 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model-Driven Data Pruning Enables Efficient Active Learning
Paper and Code
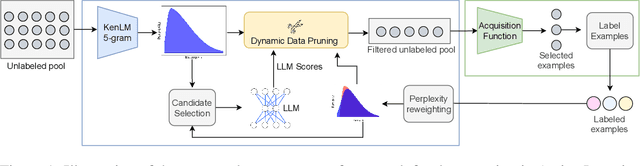
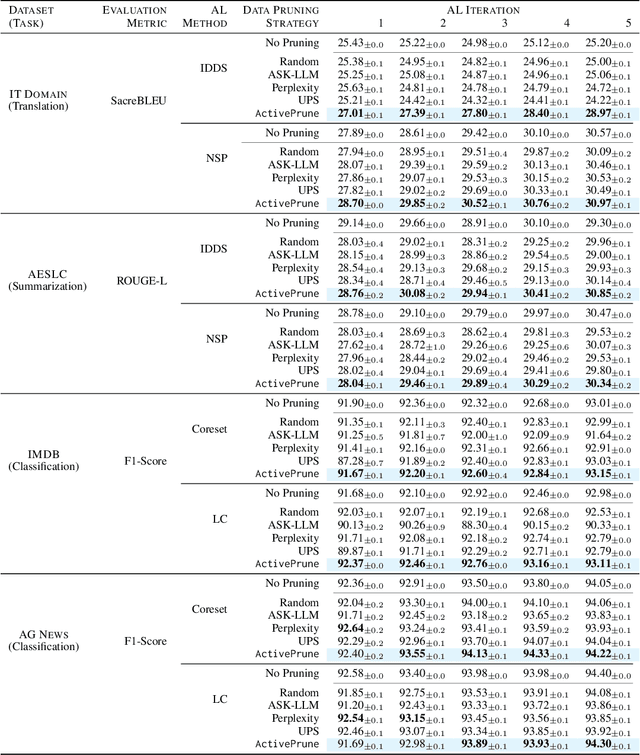


Active learning (AL) optimizes data labeling efficiency by selecting the most informative instances for annotation. A key component in this procedure is an acquisition function that guides the selection process and identifies the suitable instances for labeling from the unlabeled pool. However, these acquisition methods suffer from high computational costs with large unlabeled data pools, posing a roadblock to their applicability on large datasets. To address this challenge and bridge this gap, we introduce a novel plug-and-play unlabeled data pruning strategy, ActivePrune, which leverages language models to prune the unlabeled pool. ActivePrune implements a two-stage pruning process: an initial fast evaluation using perplexity scores from an n-gram language model, followed by a high-quality selection using metrics for data quality computed through a quantized LLM. Additionally, to enhance the diversity in the unlabeled pool, we propose a novel perplexity reweighting method that systematically brings forward underrepresented instances for selection in subsequent labeling iterations. Experiments on translation, sentiment analysis, topic classification, and summarization tasks on four diverse datasets and four active learning strategies demonstrate that ActivePrune outperforms existing data pruning methods. Finally, we compare the selection quality $\leftrightarrow$ efficiency tradeoff of the data pruning methods and demonstrate that ActivePrune is computationally more efficient than other LLM score-based pruning methods, and provides up to 74% reduction in the end-to-end time required for active learning.