 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSBBTS: A Unified Schrödinger-Bass Framework for Synthetic Financial Time Series
Apr 08, 2026We study the problem of generating synthetic time series that reproduce both marginal distributions and temporal dynamics, a central challenge in financial machine learning. Existing approaches typically fail to jointly model drift and stochastic volatility, as diffusion-based methods fix the volatility while martingale transport models ignore drift. We introduce the Schrödinger-Bass Bridge for Time Series (SBBTS), a unified framework that extends the Schrödinger-Bass formulation to multi-step time series. The method constructs a diffusion process that jointly calibrates drift and volatility and admits a tractable decomposition into conditional transport problems, enabling efficient learning. Numerical experiments on the Heston model demonstrate that SBBTS accurately recovers stochastic volatility and correlation parameters that prior SchrödingerBridge methods fail to capture. Applied to S&P 500 data, SBBTS-generated synthetic time series consistently improve downstream forecasting performance when used for data augmentation, yielding higher classification accuracy and Sharpe ratio compared to real-data-only training. These results show that SBBTS provides a practical and effective framework for realistic time series generation and data augmentation in financial applications.
Learning operators on labelled conditional distributions with applications to mean field control of non exchangeable systems
Mar 23, 2026We study the approximation of operators acting on probability measures on a product space with prescribed marginal. Let $I$ be a label space endowed with a reference measure $λ$, and define $\cal M_λ$ as the set of probability measures on $I\times \mathbb{R}^d$ with first marginal $λ$. By disintegration, elements of $\cal M_λ$ correspond to families of labeled conditional distributions. Operators defined on this constrained measure space arise naturally in mean-field control problems with heterogeneous, non-exchangeable agents. Our main theoretical result establishes a universal approximation theorem for continuous operators on $\cal M_λ$. The proof combines cylindrical approximations of probability measures with DeepONet-type branch-trunk neural architecture, yielding finite-dimensional representations of such operators. We further introduce a sampling strategy for generating training measures in $\cal M_λ$, enabling practical learning of such conditional mean-field operators. We apply the method to the numerical resolution of mean-field control problems with heterogeneous interactions, thereby extending previous neural approaches developed for homogeneous (exchangeable) systems. Numerical experiments illustrate the accuracy and computational effectiveness of the proposed framework.
LightSBB-M: Bridging Schrödinger and Bass for Generative Diffusion Modeling
Jan 27, 2026The Schrodinger Bridge and Bass (SBB) formulation, which jointly controls drift and volatility, is an established extension of the classical Schrodinger Bridge (SB). Building on this framework, we introduce LightSBB-M, an algorithm that computes the optimal SBB transport plan in only a few iterations. The method exploits a dual representation of the SBB objective to obtain analytic expressions for the optimal drift and volatility, and it incorporates a tunable parameter beta greater than zero that interpolates between pure drift (the Schrodinger Bridge) and pure volatility (Bass martingale transport). We show that LightSBB-M achieves the lowest 2-Wasserstein distance on synthetic datasets against state-of-the-art SB and diffusion baselines with up to 32 percent improvement. We also illustrate the generative capability of the framework on an unpaired image-to-image translation task (adult to child faces in FFHQ). These findings demonstrate that LightSBB-M provides a scalable, high-fidelity SBB solver that outperforms existing SB and diffusion baselines across both synthetic and real-world generative tasks. The code is available at https://github.com/alexouadi/LightSBB-M.
Model-free policy gradient for discrete-time mean-field control
Jan 16, 2026We study model-free policy learning for discrete-time mean-field control (MFC) problems with finite state space and compact action space. In contrast to the extensive literature on value-based methods for MFC, policy-based approaches remain largely unexplored due to the intrinsic dependence of transition kernels and rewards on the evolving population state distribution, which prevents the direct use of likelihood-ratio estimators of policy gradients from classical single-agent reinforcement learning. We introduce a novel perturbation scheme on the state-distribution flow and prove that the gradient of the resulting perturbed value function converges to the true policy gradient as the perturbation magnitude vanishes. This construction yields a fully model-free estimator based solely on simulated trajectories and an auxiliary estimate of the sensitivity of the state distribution. Building on this framework, we develop MF-REINFORCE, a model-free policy gradient algorithm for MFC, and establish explicit quantitative bounds on its bias and mean-squared error. Numerical experiments on representative mean-field control tasks demonstrate the effectiveness of the proposed approach.
Robust time series generation via Schrödinger Bridge: a comprehensive evaluation
Mar 04, 2025
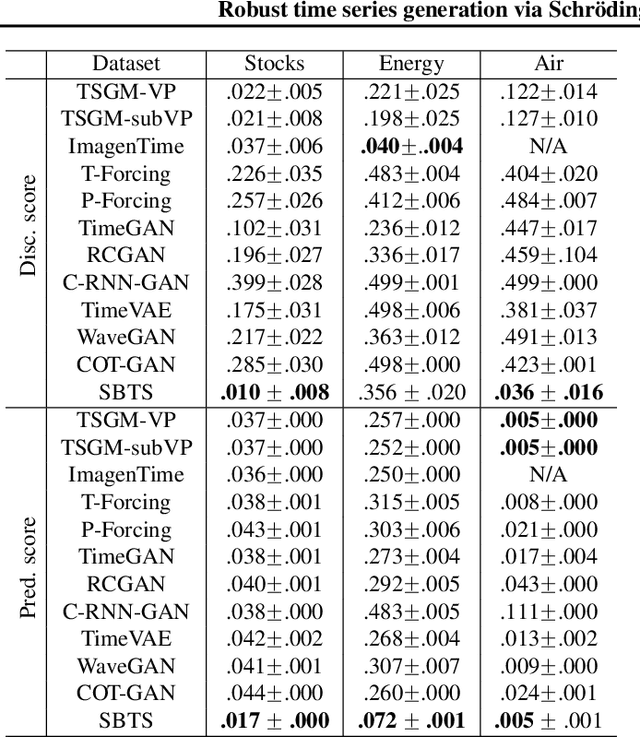

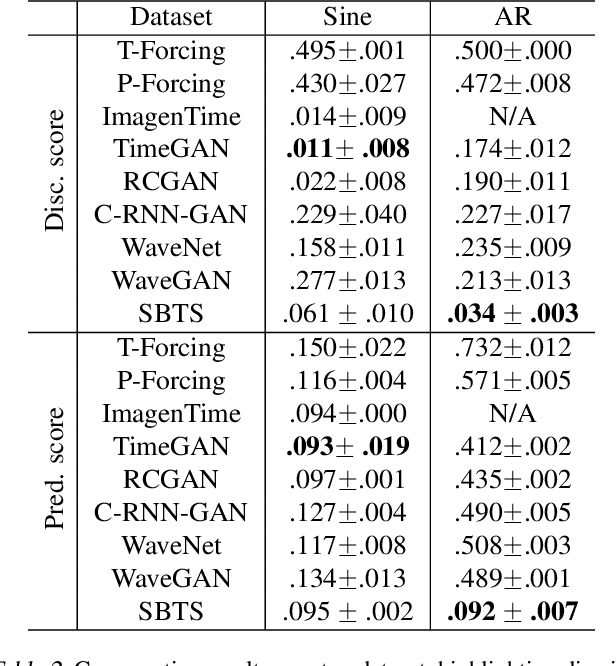
We investigate the generative capabilities of the Schr\"odinger Bridge (SB) approach for time series. The SB framework formulates time series synthesis as an entropic optimal interpolation transport problem between a reference probability measure on path space and a target joint distribution. This results in a stochastic differential equation over a finite horizon that accurately captures the temporal dynamics of the target time series. While the SB approach has been largely explored in fields like image generation, there is a scarcity of studies for its application to time series. In this work, we bridge this gap by conducting a comprehensive evaluation of the SB method's robustness and generative performance. We benchmark it against state-of-the-art (SOTA) time series generation methods across diverse datasets, assessing its strengths, limitations, and capacity to model complex temporal dependencies. Our results offer valuable insights into the SB framework's potential as a versatile and robust tool for time series generation.
Full error analysis of policy gradient learning algorithms for exploratory linear quadratic mean-field control problem in continuous time with common noise
Aug 05, 2024



We consider reinforcement learning (RL) methods for finding optimal policies in linear quadratic (LQ) mean field control (MFC) problems over an infinite horizon in continuous time, with common noise and entropy regularization. We study policy gradient (PG) learning and first demonstrate convergence in a model-based setting by establishing a suitable gradient domination condition.Next, our main contribution is a comprehensive error analysis, where we prove the global linear convergence and sample complexity of the PG algorithm with two-point gradient estimates in a model-free setting with unknown parameters. In this setting, the parameterized optimal policies are learned from samples of the states and population distribution.Finally, we provide numerical evidence supporting the convergence of our implemented algorithms.
Control randomisation approach for policy gradient and application to reinforcement learning in optimal switching
Apr 30, 2024We propose a comprehensive framework for policy gradient methods tailored to continuous time reinforcement learning. This is based on the connection between stochastic control problems and randomised problems, enabling applications across various classes of Markovian continuous time control problems, beyond diffusion models, including e.g. regular, impulse and optimal stopping/switching problems. By utilizing change of measure in the control randomisation technique, we derive a new policy gradient representation for these randomised problems, featuring parametrised intensity policies. We further develop actor-critic algorithms specifically designed to address general Markovian stochastic control issues. Our framework is demonstrated through its application to optimal switching problems, with two numerical case studies in the energy sector focusing on real options.
Actor critic learning algorithms for mean-field control with moment neural networks
Sep 08, 2023



We develop a new policy gradient and actor-critic algorithm for solving mean-field control problems within a continuous time reinforcement learning setting. Our approach leverages a gradient-based representation of the value function, employing parametrized randomized policies. The learning for both the actor (policy) and critic (value function) is facilitated by a class of moment neural network functions on the Wasserstein space of probability measures, and the key feature is to sample directly trajectories of distributions. A central challenge addressed in this study pertains to the computational treatment of an operator specific to the mean-field framework. To illustrate the effectiveness of our methods, we provide a comprehensive set of numerical results. These encompass diverse examples, including multi-dimensional settings and nonlinear quadratic mean-field control problems with controlled volatility.
Generative modeling for time series via Schr{ö}dinger bridge
Apr 11, 2023



We propose a novel generative model for time series based on Schr{\"o}dinger bridge (SB) approach. This consists in the entropic interpolation via optimal transport between a reference probability measure on path space and a target measure consistent with the joint data distribution of the time series. The solution is characterized by a stochastic differential equation on finite horizon with a path-dependent drift function, hence respecting the temporal dynamics of the time series distribution. We can estimate the drift function from data samples either by kernel regression methods or with LSTM neural networks, and the simulation of the SB diffusion yields new synthetic data samples of the time series. The performance of our generative model is evaluated through a series of numerical experiments. First, we test with a toy autoregressive model, a GARCH Model, and the example of fractional Brownian motion, and measure the accuracy of our algorithm with marginal and temporal dependencies metrics. Next, we use our SB generated synthetic samples for the application to deep hedging on real-data sets. Finally, we illustrate the SB approach for generating sequence of images.
Actor-Critic learning for mean-field control in continuous time
Mar 13, 2023



We study policy gradient for mean-field control in continuous time in a reinforcement learning setting. By considering randomised policies with entropy regularisation, we derive a gradient expectation representation of the value function, which is amenable to actor-critic type algorithms, where the value functions and the policies are learnt alternately based on observation samples of the state and model-free estimation of the population state distribution, either by offline or online learning. In the linear-quadratic mean-field framework, we obtain an exact parametrisation of the actor and critic functions defined on the Wasserstein space. Finally, we illustrate the results of our algorithms with some numerical experiments on concrete examples.