 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-related Potential driven Reinforcement Learning for adaptive Brain-Computer Interfaces
Feb 25, 2025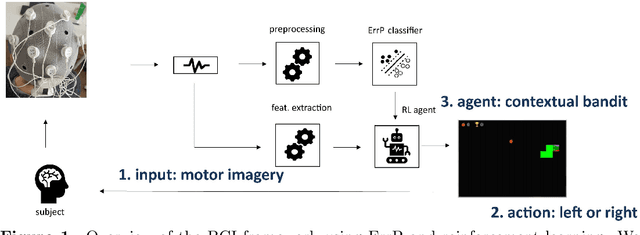
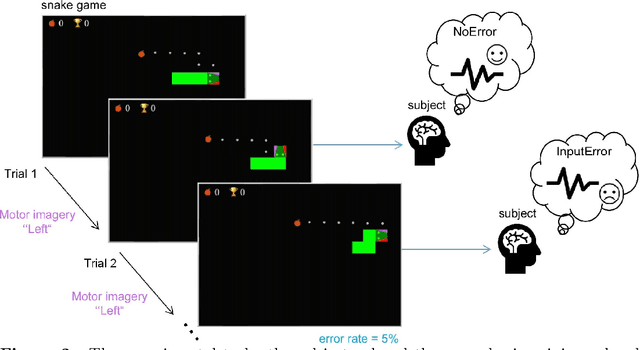
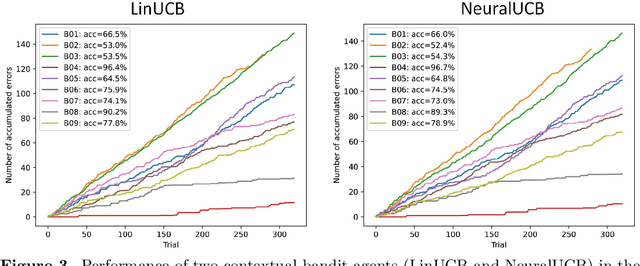
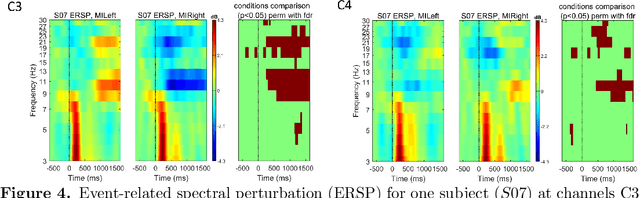
Brain-computer interfaces (BCIs) provide alternative communication methods for individuals with motor disabilities by allowing control and interaction with external devices. Non-invasive BCIs, especially those using electroencephalography (EEG), are practical and safe for various applications. However, their performance is often hindered by EEG non-stationarities, caused by changing mental states or device characteristics like electrode impedance. This challenge has spurred research into adaptive BCIs that can handle such variations. In recent years, interest has grown in using error-related potentials (ErrPs) to enhance BCI performance. ErrPs, neural responses to errors, can be detected non-invasively and have been integrated into different BCI paradigms to improve performance through error correction or adaptation. This research introduces a novel adaptive ErrP-based BCI approach using reinforcement learning (RL). We demonstrate the feasibility of an RL-driven adaptive framework incorporating ErrPs and motor imagery. Utilizing two RL agents, the framework adapts dynamically to EEG non-stationarities. Validation was conducted using a publicly available motor imagery dataset and a fast-paced game designed to boost user engagement. Results show the framework's promise, with RL agents learning control policies from user interactions and achieving robust performance across datasets. However, a critical insight from the game-based protocol revealed that motor imagery in a high-speed interaction paradigm was largely ineffective for participants, highlighting task design limitations in real-time BCI applications. These findings underscore the potential of RL for adaptive BCIs while pointing out practical constraints related to task complexity and user responsiveness.
Ruhr Hand Motion Catalog of Human Center-Out Transport Trajectories in 3D Task-Space Captured by a Redundant Measurement System
Dec 31, 2023Neurological conditions are a major source of movement disorders. Motion modelling and variability analysis have the potential to identify pathology but require profound data. We introduce a systematic dataset of 3D center-out task-space trajectories of human hand transport movements in a natural setting. The transport tasks of this study consist of grasping a cylindric object from a unified start position and transporting it to one of nine target locations in unconstrained operational space. The measurement procedure is automatized to record ten trials per target location. With that, the dataset consists of 90 movement trajectories for each hand of 31 participants without known movement disorders. The participants are aged between 21 and 78 years, covering a wide range. Data are recorded redundantly by both an optical tracking system and an IMU sensor. As opposed to the stationary capturing system, the IMU can be considered as a portable, low-cost and energy-efficient alternative to be implemented on embedded systems.
Advancements in Upper Body Exoskeleton: Implementing Active Gravity Compensation with a Feedforward Controller
Sep 09, 2023



In this study, we present a feedforward control system designed for active gravity compensation on an upper body exoskeleton. The system utilizes only positional data from internal motor sensors to calculate torque, employing analytical control equations based on Newton-Euler Inverse Dynamics. Compared to feedback control systems, the feedforward approach offers several advantages. It eliminates the need for external torque sensors, resulting in reduced hardware complexity and weight. Moreover, the feedforward control exhibits a more proactive response, leading to enhanced performance. The exoskeleton used in the experiments is lightweight and comprises 4 Degrees of Freedom, closely mimicking human upper body kinematics and three-dimensional range of motion. We conducted tests on both hardware and simulations of the exoskeleton, demonstrating stable performance. The system maintained its position over an extended period, exhibiting minimal friction and avoiding undesired slewing.
Understanding Activation Patterns in Artificial Neural Networks by Exploring Stochastic Processes
Aug 01, 2023To gain a deeper understanding of the behavior and learning dynamics of (deep) artificial neural networks, it is valuable to employ mathematical abstractions and models. These tools provide a simplified perspective on network performance and facilitate systematic investigations through simulations. In this paper, we propose utilizing the framework of stochastic processes, which has been underutilized thus far. Our approach models activation patterns of thresholded nodes in (deep) artificial neural networks as stochastic processes. We focus solely on activation frequency, leveraging neuroscience techniques used for real neuron spike trains. During a classification task, we extract spiking activity and use an arrival process following the Poisson distribution. We examine observed data from various artificial neural networks in image recognition tasks, fitting the proposed model's assumptions. Through this, we derive parameters describing activation patterns in each network. Our analysis covers randomly initialized, generalizing, and memorizing networks, revealing consistent differences across architectures and training sets. Calculating Mean Firing Rate, Mean Fano Factor, and Variances, we find stable indicators of memorization during learning, providing valuable insights into network behavior. The proposed model shows promise in describing activation patterns and could serve as a general framework for future investigations. It has potential applications in theoretical simulations, pruning, and transfer learning.
Adaptive SpikeDeep-Classifier: Self-organizing and self-supervised machine learning algorithm for online spike sorting
Mar 30, 2023



Objective. Research on brain-computer interfaces (BCIs) is advancing towards rehabilitating severely disabled patients in the real world. Two key factors for successful decoding of user intentions are the size of implanted microelectrode arrays and a good online spike sorting algorithm. A small but dense microelectrode array with 3072 channels was recently developed for decoding user intentions. The process of spike sorting determines the spike activity (SA) of different sources (neurons) from recorded neural data. Unfortunately, current spike sorting algorithms are unable to handle the massively increasing amount of data from dense microelectrode arrays, making spike sorting a fragile component of the online BCI decoding framework. Approach. We proposed an adaptive and self-organized algorithm for online spike sorting, named Adaptive SpikeDeep-Classifier (Ada-SpikeDeepClassifier), which uses SpikeDeeptector for channel selection, an adaptive background activity rejector (Ada-BAR) for discarding background events, and an adaptive spike classifier (Ada-Spike classifier) for classifying the SA of different neural units. Results. Our algorithm outperformed our previously published SpikeDeep-Classifier and eight other spike sorting algorithms, as evaluated on a human dataset and a publicly available simulated dataset. Significance. The proposed algorithm is the first spike sorting algorithm that automatically learns the abrupt changes in the distribution of noise and SA. It is an artificial neural network-based algorithm that is well-suited for hardware implementation on neuromorphic chips that can be used for wearable invasive BCIs.
Invariance to Quantile Selection in Distributional Continuous Control
Dec 29, 2022In recent years distributional reinforcement learning has produced many state of the art results. Increasingly sample efficient Distributional algorithms for the discrete action domain have been developed over time that vary primarily in the way they parameterize their approximations of value distributions, and how they quantify the differences between those distributions. In this work we transfer three of the most well-known and successful of those algorithms (QR-DQN, IQN and FQF) to the continuous action domain by extending two powerful actor-critic algorithms (TD3 and SAC) with distributional critics. We investigate whether the relative performance of the methods for the discrete action space translates to the continuous case. To that end we compare them empirically on the pybullet implementations of a set of continuous control tasks. Our results indicate qualitative invariance regarding the number and placement of distributional atoms in the deterministic, continuous action setting.
ConTraNet: A single end-to-end hybrid network for EEG-based and EMG-based human machine interfaces
Jun 21, 2022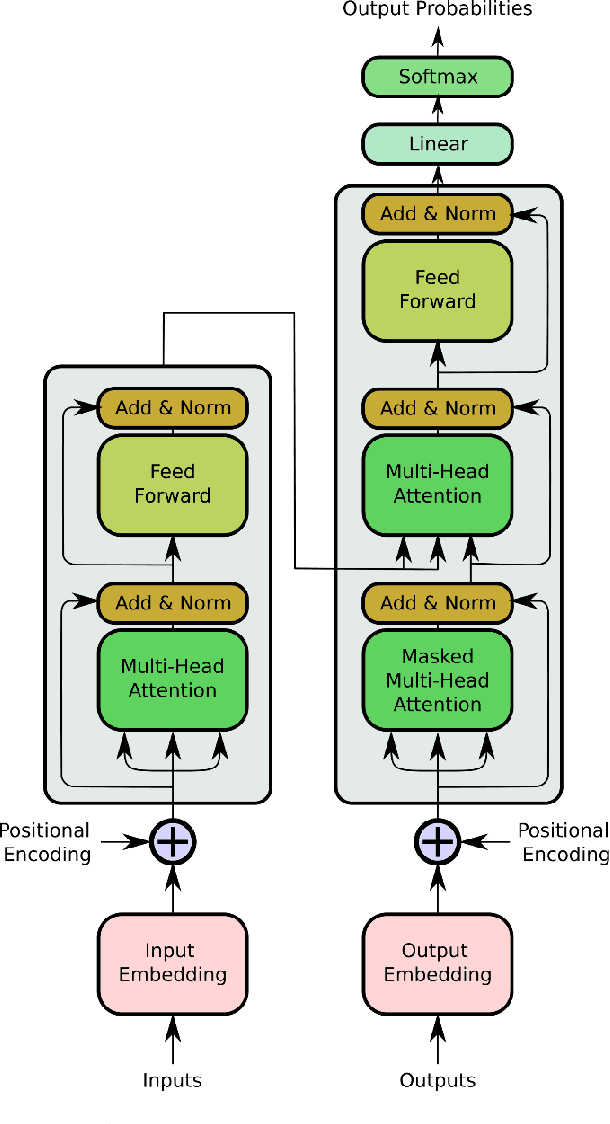

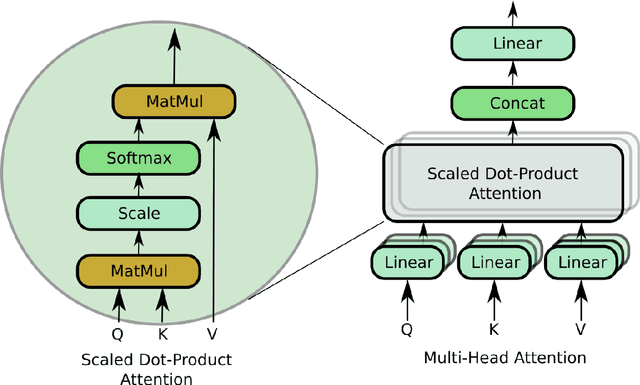
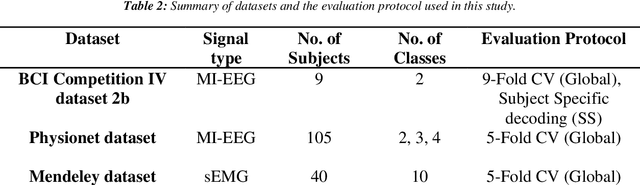
Objective: Electroencephalography (EEG) and electromyography (EMG) are two non-invasive bio-signals, which are widely used in human machine interface (HMI) technologies (EEG-HMI and EMG-HMI paradigm) for the rehabilitation of physically disabled people. Successful decoding of EEG and EMG signals into respective control command is a pivotal step in the rehabilitation process. Recently, several Convolutional neural networks (CNNs) based architectures are proposed that directly map the raw time-series signal into decision space and the process of meaningful features extraction and classification are performed simultaneously. However, these networks are tailored to the learn the expected characteristics of the given bio-signal and are limited to single paradigm. In this work, we addressed the question that can we build a single architecture which is able to learn distinct features from different HMI paradigms and still successfully classify them. Approach: In this work, we introduce a single hybrid model called ConTraNet, which is based on CNN and Transformer architectures that is equally useful for EEG-HMI and EMG-HMI paradigms. ConTraNet uses CNN block to introduce inductive bias in the model and learn local dependencies, whereas the Transformer block uses the self-attention mechanism to learn the long-range dependencies in the signal, which are crucial for the classification of EEG and EMG signals. Main results: We evaluated and compared the ConTraNet with state-of-the-art methods on three publicly available datasets which belong to EEG-HMI and EMG-HMI paradigms. ConTraNet outperformed its counterparts in all the different category tasks (2-class, 3-class, 4-class, and 10-class decoding tasks). Significance: The results suggest that ConTraNet is robust to learn distinct features from different HMI paradigms and generalizes well as compared to the current state of the art algorithms.
From Motion to Muscle
Feb 17, 2022Voluntary human motion is the product of muscle activity that results from upstream motion planning of the motor cortical areas. We show that muscle activity can be artificially generated based on motion features such as position, velocity, and acceleration. For this purpose, we specifically develop an approach based on a recurrent neural network trained in a supervised learning session; additional neural network architectures are considered and evaluated. The performance is evaluated by a new score called the zero-line score. The latter adaptively rescales the loss function of the generated signal for all channels by comparing the overall range of muscle activity and thus dynamically evaluates similarities between both signals. The model achieves a remarkable precision for previously trained motion while new motions that were not trained before still have high accuracy. Further, these models are trained on multiple subjects and thus are able to generalize across individuals. In addition, we distinguish between a general model that has been trained on several subjects, a subject-specific model, and a specific pre-trained model that uses the general model as a basis and is adapted to a specific subject afterward. The subject-specific generation of muscle activity can be further exploited to improve the rehabilitation of neuromuscular diseases with myoelectric prostheses and functional electric stimulation.
Deep Transfer-Learning for patient specific model re-calibration: Application to sEMG-Classification
Dec 30, 2021
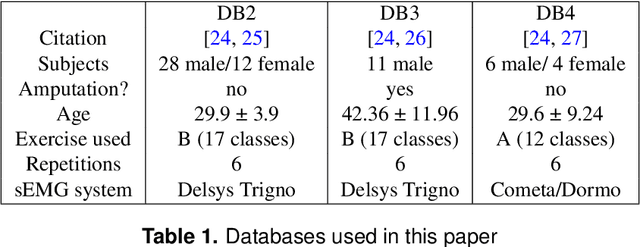


Accurate decoding of surface electromyography (sEMG) is pivotal for muscle-to-machine-interfaces (MMI) and their application for e.g. rehabilitation therapy. sEMG signals have high inter-subject variability, due to various factors, including skin thickness, body fat percentage, and electrode placement. Therefore, obtaining high generalization quality of a trained sEMG decoder is quite challenging. Usually, machine learning based sEMG decoders are either trained on subject-specific data, or at least recalibrated for each user, individually. Even though, deep learning algorithms produced several state of the art results for sEMG decoding,however, due to the limited amount of availability of sEMG data, the deep learning models are prone to overfitting. Recently, transfer learning for domain adaptation improved generalization quality with reduced training time on various machine learning tasks. In this study, we investigate the effectiveness of transfer learning using weight initialization for recalibration of two different pretrained deep learning models on a new subjects data, and compare their performance to subject-specific models. To the best of our knowledge, this is the first study that thoroughly investigated weight-initialization based transfer learning for sEMG classification and compared transfer learning to subject-specific modeling. We tested our models on three publicly available databases under various settings. On average over all settings, our transfer learning approach improves 5~\%-points on the pretrained models without fine-tuning and 12~\%-points on the subject-specific models, while being trained on average 22~\% fewer epochs. Our results indicate that transfer learning enables faster training on fewer samples than user-specific models, and improves the performance of pretrained models as long as enough data is available.
Biologically Inspired Model for Timed Motion in Robotic Systems
Jul 29, 2021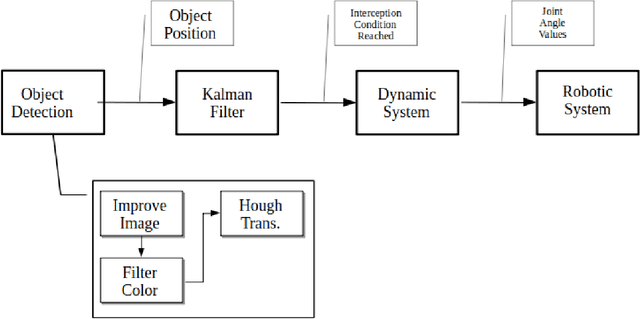

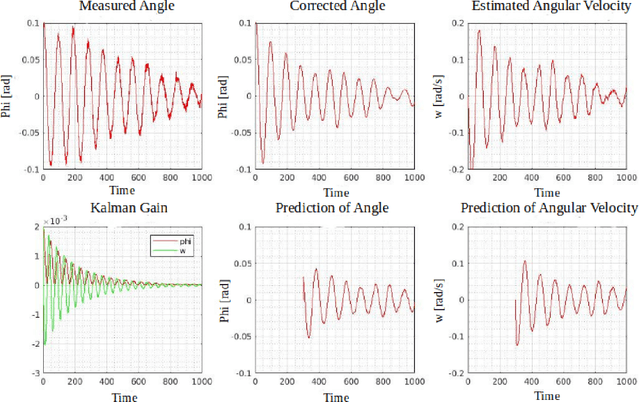

The goal of this work is the development of a motion model for sequentially timed movement actions in robotic systems under specific consideration of temporal stabilization, that is maintaining an approximately constant overall movement time (isochronous behavior). This is demonstrated both in simulation and on a physical robotic system for the task of intercepting a moving target in three-dimensional space. Motivated from humanoid motion, timing plays a vital role to generate a naturalistic behavior in interaction with the dynamic environment as well as adaptively planning and executing action sequences on-line. In biological systems, many of the physiological and anatomical functions follow a particular level of periodicity and stabilization, which exhibit a certain extent of resilience against external disturbances. A main aspect thereof is stabilizing movement timing against limited perturbations. Especially human arm movement, namely when it is tasked to reach a certain goal point, pose or configuration, shows a stabilizing behavior. This work incorporates the utilization of an extended Kalman filter (EKF) which was implemented to predict the target position while coping with non-linear system dynamics. The periodicity and temporal stabilization in biological systems was artificially generated by a Hopf oscillator, yielding a sinusoidal velocity profile for smooth and repeatable motion.