 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPrune: Towards Inclusive Federated Learning
Oct 27, 2021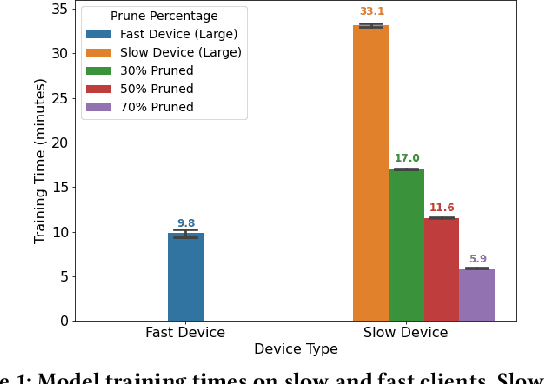
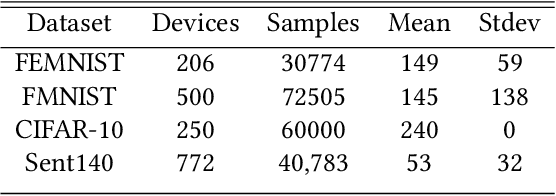
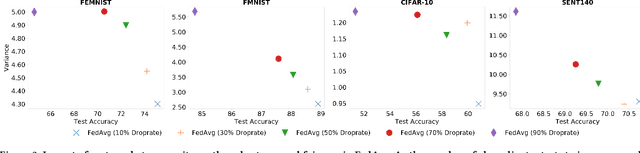
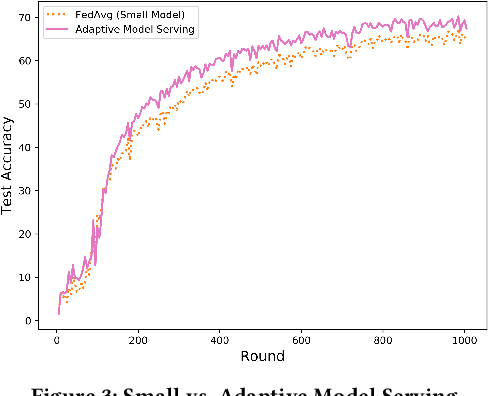
Federated learning (FL) is a distributed learning technique that trains a shared model over distributed data in a privacy-preserving manner. Unfortunately, FL's performance degrades when there is (i) variability in client characteristics in terms of computational and memory resources (system heterogeneity) and (ii) non-IID data distribution across clients (statistical heterogeneity). For example, slow clients get dropped in FL schemes, such as Federated Averaging (FedAvg), which not only limits overall learning but also biases results towards fast clients. We propose FedPrune; a system that tackles this challenge by pruning the global model for slow clients based on their device characteristics. By doing so, slow clients can train a small model quickly and participate in FL which increases test accuracy as well as fairness. By using insights from Central Limit Theorem, FedPrune incorporates a new aggregation technique that achieves robust performance over non-IID data. Experimental evaluation shows that Fed- Prune provides robust convergence and better fairness compared to Federated Averaging.