 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSO-SLAM: Bidirectionally Coupled Gaussian Splatting and Direct Visual Odometry
Feb 12, 2026We propose GSO-SLAM, a real-time monocular dense SLAM system that leverages Gaussian scene representation. Unlike existing methods that couple tracking and mapping with a unified scene, incurring computational costs, or loosely integrate them with well-structured tracking frameworks, introducing redundancies, our method bidirectionally couples Visual Odometry (VO) and Gaussian Splatting (GS). Specifically, our approach formulates joint optimization within an Expectation-Maximization (EM) framework, enabling the simultaneous refinement of VO-derived semi-dense depth estimates and the GS representation without additional computational overhead. Moreover, we present Gaussian Splat Initialization, which utilizes image information, keyframe poses, and pixel associations from VO to produce close approximations to the final Gaussian scene, thereby eliminating the need for heuristic methods. Through extensive experiments, we validate the effectiveness of our method, showing that it not only operates in real time but also achieves state-of-the-art geometric/photometric fidelity of the reconstructed scene and tracking accuracy.
LAMP: Implicit Language Map for Robot Navigation
Feb 12, 2026Recent advances in vision-language models have made zero-shot navigation feasible, enabling robots to follow natural language instructions without requiring labeling. However, existing methods that explicitly store language vectors in grid or node-based maps struggle to scale to large environments due to excessive memory requirements and limited resolution for fine-grained planning. We introduce LAMP (Language Map), a novel neural language field-based navigation framework that learns a continuous, language-driven map and directly leverages it for fine-grained path generation. Unlike prior approaches, our method encodes language features as an implicit neural field rather than storing them explicitly at every location. By combining this implicit representation with a sparse graph, LAMP supports efficient coarse path planning and then performs gradient-based optimization in the learned field to refine poses near the goal. This coarse-to-fine pipeline, language-driven, gradient-guided optimization is the first application of an implicit language map for precise path generation. This refinement is particularly effective at selecting goal regions not directly observed by leveraging semantic similarities in the learned feature space. To further enhance robustness, we adopt a Bayesian framework that models embedding uncertainty via the von Mises-Fisher distribution, thereby improving generalization to unobserved regions. To scale to large environments, LAMP employs a graph sampling strategy that prioritizes spatial coverage and embedding confidence, retaining only the most informative nodes and substantially reducing computational overhead. Our experimental results, both in NVIDIA Isaac Sim and on a real multi-floor building, demonstrate that LAMP outperforms existing explicit methods in both memory efficiency and fine-grained goal-reaching accuracy.
* Accepted for publication in IEEE Robotics and Automation Letters (RA-L). Project page: https://lab-of-ai-and-robotics.github.io/LAMP/
OpenMonoGS-SLAM: Monocular Gaussian Splatting SLAM with Open-set Semantics
Dec 09, 2025Simultaneous Localization and Mapping (SLAM) is a foundational component in robotics, AR/VR, and autonomous systems. With the rising focus on spatial AI in recent years, combining SLAM with semantic understanding has become increasingly important for enabling intelligent perception and interaction. Recent efforts have explored this integration, but they often rely on depth sensors or closed-set semantic models, limiting their scalability and adaptability in open-world environments. In this work, we present OpenMonoGS-SLAM, the first monocular SLAM framework that unifies 3D Gaussian Splatting (3DGS) with open-set semantic understanding. To achieve our goal, we leverage recent advances in Visual Foundation Models (VFMs), including MASt3R for visual geometry and SAM and CLIP for open-vocabulary semantics. These models provide robust generalization across diverse tasks, enabling accurate monocular camera tracking and mapping, as well as a rich understanding of semantics in open-world environments. Our method operates without any depth input or 3D semantic ground truth, relying solely on self-supervised learning objectives. Furthermore, we propose a memory mechanism specifically designed to manage high-dimensional semantic features, which effectively constructs Gaussian semantic feature maps, leading to strong overall performance. Experimental results demonstrate that our approach achieves performance comparable to or surpassing existing baselines in both closed-set and open-set segmentation tasks, all without relying on supplementary sensors such as depth maps or semantic annotations.
Efficient 3D Perception on Embedded Systems via Interpolation-Free Tri-Plane Lifting and Volume Fusion
Sep 18, 2025Dense 3D convolutions provide high accuracy for perception but are too computationally expensive for real-time robotic systems. Existing tri-plane methods rely on 2D image features with interpolation, point-wise queries, and implicit MLPs, which makes them computationally heavy and unsuitable for embedded 3D inference. As an alternative, we propose a novel interpolation-free tri-plane lifting and volumetric fusion framework, that directly projects 3D voxels into plane features and reconstructs a feature volume through broadcast and summation. This shifts nonlinearity to 2D convolutions, reducing complexity while remaining fully parallelizable. To capture global context, we add a low-resolution volumetric branch fused with the lifted features through a lightweight integration layer, yielding a design that is both efficient and end-to-end GPU-accelerated. To validate the effectiveness of the proposed method, we conduct experiments on classification, completion, segmentation, and detection, and we map the trade-off between efficiency and accuracy across tasks. Results show that classification and completion retain or improve accuracy, while segmentation and detection trade modest drops in accuracy for significant computational savings. On-device benchmarks on an NVIDIA Jetson Orin nano confirm robust real-time throughput, demonstrating the suitability of the approach for embedded robotic perception.
Bayesian NeRF: Quantifying Uncertainty with Volume Density in Neural Radiance Fields
Apr 10, 2024We present the Bayesian Neural Radiance Field (NeRF), which explicitly quantifies uncertainty in geometric volume structures without the need for additional networks, making it adept for challenging observations and uncontrolled images. NeRF diverges from traditional geometric methods by offering an enriched scene representation, rendering color and density in 3D space from various viewpoints. However, NeRF encounters limitations in relaxing uncertainties by using geometric structure information, leading to inaccuracies in interpretation under insufficient real-world observations. Recent research efforts aimed at addressing this issue have primarily relied on empirical methods or auxiliary networks. To fundamentally address this issue, we propose a series of formulational extensions to NeRF. By introducing generalized approximations and defining density-related uncertainty, our method seamlessly extends to manage uncertainty not only for RGB but also for depth, without the need for additional networks or empirical assumptions. In experiments we show that our method significantly enhances performance on RGB and depth images in the comprehensive dataset, demonstrating the reliability of the Bayesian NeRF approach to quantifying uncertainty based on the geometric structure.
RGBD GS-ICP SLAM
Mar 22, 2024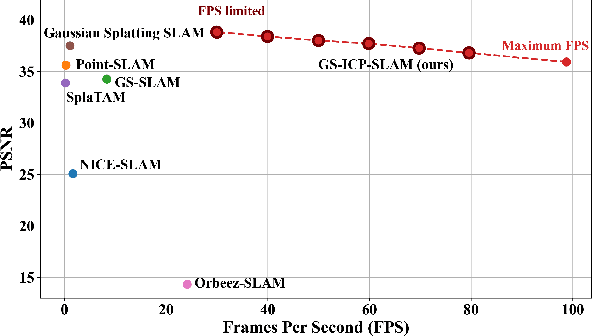
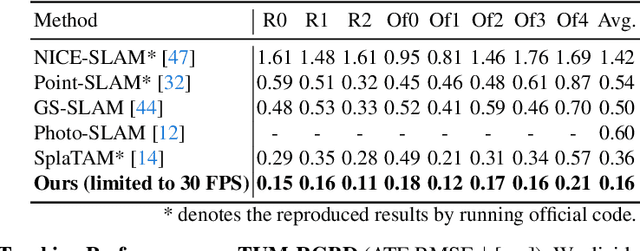
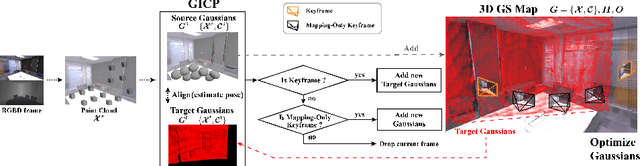
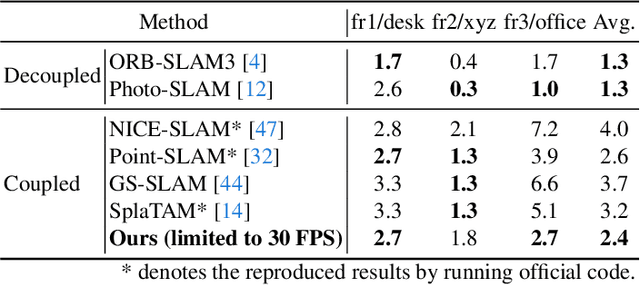
Simultaneous Localization and Mapping (SLAM) with dense representation plays a key role in robotics, Virtual Reality (VR), and Augmented Reality (AR) applications. Recent advancements in dense representation SLAM have highlighted the potential of leveraging neural scene representation and 3D Gaussian representation for high-fidelity spatial representation. In this paper, we propose a novel dense representation SLAM approach with a fusion of Generalized Iterative Closest Point (G-ICP) and 3D Gaussian Splatting (3DGS). In contrast to existing methods, we utilize a single Gaussian map for both tracking and mapping, resulting in mutual benefits. Through the exchange of covariances between tracking and mapping processes with scale alignment techniques, we minimize redundant computations and achieve an efficient system. Additionally, we enhance tracking accuracy and mapping quality through our keyframe selection methods. Experimental results demonstrate the effectiveness of our approach, showing an incredibly fast speed up to 107 FPS (for the entire system) and superior quality of the reconstructed map.
Necessity Feature Correspondence Estimation for Large-scale Global Place Recognition and Relocalization
Mar 11, 2023



Global place recognition and 3D relocalization are one of the most important components in the loop closing detection for 3D LiDAR Simultaneous Localization and Mapping (SLAM). In order to find the accurate global 6-DoF transform by feature matching approach, various end-to-end architectures have been proposed. However, existing methods do not consider the false correspondence of the features, thereby unnecessary features are also involved in global place recognition and relocalization. In this paper, we introduce a robust correspondence estimation method by removing unnecessary features and highlighting necessary features simultaneously. To focus on the necessary features and ignore the unnecessary ones, we use the geometric correlation between two scenes represented in the 3D LiDAR point clouds. We introduce the correspondence auxiliary loss that finds key correlations based on the point align algorithm and enables end-to-end training of the proposed networks with robust correspondence estimation. Since the ground with many plane patches acts as an outlier during correspondence estimation, we also propose a preprocessing step to consider negative correspondence by removing dominant plane patches. The evaluation results on the dynamic urban driving dataset, show that our proposed method can improve the performances of both global place recognition and relocalization tasks. We show that estimating the robust feature correspondence is one of the important factors in place recognition and relocalization.
Just Flip: Flipped Observation Generation and Optimization for Neural Radiance Fields to Cover Unobserved View
Mar 11, 2023


With the advent of Neural Radiance Field (NeRF), representing 3D scenes through multiple observations has shown remarkable improvements in performance. Since this cutting-edge technique is able to obtain high-resolution renderings by interpolating dense 3D environments, various approaches have been proposed to apply NeRF for the spatial understanding of robot perception. However, previous works are challenging to represent unobserved scenes or views on the unexplored robot trajectory, as these works do not take into account 3D reconstruction without observation information. To overcome this problem, we propose a method to generate flipped observation in order to cover unexisting observation for unexplored robot trajectory. To achieve this, we propose a data augmentation method for 3D reconstruction using NeRF by flipping observed images, and estimating flipped camera 6DOF poses. Our technique exploits the property of objects being geometrically symmetric, making it simple but fast and powerful, thereby making it suitable for robotic applications where real-time performance is important. We demonstrate that our method significantly improves three representative perceptual quality measures on the NeRF synthetic dataset.
Self-supervised Learning of 3D Object Understanding by Data Association and Landmark Estimation for Image Sequence
Apr 14, 2021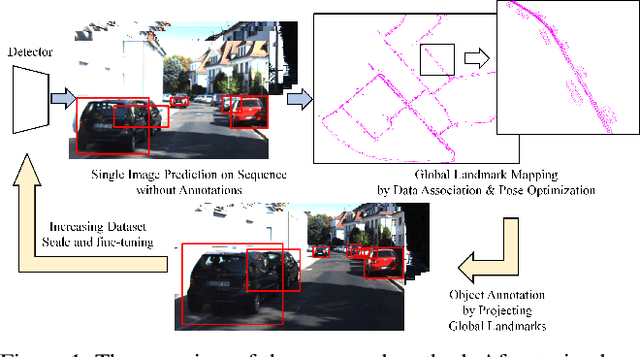
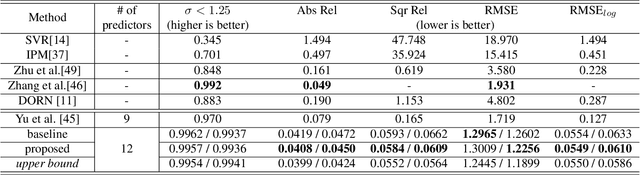
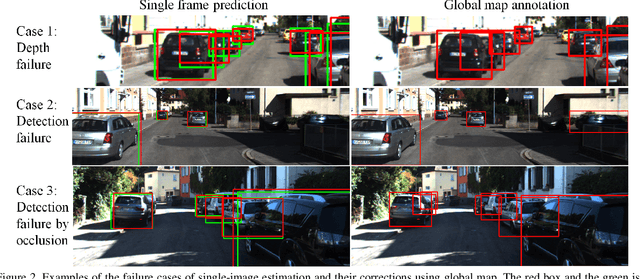

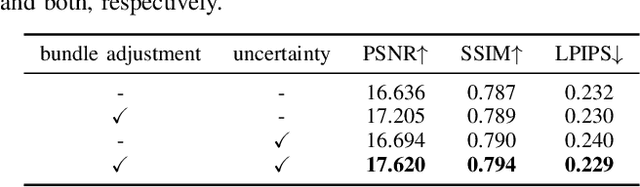
In this paper, we propose a self-supervised learningmethod for multi-object pose estimation. 3D object under-standing from 2D image is a challenging task that infers ad-ditional dimension from reduced-dimensional information.In particular, the estimation of the 3D localization or orien-tation of an object requires precise reasoning, unlike othersimple clustering tasks such as object classification. There-fore, the scale of the training dataset becomes more cru-cial. However, it is challenging to obtain large amount of3D dataset since achieving 3D annotation is expensive andtime-consuming. If the scale of the training dataset can beincreased by involving the image sequence obtained fromsimple navigation, it is possible to overcome the scale lim-itation of the dataset and to have efficient adaptation tothe new environment. However, when the self annotation isconducted on single image by the network itself, trainingperformance of the network is bounded to the self perfor-mance. Therefore, we propose a strategy to exploit multipleobservations of the object in the image sequence in orderto surpass the self-performance: first, the landmarks for theglobal object map are estimated through network predic-tion and data association, and the corrected annotation fora single frame is obtained. Then, network fine-tuning is con-ducted including the dataset obtained by self-annotation,thereby exceeding the performance boundary of the networkitself. The proposed method was evaluated on the KITTIdriving scene dataset, and we demonstrate the performanceimprovement in the pose estimation of multi-object in 3D space.
Domain Adaptive Monocular Depth Estimation With Semantic Information
Apr 12, 2021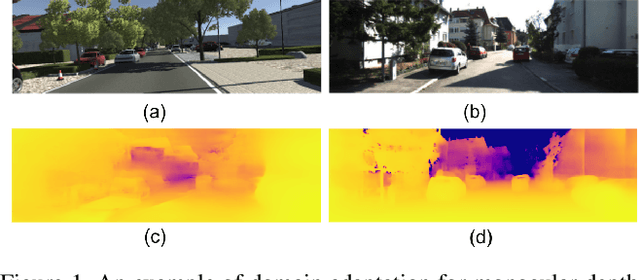
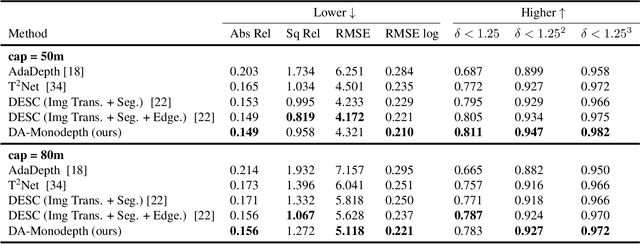
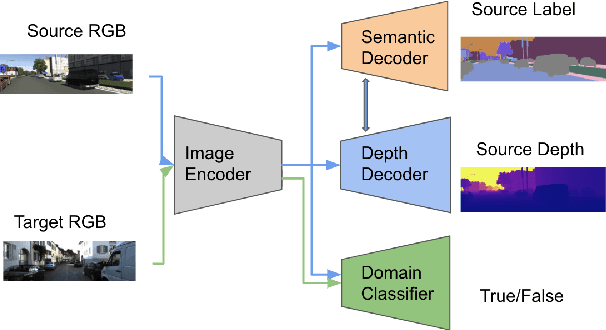
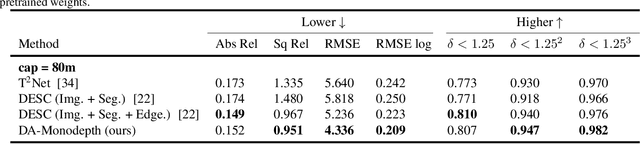
The advent of deep learning has brought an impressive advance to monocular depth estimation, e.g., supervised monocular depth estimation has been thoroughly investigated. However, the large amount of the RGB-to-depth dataset may not be always available since collecting accurate depth ground truth according to the RGB image is a time-consuming and expensive task. Although the network can be trained on an alternative dataset to overcome the dataset scale problem, the trained model is hard to generalize to the target domain due to the domain discrepancy. Adversarial domain alignment has demonstrated its efficacy to mitigate the domain shift on simple image classification tasks in previous works. However, traditional approaches hardly handle the conditional alignment as they solely consider the feature map of the network. In this paper, we propose an adversarial training model that leverages semantic information to narrow the domain gap. Based on the experiments conducted on the datasets for the monocular depth estimation task including KITTI and Cityscapes, the proposed compact model achieves state-of-the-art performance comparable to complex latest models and shows favorable results on boundaries and objects at far distances.