 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Representative Subset Selection for Self-Supervised Speech Recognition
Paper and Code
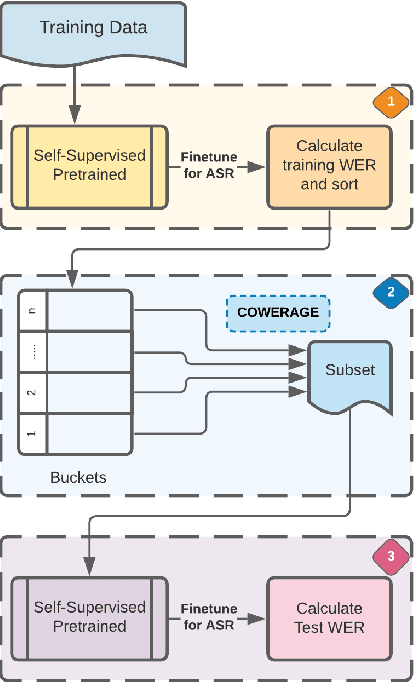
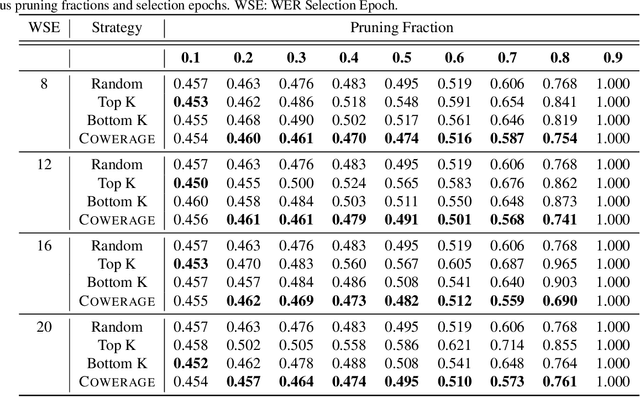
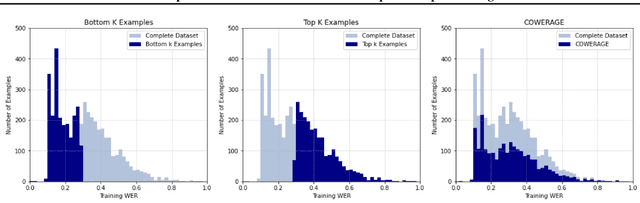

Self-supervised speech recognition models require considerable labeled training data for learning high-fidelity representations for Automatic Speech Recognition (ASR), which hinders their application to low-resource languages. We consider the task of identifying an optimal subset of training data to fine-tune self-supervised speech models for ASR. We make a surprising observation that active learning strategies for sampling harder-to-learn examples do not perform better than random subset selection for fine-tuning self-supervised ASR. We then present the COWERAGE algorithm for better subset selection in self-supervised ASR which is based on our finding that ensuring the coverage of examples based on training WER in the early training epochs leads to better generalization performance. Extensive experiments on the wav2vec 2.0 model and TIMIT dataset show the effectiveness of COWERAGE, with up to 27% absolute WER improvement over active learning methods. We also report the connection between training WER and the phonemic cover and demonstrate that our algorithm ensures inclusion of phonemically diverse examples.