 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Backdoors Speak: Understanding LLM Backdoor Attacks Through Model-Generated Explanations
Nov 19, 2024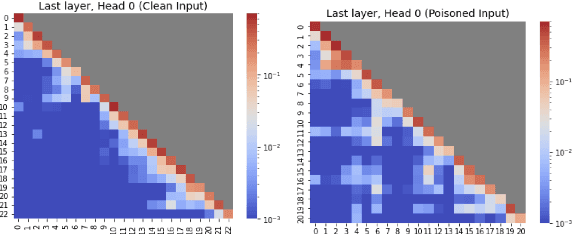



Large Language Models (LLMs) are vulnerable to backdoor attacks, where hidden triggers can maliciously manipulate model behavior. While several backdoor attack methods have been proposed, the mechanisms by which backdoor functions operate in LLMs remain underexplored. In this paper, we move beyond attacking LLMs and investigate backdoor functionality through the novel lens of natural language explanations. Specifically, we leverage LLMs' generative capabilities to produce human-understandable explanations for their decisions, allowing us to compare explanations for clean and poisoned samples. We explore various backdoor attacks and embed the backdoor into LLaMA models for multiple tasks. Our experiments show that backdoored models produce higher-quality explanations for clean data compared to poisoned data, while generating significantly more consistent explanations for poisoned data than for clean data. We further analyze the explanation generation process, revealing that at the token level, the explanation token of poisoned samples only appears in the final few transformer layers of the LLM. At the sentence level, attention dynamics indicate that poisoned inputs shift attention from the input context when generating the explanation. These findings deepen our understanding of backdoor attack mechanisms in LLMs and offer a framework for detecting such vulnerabilities through explainability techniques, contributing to the development of more secure LLMs.
How Well Can Knowledge Edit Methods Edit Perplexing Knowledge?
Jun 25, 2024As large language models (LLMs) are widely deployed, targeted editing of their knowledge has become a critical challenge. Recently, advancements in model editing techniques, such as Rank-One Model Editing (ROME), have paved the way for updating LLMs with new knowledge. However, the efficacy of these methods varies across different types of knowledge. This study investigates the capability of knowledge editing methods to incorporate new knowledge with varying degrees of "perplexingness", a term we use to describe the initial difficulty LLMs have in understanding new concepts. We begin by quantifying the "perplexingness" of target knowledge using pre-edit conditional probabilities, and assess the efficacy of edits through post-edit conditional probabilities. Utilizing the widely-used CounterFact dataset, we find significant negative correlations between the "perplexingness" of the new knowledge and the edit efficacy across all 12 scenarios. To dive deeper into this phenomenon, we introduce a novel dataset, HierarchyData, consisting of 99 hyponym-hypernym pairs across diverse categories. Our analysis reveal that more abstract concepts (hypernyms) tend to be more perplexing than their specific counterparts (hyponyms). Further exploration into the influence of knowledge hierarchy on editing outcomes indicates that knowledge positioned at higher hierarchical levels is more challenging to modify in some scenarios. Our research highlights a previously overlooked aspect of LLM editing: the variable efficacy of editing methods in handling perplexing knowledge. By revealing how hierarchical relationships can influence editing outcomes, our findings offer new insights into the challenges of updating LLMs and pave the way for more nuanced approaches to model editing in the future.
What Do the Circuits Mean? A Knowledge Edit View
Jun 25, 2024In the field of language model interpretability, circuit discovery is gaining popularity. Despite this, the true meaning of these circuits remain largely unanswered. We introduce a novel method to learn their meanings as a holistic object through the lens of knowledge editing. We extract circuits in the GPT2-XL model using diverse text classification datasets, and use hierarchical relations datasets to explore knowledge editing in the circuits. Our findings indicate that these circuits contain entity knowledge but resist new knowledge more than complementary circuits during knowledge editing. Additionally, we examine the impact of circuit size, discovering that an ideal "theoretical circuit" where essential knowledge is concentrated likely incorporates more than 5% but less than 50% of the model's parameters. We also assess the overlap between circuits from different datasets, finding moderate similarities. What constitutes these circuits, then? We find that up to 60% of the circuits consist of layer normalization modules rather than attention or MLP modules, adding evidence to the ongoing debates regarding knowledge localization. In summary, our findings offer new insights into the functions of the circuits, and introduce research directions for further interpretability and safety research of language models.