 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 9: Detecting Multilingual, Multicultural and Multievent Online Polarization
Apr 08, 2026We present SemEval-2026 Task 9, a shared task on online polarization detection, covering 22 languages and comprising over 110K annotated instances. Each data instance is multi-labeled with the presence of polarization, polarization type, and polarization manifestation. Participants were asked to predict labels in three sub-tasks: (1) detecting the presence of polarization, (2) identifying the type of polarization, and (3) recognizing the polarization manifestation. The three tasks attracted over 1,000 participants worldwide and more than 10k submission on Codabench. We received final submissions from 67 teams and 73 system description papers. We report the baseline results and analyze the performance of the best-performing systems, highlighting the most common approaches and the most effective methods across different subtasks and languages. The dataset of this task is publicly available.
TweakLLM: A Routing Architecture for Dynamic Tailoring of Cached Responses
Jul 31, 2025Large Language Models (LLMs) process millions of queries daily, making efficient response caching a compelling optimization for reducing cost and latency. However, preserving relevance to user queries using this approach proves difficult due to the personalized nature of chatbot interactions and the limited accuracy of semantic similarity search. To address this, we present TweakLLM, a novel routing architecture that employs a lightweight LLM to dynamically adapt cached responses to incoming prompts. Through comprehensive evaluation, including user studies with side-by-side comparisons, satisfaction voting, as well as multi-agent LLM debates, we demonstrate that TweakLLM maintains response quality comparable to frontier models while significantly improving cache effectiveness. Our results across real-world datasets highlight TweakLLM as a scalable, resource-efficient caching solution for high-volume LLM deployments without compromising user experience.
Language Model-Driven Data Pruning Enables Efficient Active Learning
Oct 05, 2024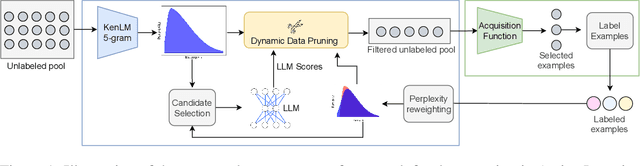
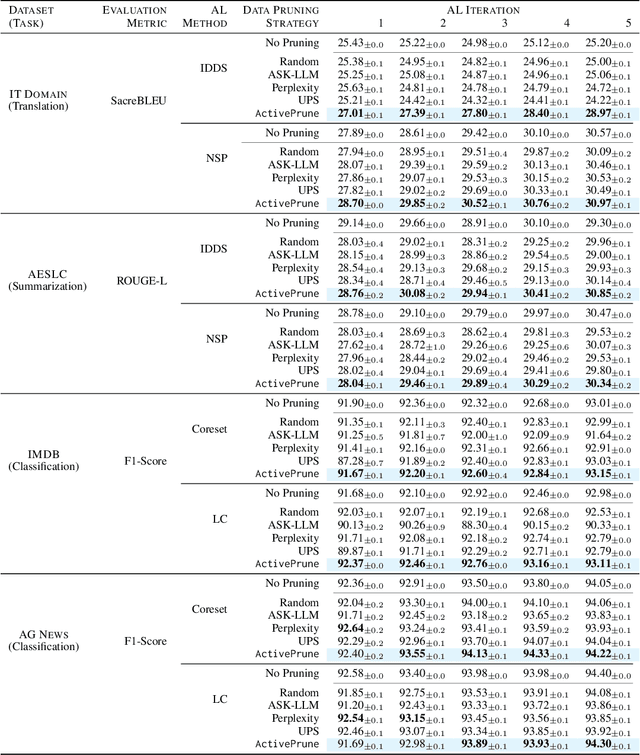


Active learning (AL) optimizes data labeling efficiency by selecting the most informative instances for annotation. A key component in this procedure is an acquisition function that guides the selection process and identifies the suitable instances for labeling from the unlabeled pool. However, these acquisition methods suffer from high computational costs with large unlabeled data pools, posing a roadblock to their applicability on large datasets. To address this challenge and bridge this gap, we introduce a novel plug-and-play unlabeled data pruning strategy, ActivePrune, which leverages language models to prune the unlabeled pool. ActivePrune implements a two-stage pruning process: an initial fast evaluation using perplexity scores from an n-gram language model, followed by a high-quality selection using metrics for data quality computed through a quantized LLM. Additionally, to enhance the diversity in the unlabeled pool, we propose a novel perplexity reweighting method that systematically brings forward underrepresented instances for selection in subsequent labeling iterations. Experiments on translation, sentiment analysis, topic classification, and summarization tasks on four diverse datasets and four active learning strategies demonstrate that ActivePrune outperforms existing data pruning methods. Finally, we compare the selection quality $\leftrightarrow$ efficiency tradeoff of the data pruning methods and demonstrate that ActivePrune is computationally more efficient than other LLM score-based pruning methods, and provides up to 74% reduction in the end-to-end time required for active learning.
Rethinking Image Compression on the Web with Generative AI
Jul 05, 2024



The rapid growth of the Internet, driven by social media, web browsing, and video streaming, has made images central to the Web experience, resulting in significant data transfer and increased webpage sizes. Traditional image compression methods, while reducing bandwidth, often degrade image quality. This paper explores a novel approach using generative AI to reconstruct images at the edge or client-side. We develop a framework that leverages text prompts and provides additional conditioning inputs like Canny edges and color palettes to a text-to-image model, achieving up to 99.8% bandwidth savings in the best cases and 92.6% on average, while maintaining high perceptual similarity. Empirical analysis and a user study show that our method preserves image meaning and structure more effectively than traditional compression methods, offering a promising solution for reducing bandwidth usage and improving Internet affordability with minimal degradation in image quality.
To Label or Not to Label: Hybrid Active Learning for Neural Machine Translation
Mar 14, 2024



Active learning (AL) techniques reduce labeling costs for training neural machine translation (NMT) models by selecting smaller representative subsets from unlabeled data for annotation. Diversity sampling techniques select heterogeneous instances, while uncertainty sampling methods select instances with the highest model uncertainty. Both approaches have limitations - diversity methods may extract varied but trivial examples, while uncertainty sampling can yield repetitive, uninformative instances. To bridge this gap, we propose HUDS, a hybrid AL strategy for domain adaptation in NMT that combines uncertainty and diversity for sentence selection. HUDS computes uncertainty scores for unlabeled sentences and subsequently stratifies them. It then clusters sentence embeddings within each stratum using k-MEANS and computes diversity scores by distance to the centroid. A weighted hybrid score that combines uncertainty and diversity is then used to select the top instances for annotation in each AL iteration. Experiments on multi-domain German-English datasets demonstrate the better performance of HUDS over other strong AL baselines. We analyze the sentence selection with HUDS and show that it prioritizes diverse instances having high model uncertainty for annotation in early AL iterations.
Towards Representative Subset Selection for Self-Supervised Speech Recognition
Mar 18, 2022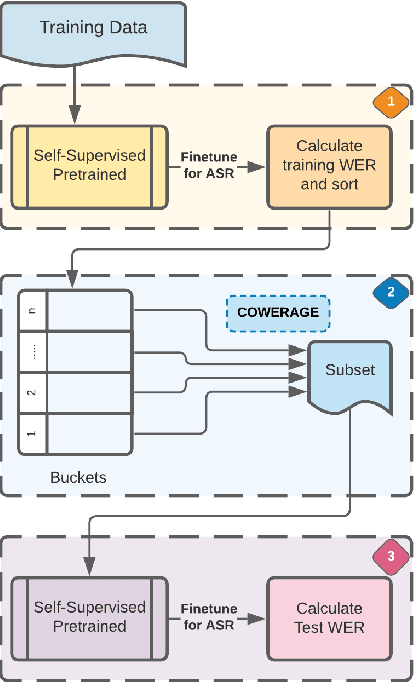
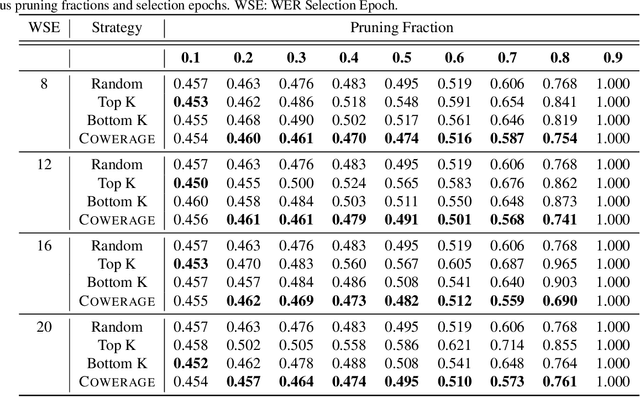
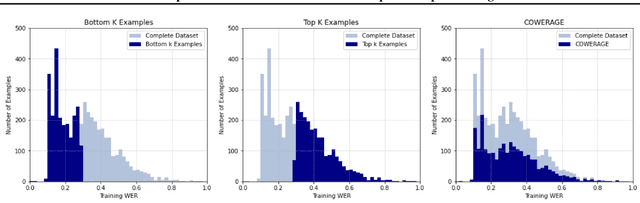

Self-supervised speech recognition models require considerable labeled training data for learning high-fidelity representations for Automatic Speech Recognition (ASR), which hinders their application to low-resource languages. We consider the task of identifying an optimal subset of training data to fine-tune self-supervised speech models for ASR. We make a surprising observation that active learning strategies for sampling harder-to-learn examples do not perform better than random subset selection for fine-tuning self-supervised ASR. We then present the COWERAGE algorithm for better subset selection in self-supervised ASR which is based on our finding that ensuring the coverage of examples based on training WER in the early training epochs leads to better generalization performance. Extensive experiments on the wav2vec 2.0 model and TIMIT dataset show the effectiveness of COWERAGE, with up to 27% absolute WER improvement over active learning methods. We also report the connection between training WER and the phonemic cover and demonstrate that our algorithm ensures inclusion of phonemically diverse examples.
FedPrune: Towards Inclusive Federated Learning
Oct 27, 2021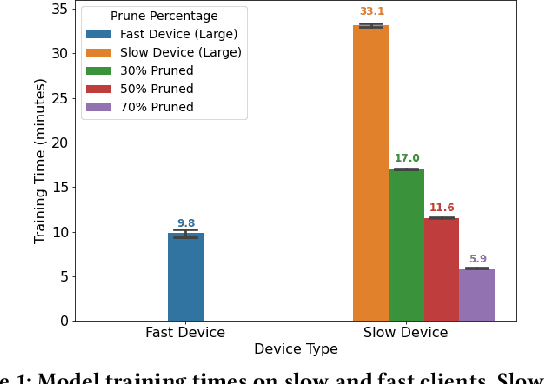
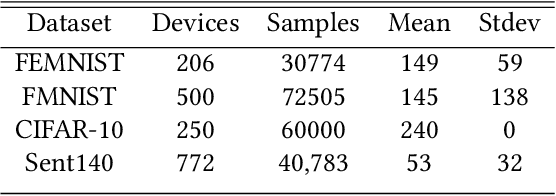
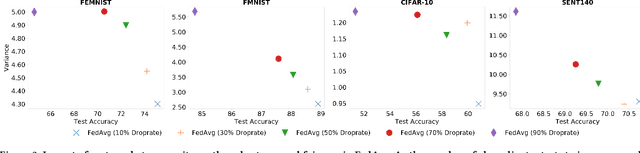
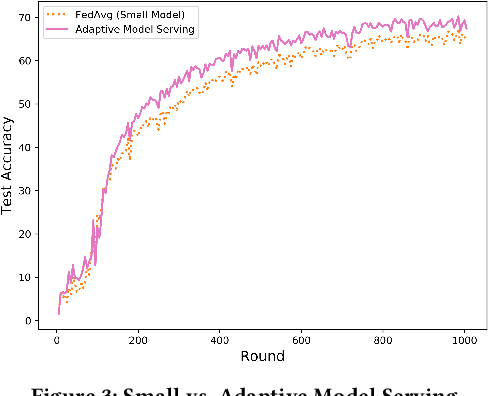
Federated learning (FL) is a distributed learning technique that trains a shared model over distributed data in a privacy-preserving manner. Unfortunately, FL's performance degrades when there is (i) variability in client characteristics in terms of computational and memory resources (system heterogeneity) and (ii) non-IID data distribution across clients (statistical heterogeneity). For example, slow clients get dropped in FL schemes, such as Federated Averaging (FedAvg), which not only limits overall learning but also biases results towards fast clients. We propose FedPrune; a system that tackles this challenge by pruning the global model for slow clients based on their device characteristics. By doing so, slow clients can train a small model quickly and participate in FL which increases test accuracy as well as fairness. By using insights from Central Limit Theorem, FedPrune incorporates a new aggregation technique that achieves robust performance over non-IID data. Experimental evaluation shows that Fed- Prune provides robust convergence and better fairness compared to Federated Averaging.