 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustry-Scale Orchestrated Federated Learning for Drug Discovery
Oct 17, 2022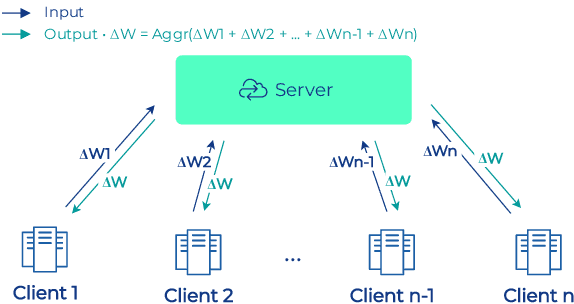
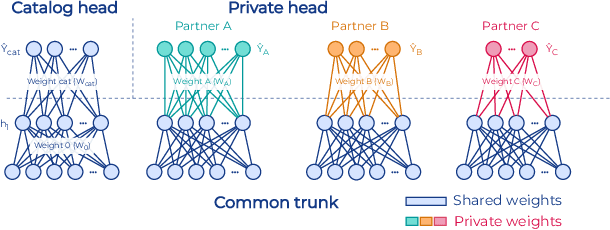
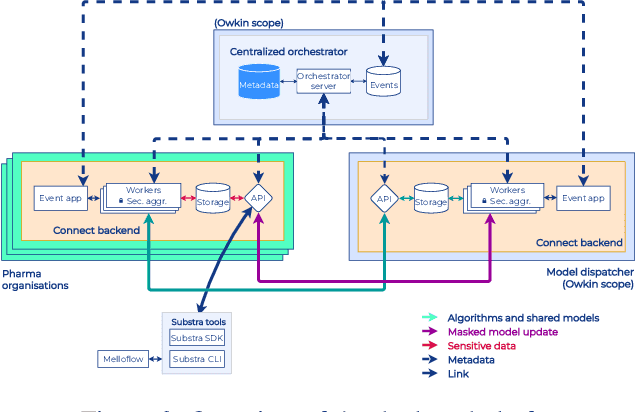
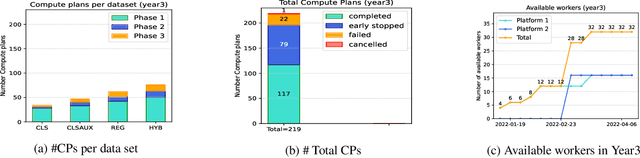
To apply federated learning to drug discovery we developed a novel platform in the context of European Innovative Medicines Initiative (IMI) project MELLODDY (grant n{\deg}831472), which was comprised of 10 pharmaceutical companies, academic research labs, large industrial companies and startups. To the best of our knowledge, The MELLODDY platform was the first industry-scale platform to enable the creation of a global federated model for drug discovery without sharing the confidential data sets of the individual partners. The federated model was trained on the platform by aggregating the gradients of all contributing partners in a cryptographic, secure way following each training iteration. The platform was deployed on an Amazon Web Services (AWS) multi-account architecture running Kubernetes clusters in private subnets. Organisationally, the roles of the different partners were codified as different rights and permissions on the platform and administrated in a decentralized way. The MELLODDY platform generated new scientific discoveries which are described in a companion paper.
Fast semi-supervised discriminant analysis for binary classification of large data-sets
Mar 01, 2018


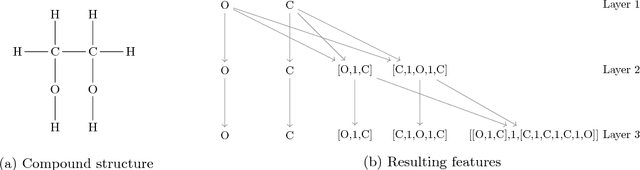
High-dimensional data requires scalable algorithms. We propose and analyze three scalable and related algorithms for semi-supervised discriminant analysis (SDA). These methods are based on Krylov subspace methods which exploit the data sparsity and the shift-invariance of Krylov subspaces. In addition, the problem definition was improved by adding centralization to the semi-supervised setting. The proposed methods are evaluated on a industry-scale data set from a pharmaceutical company to predict compound activity on target proteins. The results show that SDA achieves good predictive performance and our methods only require a few seconds, significantly improving computation time on previous state of the art.
Macau: Scalable Bayesian Multi-relational Factorization with Side Information using MCMC
Dec 17, 2015

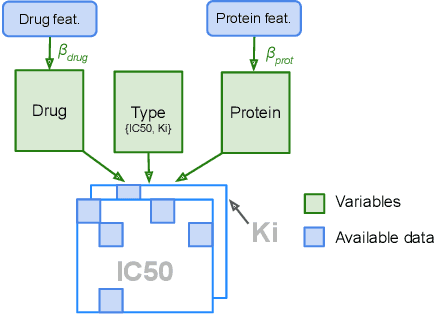
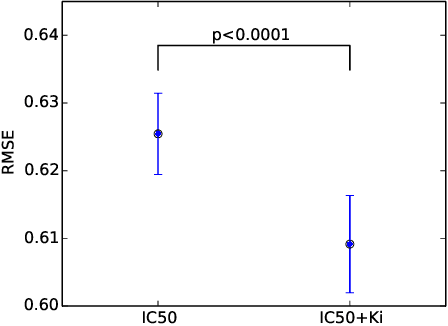
We propose Macau, a powerful and flexible Bayesian factorization method for heterogeneous data. Our model can factorize any set of entities and relations that can be represented by a relational model, including tensors and also multiple relations for each entity. Macau can also incorporate side information, specifically entity and relation features, which are crucial for predicting sparsely observed relations. Macau scales to millions of entity instances, hundred millions of observations, and sparse entity features with millions of dimensions. To achieve the scale up, we specially designed sampling procedure for entity and relation features that relies primarily on noise injection in linear regressions. We show performance and advanced features of Macau in a set of experiments, including challenging drug-protein activity prediction task.
Highly Scalable Tensor Factorization for Prediction of Drug-Protein Interaction Type
Dec 01, 2015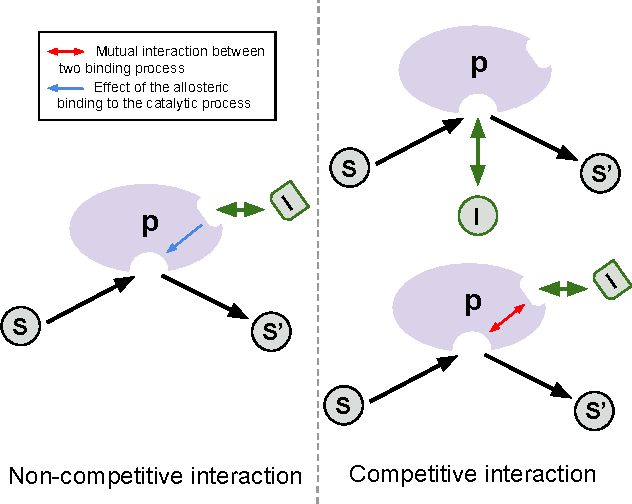
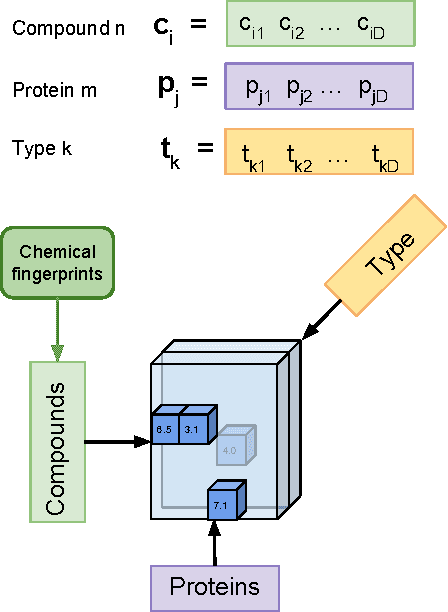
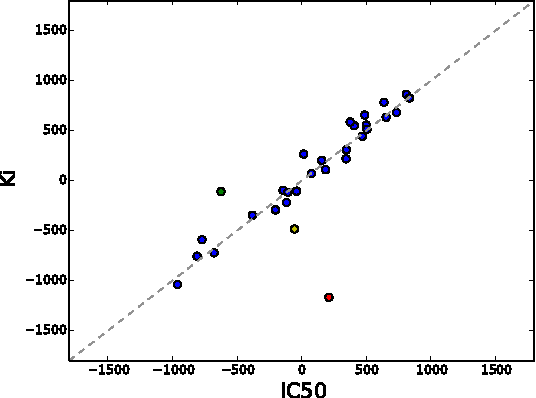

The understanding of the type of inhibitory interaction plays an important role in drug design. Therefore, researchers are interested to know whether a drug has competitive or non-competitive interaction to particular protein targets. Method: to analyze the interaction types we propose factorization method Macau which allows us to combine different measurement types into a single tensor together with proteins and compounds. The compounds are characterized by high dimensional 2D ECFP fingerprints. The novelty of the proposed method is that using a specially designed noise injection MCMC sampler it can incorporate high dimensional side information, i.e., millions of unique 2D ECFP compound features, even for large scale datasets of millions of compounds. Without the side information, in this case, the tensor factorization would be practically futile. Results: using public IC50 and Ki data from ChEMBL we trained a model from where we can identify the latent subspace separating the two measurement types (IC50 and Ki). The results suggest the proposed method can detect the competitive inhibitory activity between compounds and proteins.