 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Set Hashing
Paper and Code
Oct 01, 2016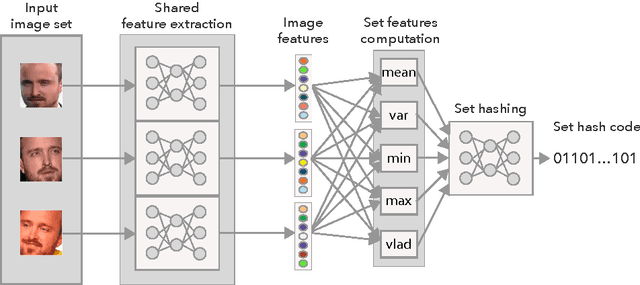
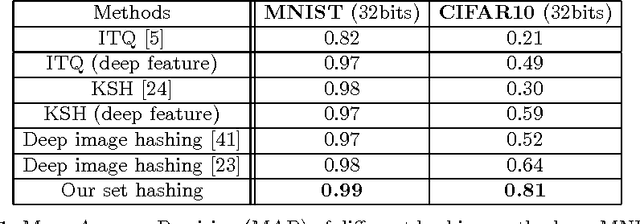
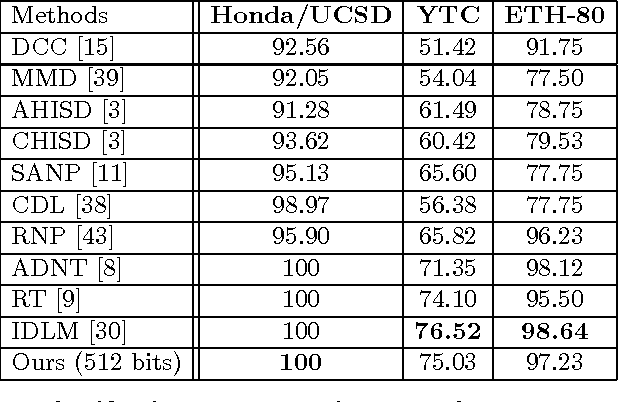
In applications involving matching of image sets, the information from multiple images must be effectively exploited to represent each set. State-of-the-art methods use probabilistic distribution or subspace to model a set and use specific distance measure to compare two sets. These methods are slow to compute and not compact to use in a large scale scenario. Learning-based hashing is often used in large scale image retrieval as they provide a compact representation of each sample and the Hamming distance can be used to efficiently compare two samples. However, most hashing methods encode each image separately and discard knowledge that multiple images in the same set represent the same object or person. We investigate the set hashing problem by combining both set representation and hashing in a single deep neural network. An image set is first passed to a CNN module to extract image features, then these features are aggregated using two types of set feature to capture both set specific and database-wide distribution information. The computed set feature is then fed into a multilayer perceptron to learn a compact binary embedding. Triplet loss is used to train the network by forming set similarity relations using class labels. We extensively evaluate our approach on datasets used for image matching and show highly competitive performance compared to state-of-the-art methods.