 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Transfer Learning for Javanese Dependency Parsing
Jan 22, 2024

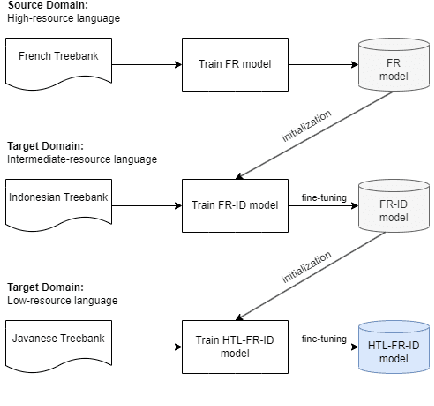

While structure learning achieves remarkable performance in high-resource languages, the situation differs for under-represented languages due to the scarcity of annotated data. This study focuses on assessing the efficacy of transfer learning in enhancing dependency parsing for Javanese, a language spoken by 80 million individuals but characterized by limited representation in natural language processing. We utilized the Universal Dependencies dataset consisting of dependency treebanks from more than 100 languages, including Javanese. We propose two learning strategies to train the model: transfer learning (TL) and hierarchical transfer learning (HTL). While TL only uses a source language to pre-train the model, the HTL method uses a source language and an intermediate language in the learning process. The results show that our best model uses the HTL method, which improves performance with an increase of 10% for both UAS and LAS evaluations compared to the baseline model.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.