 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Pixel Tells a Story: End-to-End Urdu Newspaper OCR
May 20, 2025This paper introduces a comprehensive end-to-end pipeline for Optical Character Recognition (OCR) on Urdu newspapers. In our approach, we address the unique challenges of complex multi-column layouts, low-resolution archival scans, and diverse font styles. Our process decomposes the OCR task into four key modules: (1) article segmentation, (2) image super-resolution, (3) column segmentation, and (4) text recognition. For article segmentation, we fine-tune and evaluate YOLOv11x to identify and separate individual articles from cluttered layouts. Our model achieves a precision of 0.963 and mAP@50 of 0.975. For super-resolution, we fine-tune and benchmark the SwinIR model (reaching 32.71 dB PSNR) to enhance the quality of degraded newspaper scans. To do our column segmentation, we use YOLOv11x to separate columns in text to further enhance performance - this model reaches a precision of 0.970 and mAP@50 of 0.975. In the text recognition stage, we benchmark a range of LLMs from different families, including Gemini, GPT, Llama, and Claude. The lowest WER of 0.133 is achieved by Gemini-2.5-Pro.
With a Grain of SALT: Are LLMs Fair Across Social Dimensions?
Oct 16, 2024

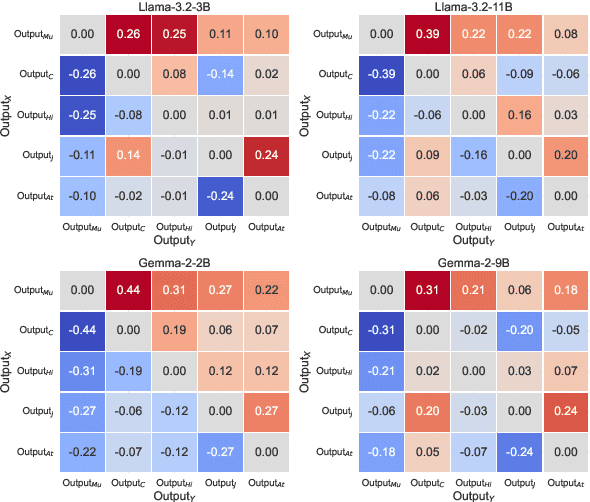
This paper presents an analysis of biases in open-source Large Language Models (LLMs) across various genders, religions, and races. We introduce a methodology for generating a bias detection dataset using seven bias triggers: General Debate, Positioned Debate, Career Advice, Story Generation, Problem-Solving, Cover-Letter Writing, and CV Generation. We use GPT-4o to generate a diverse set of prompts for each trigger across various genders, religious and racial groups. We evaluate models from Llama and Gemma family on the generated dataset. We anonymise the LLM-generated text associated with each group using GPT-4o-mini and do a pairwise comparison using GPT-4o-as-a-Judge. To quantify bias in the LLM-generated text we use the number of wins and losses in the pairwise comparison. Our analysis spans three languages, English, German, and Arabic to explore how language influences bias manifestation. Our findings reveal that LLMs exhibit strong polarization toward certain groups across each category, with a notable consistency observed across models. However, when switching languages, variations and anomalies emerge, often attributable to cultural cues and contextual differences.
The Art of Storytelling: Multi-Agent Generative AI for Dynamic Multimodal Narratives
Sep 19, 2024This paper introduces the concept of an education tool that utilizes Generative Artificial Intelligence (GenAI) to enhance storytelling for children. The system combines GenAI-driven narrative co-creation, text-to-speech conversion, and text-to-video generation to produce an engaging experience for learners. We describe the co-creation process, the adaptation of narratives into spoken words using text-to-speech models, and the transformation of these narratives into contextually relevant visuals through text-to-video technology. Our evaluation covers the linguistics of the generated stories, the text-to-speech conversion quality, and the accuracy of the generated visuals.
WER We Stand: Benchmarking Urdu ASR Models
Sep 17, 2024This paper presents a comprehensive evaluation of Urdu Automatic Speech Recognition (ASR) models. We analyze the performance of three ASR model families: Whisper, MMS, and Seamless-M4T using Word Error Rate (WER), along with a detailed examination of the most frequent wrong words and error types including insertions, deletions, and substitutions. Our analysis is conducted using two types of datasets, read speech and conversational speech. Notably, we present the first conversational speech dataset designed for benchmarking Urdu ASR models. We find that seamless-large outperforms other ASR models on the read speech dataset, while whisper-large performs best on the conversational speech dataset. Furthermore, this evaluation highlights the complexities of assessing ASR models for low-resource languages like Urdu using quantitative metrics alone and emphasizes the need for a robust Urdu text normalization system. Our findings contribute valuable insights for developing robust ASR systems for low-resource languages like Urdu.
The Fellowship of the LLMs: Multi-Agent Workflows for Synthetic Preference Optimization Dataset Generation
Aug 16, 2024



This paper presents and evaluates multi-agent workflows for synthetic Preference Optimization (PO) dataset generation. PO dataset generation requires two modules: (1) response evaluation, and (2) response generation. In the response evaluation module, the responses from Large Language Models (LLMs) are evaluated and ranked - a task typically carried out by human annotators that we automate using LLMs. We assess the response evaluation module in a 2 step process. In step 1, we assess LLMs as evaluators using three distinct prompting strategies. In step 2, we apply the winning prompting strategy to compare the performance of LLM-as-a-Judge, LLMs-as-a-Jury, and LLM Debate. In each step, we use inter-rater agreement using Cohen's Kappa between human annotators and LLMs. For the response generation module, we compare different configurations for the LLM Feedback Loop using the identified LLM evaluator configuration. We use the win rate (the fraction of times a generation framework is selected as the best by an LLM evaluator) to determine the best multi-agent configuration for generation. After identifying the best configurations for both modules, we use models from the GPT, Gemma, and Llama families to generate our PO datasets using the above pipeline. We generate two types of PO datasets, one to improve the generation capabilities of individual LLM and the other to improve the multi-agent workflow. Our evaluation shows that GPT-4o-as-a-Judge is more consistent across datasets when the candidate responses do not include responses from the GPT family. Additionally, we find that the LLM Feedback Loop, with Llama as the generator and Gemma as the reviewer, achieves a notable 71.8% and 73.8% win rate over single-agent Llama and Gemma, respectively.
Generalists vs. Specialists: Evaluating Large Language Models for Urdu
Jul 05, 2024



In this paper, we compare general-purpose pretrained models, GPT-4-Turbo and Llama-3-8b-Instruct with special-purpose models fine-tuned on specific tasks, XLM-Roberta-large, mT5-large, and Llama-3-8b-Instruct. We focus on seven classification and six generation tasks to evaluate the performance of these models on Urdu language. Urdu has 70 million native speakers, yet it remains underrepresented in Natural Language Processing (NLP). Despite the frequent advancements in Large Language Models (LLMs), their performance in low-resource languages, including Urdu, still needs to be explored. We also conduct a human evaluation for the generation tasks and compare the results with the evaluations performed by GPT-4-Turbo and Llama-3-8b-Instruct. We find that special-purpose models consistently outperform general-purpose models across various tasks. We also find that the evaluation done by GPT-4-Turbo for generation tasks aligns more closely with human evaluation compared to the evaluation by Llama-3-8b-Instruct. This paper contributes to the NLP community by providing insights into the effectiveness of general and specific-purpose LLMs for low-resource languages.
UQA: Corpus for Urdu Question Answering
May 02, 2024This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.