 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model-Driven Data Pruning Enables Efficient Active Learning
Oct 05, 2024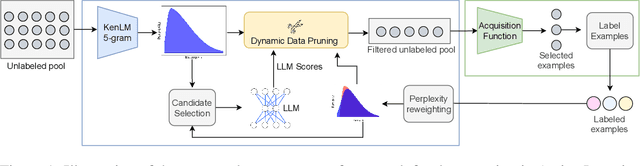
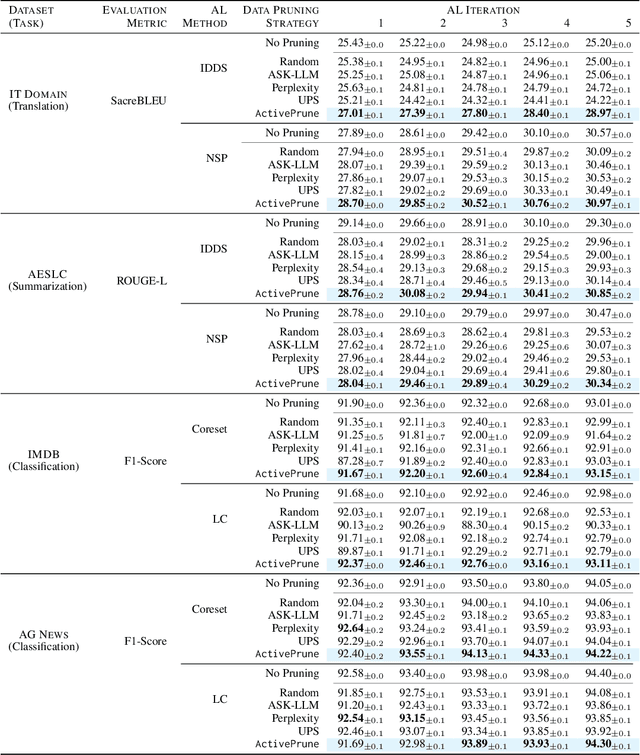


Active learning (AL) optimizes data labeling efficiency by selecting the most informative instances for annotation. A key component in this procedure is an acquisition function that guides the selection process and identifies the suitable instances for labeling from the unlabeled pool. However, these acquisition methods suffer from high computational costs with large unlabeled data pools, posing a roadblock to their applicability on large datasets. To address this challenge and bridge this gap, we introduce a novel plug-and-play unlabeled data pruning strategy, ActivePrune, which leverages language models to prune the unlabeled pool. ActivePrune implements a two-stage pruning process: an initial fast evaluation using perplexity scores from an n-gram language model, followed by a high-quality selection using metrics for data quality computed through a quantized LLM. Additionally, to enhance the diversity in the unlabeled pool, we propose a novel perplexity reweighting method that systematically brings forward underrepresented instances for selection in subsequent labeling iterations. Experiments on translation, sentiment analysis, topic classification, and summarization tasks on four diverse datasets and four active learning strategies demonstrate that ActivePrune outperforms existing data pruning methods. Finally, we compare the selection quality $\leftrightarrow$ efficiency tradeoff of the data pruning methods and demonstrate that ActivePrune is computationally more efficient than other LLM score-based pruning methods, and provides up to 74% reduction in the end-to-end time required for active learning.
The Fellowship of the LLMs: Multi-Agent Workflows for Synthetic Preference Optimization Dataset Generation
Aug 16, 2024



This paper presents and evaluates multi-agent workflows for synthetic Preference Optimization (PO) dataset generation. PO dataset generation requires two modules: (1) response evaluation, and (2) response generation. In the response evaluation module, the responses from Large Language Models (LLMs) are evaluated and ranked - a task typically carried out by human annotators that we automate using LLMs. We assess the response evaluation module in a 2 step process. In step 1, we assess LLMs as evaluators using three distinct prompting strategies. In step 2, we apply the winning prompting strategy to compare the performance of LLM-as-a-Judge, LLMs-as-a-Jury, and LLM Debate. In each step, we use inter-rater agreement using Cohen's Kappa between human annotators and LLMs. For the response generation module, we compare different configurations for the LLM Feedback Loop using the identified LLM evaluator configuration. We use the win rate (the fraction of times a generation framework is selected as the best by an LLM evaluator) to determine the best multi-agent configuration for generation. After identifying the best configurations for both modules, we use models from the GPT, Gemma, and Llama families to generate our PO datasets using the above pipeline. We generate two types of PO datasets, one to improve the generation capabilities of individual LLM and the other to improve the multi-agent workflow. Our evaluation shows that GPT-4o-as-a-Judge is more consistent across datasets when the candidate responses do not include responses from the GPT family. Additionally, we find that the LLM Feedback Loop, with Llama as the generator and Gemma as the reviewer, achieves a notable 71.8% and 73.8% win rate over single-agent Llama and Gemma, respectively.
Generalists vs. Specialists: Evaluating Large Language Models for Urdu
Jul 05, 2024



In this paper, we compare general-purpose pretrained models, GPT-4-Turbo and Llama-3-8b-Instruct with special-purpose models fine-tuned on specific tasks, XLM-Roberta-large, mT5-large, and Llama-3-8b-Instruct. We focus on seven classification and six generation tasks to evaluate the performance of these models on Urdu language. Urdu has 70 million native speakers, yet it remains underrepresented in Natural Language Processing (NLP). Despite the frequent advancements in Large Language Models (LLMs), their performance in low-resource languages, including Urdu, still needs to be explored. We also conduct a human evaluation for the generation tasks and compare the results with the evaluations performed by GPT-4-Turbo and Llama-3-8b-Instruct. We find that special-purpose models consistently outperform general-purpose models across various tasks. We also find that the evaluation done by GPT-4-Turbo for generation tasks aligns more closely with human evaluation compared to the evaluation by Llama-3-8b-Instruct. This paper contributes to the NLP community by providing insights into the effectiveness of general and specific-purpose LLMs for low-resource languages.
To Label or Not to Label: Hybrid Active Learning for Neural Machine Translation
Mar 14, 2024



Active learning (AL) techniques reduce labeling costs for training neural machine translation (NMT) models by selecting smaller representative subsets from unlabeled data for annotation. Diversity sampling techniques select heterogeneous instances, while uncertainty sampling methods select instances with the highest model uncertainty. Both approaches have limitations - diversity methods may extract varied but trivial examples, while uncertainty sampling can yield repetitive, uninformative instances. To bridge this gap, we propose HUDS, a hybrid AL strategy for domain adaptation in NMT that combines uncertainty and diversity for sentence selection. HUDS computes uncertainty scores for unlabeled sentences and subsequently stratifies them. It then clusters sentence embeddings within each stratum using k-MEANS and computes diversity scores by distance to the centroid. A weighted hybrid score that combines uncertainty and diversity is then used to select the top instances for annotation in each AL iteration. Experiments on multi-domain German-English datasets demonstrate the better performance of HUDS over other strong AL baselines. We analyze the sentence selection with HUDS and show that it prioritizes diverse instances having high model uncertainty for annotation in early AL iterations.
Towards Representative Subset Selection for Self-Supervised Speech Recognition
Mar 18, 2022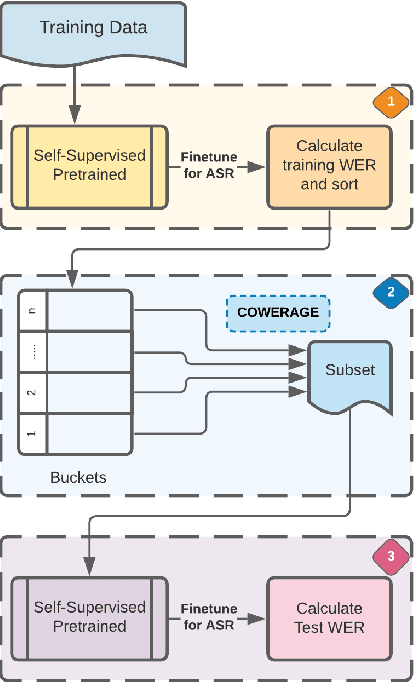
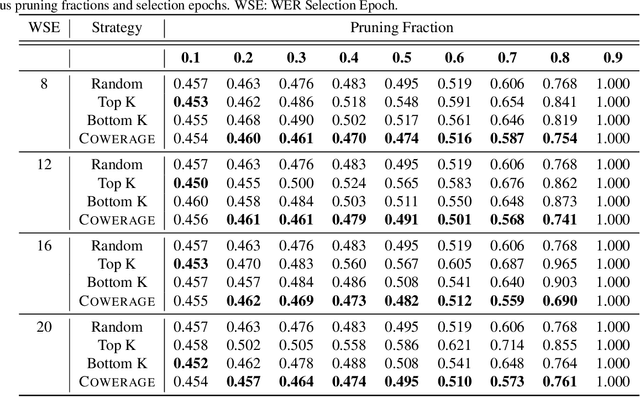
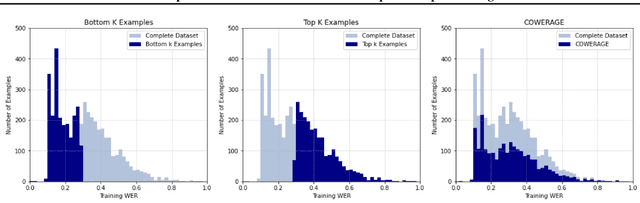

Self-supervised speech recognition models require considerable labeled training data for learning high-fidelity representations for Automatic Speech Recognition (ASR), which hinders their application to low-resource languages. We consider the task of identifying an optimal subset of training data to fine-tune self-supervised speech models for ASR. We make a surprising observation that active learning strategies for sampling harder-to-learn examples do not perform better than random subset selection for fine-tuning self-supervised ASR. We then present the COWERAGE algorithm for better subset selection in self-supervised ASR which is based on our finding that ensuring the coverage of examples based on training WER in the early training epochs leads to better generalization performance. Extensive experiments on the wav2vec 2.0 model and TIMIT dataset show the effectiveness of COWERAGE, with up to 27% absolute WER improvement over active learning methods. We also report the connection between training WER and the phonemic cover and demonstrate that our algorithm ensures inclusion of phonemically diverse examples.
RevDet: Robust and Memory Efficient Event Detection and Tracking in Large News Feeds
Mar 07, 2021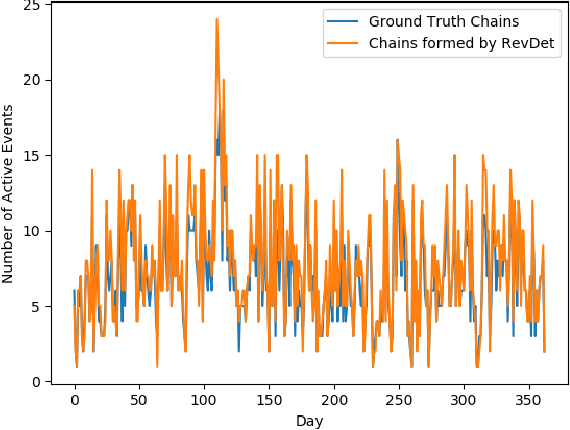
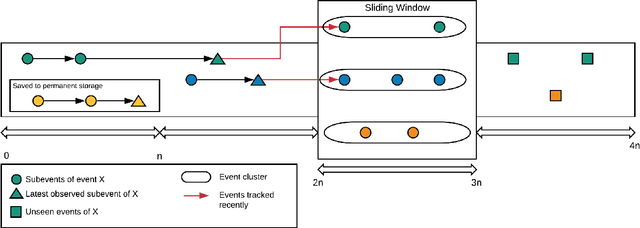

With the ever-growing volume of online news feeds, event-based organization of news articles has many practical applications including better information navigation and the ability to view and analyze events as they develop. Automatically tracking the evolution of events in large news corpora still remains a challenging task, and the existing techniques for Event Detection and Tracking do not place a particular focus on tracking events in very large and constantly updating news feeds. Here, we propose a new method for robust and efficient event detection and tracking, which we call RevDet algorithm. RevDet adopts an iterative clustering approach for tracking events. Even though many events continue to develop for many days or even months, RevDet is able to detect and track those events while utilizing only a constant amount of space on main memory. We also devise a redundancy removal strategy which effectively eliminates duplicate news articles and substantially reduces the size of data. We construct a large, comprehensive new ground truth dataset specifically for event detection and tracking approaches by augmenting two existing datasets: w2e and GDELT. We implement RevDet algorithm and evaluate its performance on the ground truth event chains. We discover that our algorithm is able to accurately recover event chains in the ground-truth dataset. We also compare the memory efficiency of our algorithm with the standard single pass clustering approach, and demonstrate the appropriateness of our algorithm for event detection and tracking task in large news feeds.
COVID-19 Tweets Analysis through Transformer Language Models
Feb 27, 2021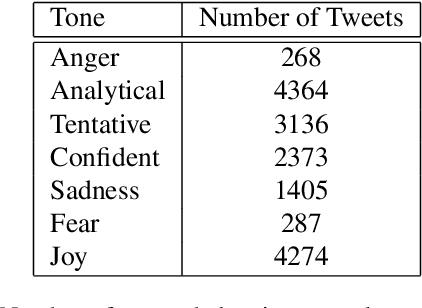
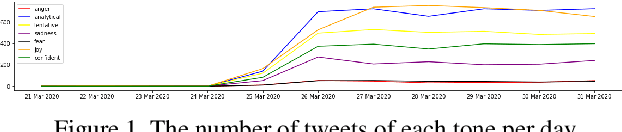
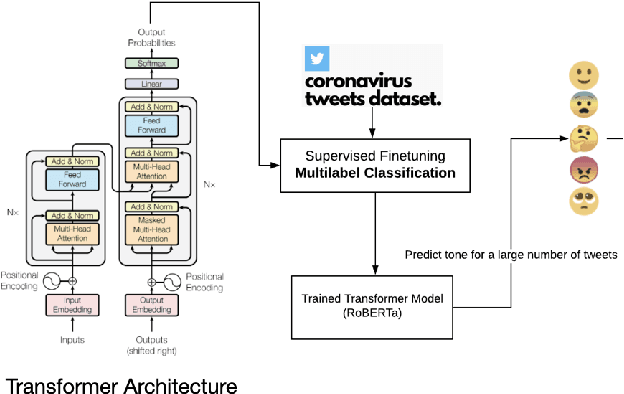
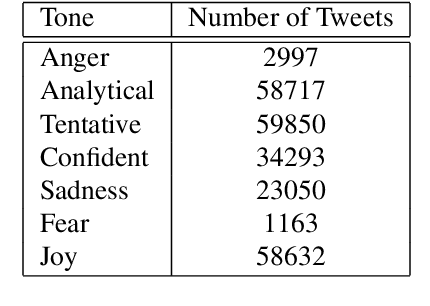
Understanding the public sentiment and perception in a healthcare crisis is essential for developing appropriate crisis management techniques. While some studies have used Twitter data for predictive modelling during COVID-19, fine-grained sentiment analysis of the opinion of people on social media during this pandemic has not yet been done. In this study, we perform an in-depth, fine-grained sentiment analysis of tweets in COVID-19. For this purpose, we perform supervised training of four transformer language models on the downstream task of multi-label classification of tweets into seven tone classes: [confident, anger, fear, joy, sadness, analytical, tentative]. We achieve a LRAP (Label Ranking Average Precision) score of 0.9267 through RoBERTa. This trained transformer model is able to correctly predict, with high accuracy, the tone of a tweet. We then leverage this model for predicting tones for 200,000 tweets on COVID-19. We then perform a country-wise analysis of the tone of tweets, and extract useful indicators of the psychological condition about the people in this pandemic.