 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-EAPCR-T: A Universal Deep Learning Approach for Anomaly Detection in Industrial Equipment
Mar 16, 2025With the advancement of Industry 4.0, intelligent manufacturing extensively employs sensors for real-time multidimensional data collection, playing a crucial role in equipment monitoring, process optimisation, and efficiency enhancement. Industrial data exhibit characteristics such as multi-source heterogeneity, nonlinearity, strong coupling, and temporal interactions, while also being affected by noise interference. These complexities make it challenging for traditional anomaly detection methods to extract key features, impacting detection accuracy and stability. Traditional machine learning approaches often struggle with such complex data due to limitations in processing capacity and generalisation ability, making them inadequate for practical applications. While deep learning feature extraction modules have demonstrated remarkable performance in image and text processing, they remain ineffective when applied to multi-source heterogeneous industrial data lacking explicit correlations. Moreover, existing multi-source heterogeneous data processing techniques still rely on dimensionality reduction and feature selection, which can lead to information loss and difficulty in capturing high-order interactions. To address these challenges, this study applies the EAPCR and Time-EAPCR models proposed in previous research and introduces a new model, Time-EAPCR-T, where Transformer replaces the LSTM module in the time-series processing component of Time-EAPCR. This modification effectively addresses multi-source data heterogeneity, facilitates efficient multi-source feature fusion, and enhances the temporal feature extraction capabilities of multi-source industrial data.Experimental results demonstrate that the proposed method outperforms existing approaches across four industrial datasets, highlighting its broad application potential.
Time-EAPCR: A Deep Learning-Based Novel Approach for Anomaly Detection Applied to the Environmental Field
Mar 12, 2025

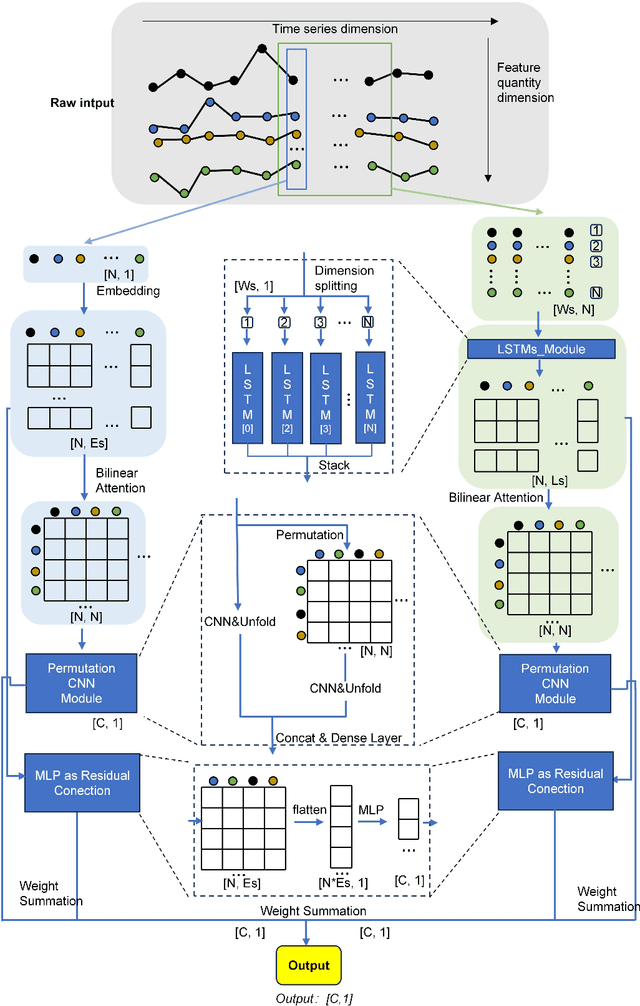

As human activities intensify, environmental systems such as aquatic ecosystems and water treatment systems face increasingly complex pressures, impacting ecological balance, public health, and sustainable development, making intelligent anomaly monitoring essential. However, traditional monitoring methods suffer from delayed responses, insufficient data processing capabilities, and weak generalisation, making them unsuitable for complex environmental monitoring needs.In recent years, machine learning has been widely applied to anomaly detection, but the multi-dimensional features and spatiotemporal dynamics of environmental ecological data, especially the long-term dependencies and strong variability in the time dimension, limit the effectiveness of traditional methods.Deep learning, with its ability to automatically learn features, captures complex nonlinear relationships, improving detection performance. However, its application in environmental monitoring is still in its early stages and requires further exploration.This paper introduces a new deep learning method, Time-EAPCR (Time-Embedding-Attention-Permutated CNN-Residual), and applies it to environmental science. The method uncovers feature correlations, captures temporal evolution patterns, and enables precise anomaly detection in environmental systems.We validated Time-EAPCR's high accuracy and robustness across four publicly available environmental datasets. Experimental results show that the method efficiently handles multi-source data, improves detection accuracy, and excels across various scenarios with strong adaptability and generalisation. Additionally, a real-world river monitoring dataset confirmed the feasibility of its deployment, providing reliable technical support for environmental monitoring.
Unsupervised Waste Classification By Dual-Encoder Contrastive Learning and Multi-Clustering Voting (DECMCV)
Mar 04, 2025



Waste classification is crucial for improving processing efficiency and reducing environmental pollution. Supervised deep learning methods are commonly used for automated waste classification, but they rely heavily on large labeled datasets, which are costly and inefficient to obtain. Real-world waste data often exhibit category and style biases, such as variations in camera angles, lighting conditions, and types of waste, which can impact the model's performance and generalization ability. Therefore, constructing a bias-free dataset is essential. Manual labeling is not only costly but also inefficient. While self-supervised learning helps address data scarcity, it still depends on some labeled data and generally results in lower accuracy compared to supervised methods. Unsupervised methods show potential in certain cases but typically do not perform as well as supervised models, highlighting the need for an efficient and cost-effective unsupervised approach. This study presents a novel unsupervised method, Dual-Encoder Contrastive Learning with Multi-Clustering Voting (DECMCV). The approach involves using a pre-trained ConvNeXt model for image encoding, leveraging VisionTransformer to generate positive samples, and applying a multi-clustering voting mechanism to address data labeling and domain shift issues. Experimental results demonstrate that DECMCV achieves classification accuracies of 93.78% and 98.29% on the TrashNet and Huawei Cloud datasets, respectively, outperforming or matching supervised models. On a real-world dataset of 4,169 waste images, only 50 labeled samples were needed to accurately label thousands, improving classification accuracy by 29.85% compared to supervised models. This method effectively addresses style differences, enhances model generalization, and contributes to the advancement of automated waste classification.