 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Adaptable Detection of Malicious LLM Prompts via Bootstrap Aggregation
Feb 08, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language understanding, reasoning, and generation. However, these systems remain susceptible to malicious prompts that induce unsafe or policy-violating behavior through harmful requests, jailbreak techniques, and prompt injection attacks. Existing defenses face fundamental limitations: black-box moderation APIs offer limited transparency and adapt poorly to evolving threats, while white-box approaches using large LLM judges impose prohibitive computational costs and require expensive retraining for new attacks. Current systems force designers to choose between performance, efficiency, and adaptability. To address these challenges, we present BAGEL (Bootstrap AGgregated Ensemble Layer), a modular, lightweight, and incrementally updatable framework for malicious prompt detection. BAGEL employs a bootstrap aggregation and mixture of expert inspired ensemble of fine-tuned models, each specialized on a different attack dataset. At inference, BAGEL uses a random forest router to identify the most suitable ensemble member, then applies stochastic selection to sample additional members for prediction aggregation. When new attacks emerge, BAGEL updates incrementally by fine-tuning a small prompt-safety classifier (86M parameters) and adding the resulting model to the ensemble. BAGEL achieves an F1 score of 0.92 by selecting just 5 ensemble members (430M parameters), outperforming OpenAI Moderation API and ShieldGemma which require billions of parameters. Performance remains robust after nine incremental updates, and BAGEL provides interpretability through its router's structural features. Our results show ensembles of small finetuned classifiers can match or exceed billion-parameter guardrails while offering the adaptability and efficiency required for production systems.
TweakLLM: A Routing Architecture for Dynamic Tailoring of Cached Responses
Jul 31, 2025Large Language Models (LLMs) process millions of queries daily, making efficient response caching a compelling optimization for reducing cost and latency. However, preserving relevance to user queries using this approach proves difficult due to the personalized nature of chatbot interactions and the limited accuracy of semantic similarity search. To address this, we present TweakLLM, a novel routing architecture that employs a lightweight LLM to dynamically adapt cached responses to incoming prompts. Through comprehensive evaluation, including user studies with side-by-side comparisons, satisfaction voting, as well as multi-agent LLM debates, we demonstrate that TweakLLM maintains response quality comparable to frontier models while significantly improving cache effectiveness. Our results across real-world datasets highlight TweakLLM as a scalable, resource-efficient caching solution for high-volume LLM deployments without compromising user experience.
Rethinking Image Compression on the Web with Generative AI
Jul 05, 2024



The rapid growth of the Internet, driven by social media, web browsing, and video streaming, has made images central to the Web experience, resulting in significant data transfer and increased webpage sizes. Traditional image compression methods, while reducing bandwidth, often degrade image quality. This paper explores a novel approach using generative AI to reconstruct images at the edge or client-side. We develop a framework that leverages text prompts and provides additional conditioning inputs like Canny edges and color palettes to a text-to-image model, achieving up to 99.8% bandwidth savings in the best cases and 92.6% on average, while maintaining high perceptual similarity. Empirical analysis and a user study show that our method preserves image meaning and structure more effectively than traditional compression methods, offering a promising solution for reducing bandwidth usage and improving Internet affordability with minimal degradation in image quality.
FedPrune: Towards Inclusive Federated Learning
Oct 27, 2021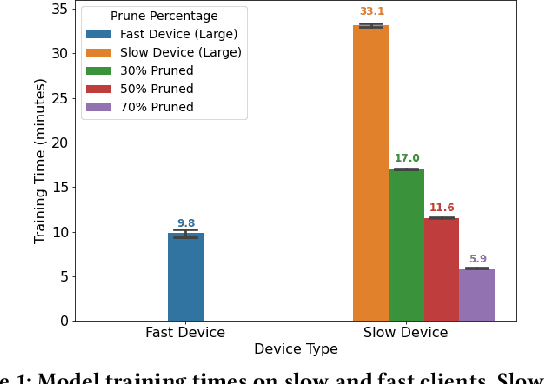
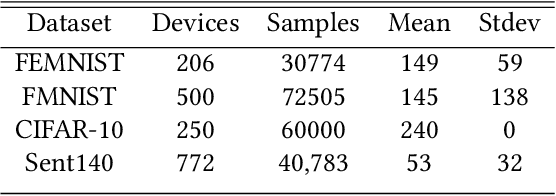
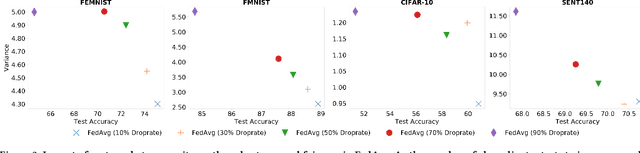
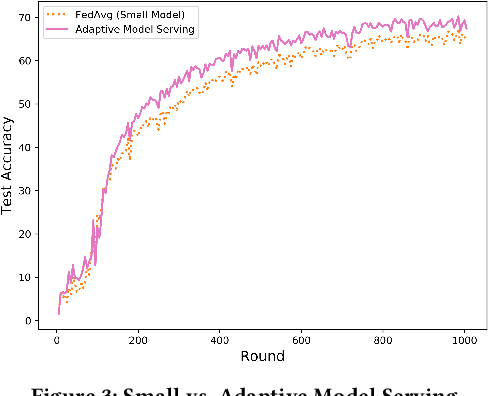
Federated learning (FL) is a distributed learning technique that trains a shared model over distributed data in a privacy-preserving manner. Unfortunately, FL's performance degrades when there is (i) variability in client characteristics in terms of computational and memory resources (system heterogeneity) and (ii) non-IID data distribution across clients (statistical heterogeneity). For example, slow clients get dropped in FL schemes, such as Federated Averaging (FedAvg), which not only limits overall learning but also biases results towards fast clients. We propose FedPrune; a system that tackles this challenge by pruning the global model for slow clients based on their device characteristics. By doing so, slow clients can train a small model quickly and participate in FL which increases test accuracy as well as fairness. By using insights from Central Limit Theorem, FedPrune incorporates a new aggregation technique that achieves robust performance over non-IID data. Experimental evaluation shows that Fed- Prune provides robust convergence and better fairness compared to Federated Averaging.