guidance; 2) a multi-encoder attention mechanism that allows the decoder to dynamically attend to information from multiple encoders. Our experiments in the controlled paraphrasing task show that our method outperforms SOTA models both semantically and syntactically, improving the best baseline's BLEU score from 11.83 to 26.27.