 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOT-JEPA: Generic Object Tracking with Model Adaptation and Occlusion Handling using Joint-Embedding Predictive Architecture
Feb 16, 2026The human visual system tracks objects by integrating current observations with previously observed information, adapting to target and scene changes, and reasoning about occlusion at fine granularity. In contrast, recent generic object trackers are often optimized for training targets, which limits robustness and generalization in unseen scenarios, and their occlusion reasoning remains coarse, lacking detailed modeling of occlusion patterns. To address these limitations in generalization and occlusion perception, we propose GOT-JEPA, a model-predictive pretraining framework that extends JEPA from predicting image features to predicting tracking models. Given identical historical information, a teacher predictor generates pseudo-tracking models from a clean current frame, and a student predictor learns to predict the same pseudo-tracking models from a corrupted version of the current frame. This design provides stable pseudo supervision and explicitly trains the predictor to produce reliable tracking models under occlusions, distractors, and other adverse observations, improving generalization to dynamic environments. Building on GOT-JEPA, we further propose OccuSolver to enhance occlusion perception for object tracking. OccuSolver adapts a point-centric point tracker for object-aware visibility estimation and detailed occlusion-pattern capture. Conditioned on object priors iteratively generated by the tracker, OccuSolver incrementally refines visibility states, strengthens occlusion handling, and produces higher-quality reference labels that progressively improve subsequent model predictions. Extensive evaluations on seven benchmarks show that our method effectively enhances tracker generalization and robustness.
GOT-Edit: Geometry-Aware Generic Object Tracking via Online Model Editing
Feb 09, 2026Human perception for effective object tracking in a 2D video stream arises from the implicit use of prior 3D knowledge combined with semantic reasoning. In contrast, most generic object tracking (GOT) methods primarily rely on 2D features of the target and its surroundings while neglecting 3D geometric cues, which makes them susceptible to partial occlusion, distractors, and variations in geometry and appearance. To address this limitation, we introduce GOT-Edit, an online cross-modality model editing approach that integrates geometry-aware cues into a generic object tracker from a 2D video stream. Our approach leverages features from a pre-trained Visual Geometry Grounded Transformer to enable geometric cue inference from only a few 2D images. To tackle the challenge of seamlessly combining geometry and semantics, GOT-Edit performs online model editing with null-space constrained updates that incorporate geometric information while preserving semantic discrimination, yielding consistently better performance across diverse scenarios. Extensive experiments on multiple GOT benchmarks demonstrate that GOT-Edit achieves superior robustness and accuracy, particularly under occlusion and clutter, establishing a new paradigm for combining 2D semantics with 3D geometric reasoning for generic object tracking.
Improving Visual Object Tracking through Visual Prompting
Sep 27, 2024

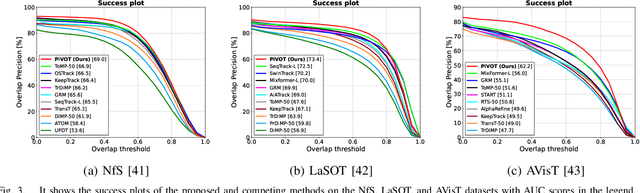

Learning a discriminative model to distinguish a target from its surrounding distractors is essential to generic visual object tracking. Dynamic target representation adaptation against distractors is challenging due to the limited discriminative capabilities of prevailing trackers. We present a new visual Prompting mechanism for generic Visual Object Tracking (PiVOT) to address this issue. PiVOT proposes a prompt generation network with the pre-trained foundation model CLIP to automatically generate and refine visual prompts, enabling the transfer of foundation model knowledge for tracking. While CLIP offers broad category-level knowledge, the tracker, trained on instance-specific data, excels at recognizing unique object instances. Thus, PiVOT first compiles a visual prompt highlighting potential target locations. To transfer the knowledge of CLIP to the tracker, PiVOT leverages CLIP to refine the visual prompt based on the similarities between candidate objects and the reference templates across potential targets. Once the visual prompt is refined, it can better highlight potential target locations, thereby reducing irrelevant prompt information. With the proposed prompting mechanism, the tracker can generate improved instance-aware feature maps through the guidance of the visual prompt, thus effectively reducing distractors. The proposed method does not involve CLIP during training, thereby keeping the same training complexity and preserving the generalization capability of the pretrained foundation model. Extensive experiments across multiple benchmarks indicate that PiVOT, using the proposed prompting method can suppress distracting objects and enhance the tracker.
Make Graph-based Referring Expression Comprehension Great Again through Expression-guided Dynamic Gating and Regression
Sep 05, 2024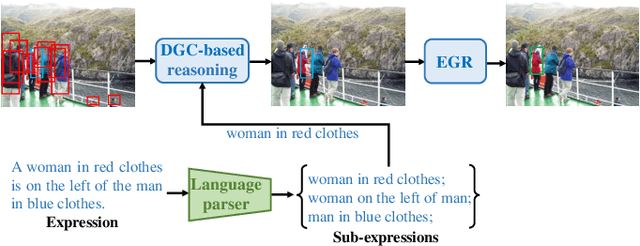
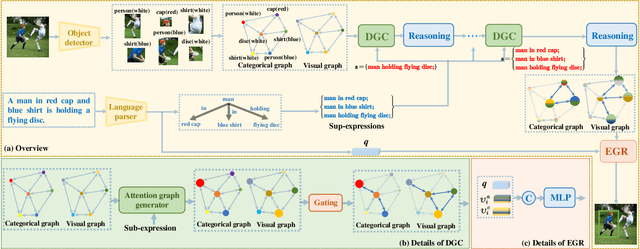
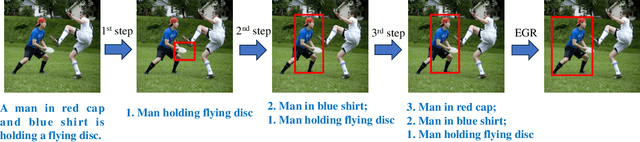

One common belief is that with complex models and pre-training on large-scale datasets, transformer-based methods for referring expression comprehension (REC) perform much better than existing graph-based methods. We observe that since most graph-based methods adopt an off-the-shelf detector to locate candidate objects (i.e., regions detected by the object detector), they face two challenges that result in subpar performance: (1) the presence of significant noise caused by numerous irrelevant objects during reasoning, and (2) inaccurate localization outcomes attributed to the provided detector. To address these issues, we introduce a plug-and-adapt module guided by sub-expressions, called dynamic gate constraint (DGC), which can adaptively disable irrelevant proposals and their connections in graphs during reasoning. We further introduce an expression-guided regression strategy (EGR) to refine location prediction. Extensive experimental results on the RefCOCO, RefCOCO+, RefCOCOg, Flickr30K, RefClef, and Ref-reasoning datasets demonstrate the effectiveness of the DGC module and the EGR strategy in consistently boosting the performances of various graph-based REC methods. Without any pretaining, the proposed graph-based method achieves better performance than the state-of-the-art (SOTA) transformer-based methods.
Set-to-Set Hashing with Applications in Visual Recognition
Nov 02, 2017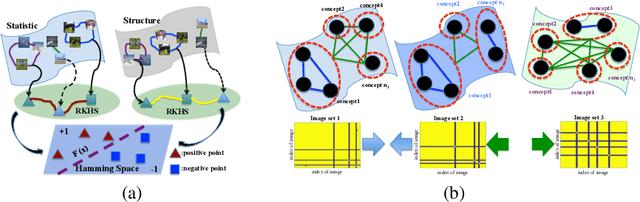
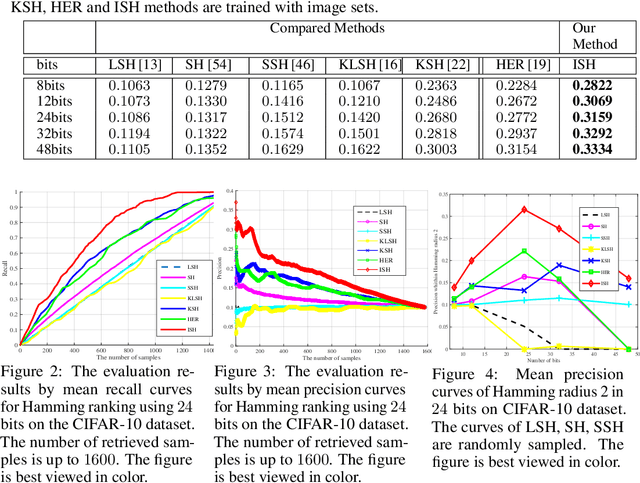
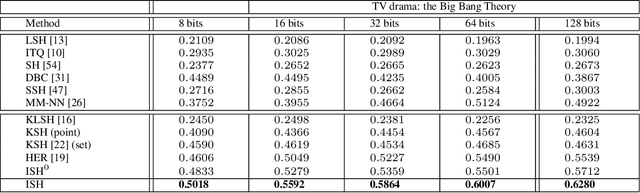
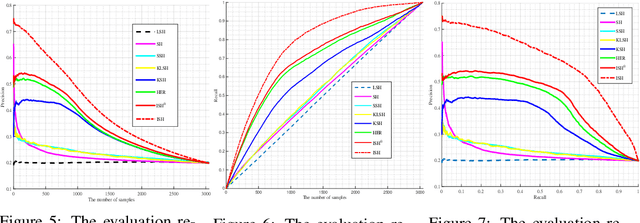
Visual data, such as an image or a sequence of video frames, is often naturally represented as a point set. In this paper, we consider the fundamental problem of finding a nearest set from a collection of sets, to a query set. This problem has obvious applications in large-scale visual retrieval and recognition, and also in applied fields beyond computer vision. One challenge stands out in solving the problem---set representation and measure of similarity. Particularly, the query set and the sets in dataset collection can have varying cardinalities. The training collection is large enough such that linear scan is impractical. We propose a simple representation scheme that encodes both statistical and structural information of the sets. The derived representations are integrated in a kernel framework for flexible similarity measurement. For the query set process, we adopt a learning-to-hash pipeline that turns the kernel representations into hash bits based on simple learners, using multiple kernel learning. Experiments on two visual retrieval datasets show unambiguously that our set-to-set hashing framework outperforms prior methods that do not take the set-to-set search setting.
Deep Image Set Hashing
Oct 01, 2016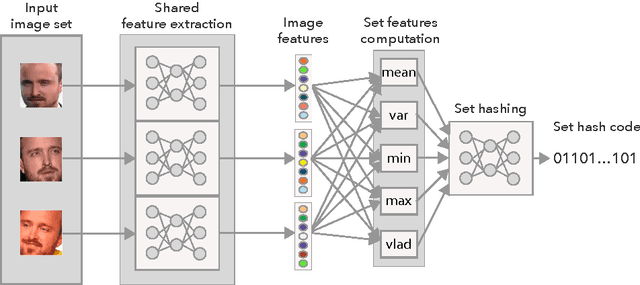
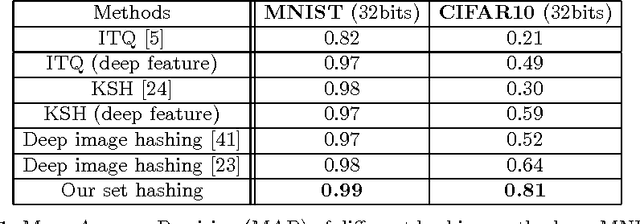
In applications involving matching of image sets, the information from multiple images must be effectively exploited to represent each set. State-of-the-art methods use probabilistic distribution or subspace to model a set and use specific distance measure to compare two sets. These methods are slow to compute and not compact to use in a large scale scenario. Learning-based hashing is often used in large scale image retrieval as they provide a compact representation of each sample and the Hamming distance can be used to efficiently compare two samples. However, most hashing methods encode each image separately and discard knowledge that multiple images in the same set represent the same object or person. We investigate the set hashing problem by combining both set representation and hashing in a single deep neural network. An image set is first passed to a CNN module to extract image features, then these features are aggregated using two types of set feature to capture both set specific and database-wide distribution information. The computed set feature is then fed into a multilayer perceptron to learn a compact binary embedding. Triplet loss is used to train the network by forming set similarity relations using class labels. We extensively evaluate our approach on datasets used for image matching and show highly competitive performance compared to state-of-the-art methods.