 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Backdoors Speak: Understanding LLM Backdoor Attacks Through Model-Generated Explanations
Paper and Code
Nov 19, 2024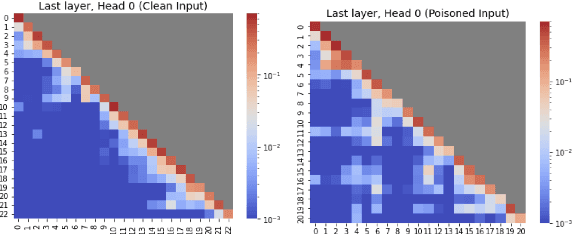



Large Language Models (LLMs) are vulnerable to backdoor attacks, where hidden triggers can maliciously manipulate model behavior. While several backdoor attack methods have been proposed, the mechanisms by which backdoor functions operate in LLMs remain underexplored. In this paper, we move beyond attacking LLMs and investigate backdoor functionality through the novel lens of natural language explanations. Specifically, we leverage LLMs' generative capabilities to produce human-understandable explanations for their decisions, allowing us to compare explanations for clean and poisoned samples. We explore various backdoor attacks and embed the backdoor into LLaMA models for multiple tasks. Our experiments show that backdoored models produce higher-quality explanations for clean data compared to poisoned data, while generating significantly more consistent explanations for poisoned data than for clean data. We further analyze the explanation generation process, revealing that at the token level, the explanation token of poisoned samples only appears in the final few transformer layers of the LLM. At the sentence level, attention dynamics indicate that poisoned inputs shift attention from the input context when generating the explanation. These findings deepen our understanding of backdoor attack mechanisms in LLMs and offer a framework for detecting such vulnerabilities through explainability techniques, contributing to the development of more secure LLMs.