 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-to-Set Hashing with Applications in Visual Recognition
Paper and Code
Nov 02, 2017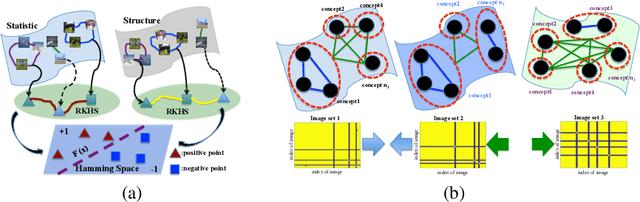
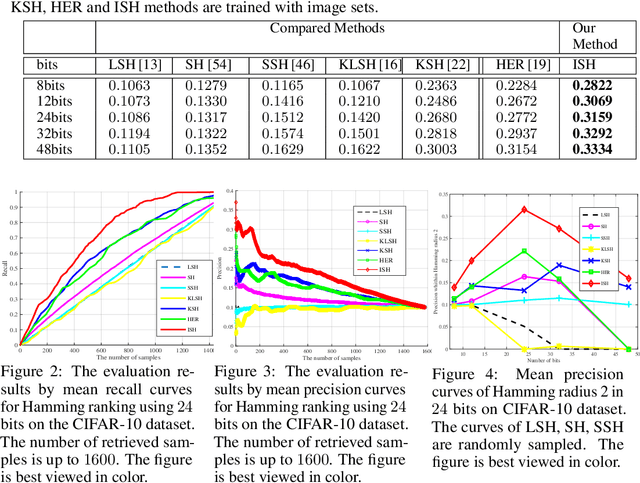
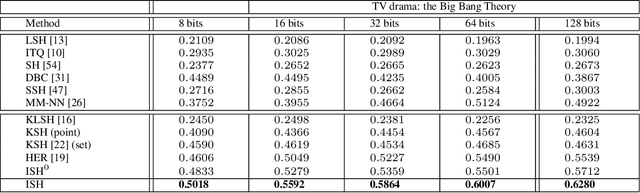
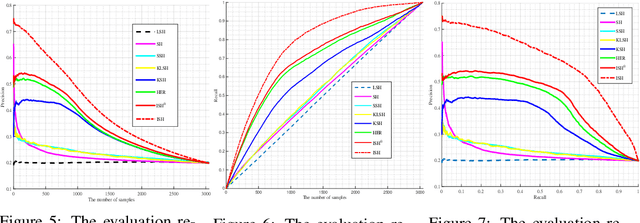
Visual data, such as an image or a sequence of video frames, is often naturally represented as a point set. In this paper, we consider the fundamental problem of finding a nearest set from a collection of sets, to a query set. This problem has obvious applications in large-scale visual retrieval and recognition, and also in applied fields beyond computer vision. One challenge stands out in solving the problem---set representation and measure of similarity. Particularly, the query set and the sets in dataset collection can have varying cardinalities. The training collection is large enough such that linear scan is impractical. We propose a simple representation scheme that encodes both statistical and structural information of the sets. The derived representations are integrated in a kernel framework for flexible similarity measurement. For the query set process, we adopt a learning-to-hash pipeline that turns the kernel representations into hash bits based on simple learners, using multiple kernel learning. Experiments on two visual retrieval datasets show unambiguously that our set-to-set hashing framework outperforms prior methods that do not take the set-to-set search setting.