 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate Descent Converges Faster with the Gauss-Southwell Rule Than Random Selection
Oct 28, 2018There has been significant recent work on the theory and application of randomized coordinate descent algorithms, beginning with the work of Nesterov [SIAM J. Optim., 22(2), 2012], who showed that a random-coordinate selection rule achieves the same convergence rate as the Gauss-Southwell selection rule. This result suggests that we should never use the Gauss-Southwell rule, as it is typically much more expensive than random selection. However, the empirical behaviours of these algorithms contradict this theoretical result: in applications where the computational costs of the selection rules are comparable, the Gauss-Southwell selection rule tends to perform substantially better than random coordinate selection. We give a simple analysis of the Gauss-Southwell rule showing that---except in extreme cases---its convergence rate is faster than choosing random coordinates. Further, in this work we (i) show that exact coordinate optimization improves the convergence rate for certain sparse problems, (ii) propose a Gauss-Southwell-Lipschitz rule that gives an even faster convergence rate given knowledge of the Lipschitz constants of the partial derivatives, (iii) analyze the effect of approximate Gauss-Southwell rules, and (iv) analyze proximal-gradient variants of the Gauss-Southwell rule.
An Algorithmic Theory of Dependent Regularizers, Part 1: Submodular Structure
Dec 06, 2013
We present an exploration of the rich theoretical connections between several classes of regularized models, network flows, and recent results in submodular function theory. This work unifies key aspects of these problems under a common theory, leading to novel methods for working with several important models of interest in statistics, machine learning and computer vision. In Part 1, we review the concepts of network flows and submodular function optimization theory foundational to our results. We then examine the connections between network flows and the minimum-norm algorithm from submodular optimization, extending and improving several current results. This leads to a concise representation of the structure of a large class of pairwise regularized models important in machine learning, statistics and computer vision. In Part 2, we describe the full regularization path of a class of penalized regression problems with dependent variables that includes the graph-guided LASSO and total variation constrained models. This description also motivates a practical algorithm. This allows us to efficiently find the regularization path of the discretized version of TV penalized models. Ultimately, our new algorithms scale up to high-dimensional problems with millions of variables.
Fast Prediction of New Feature Utility
Jun 18, 2012
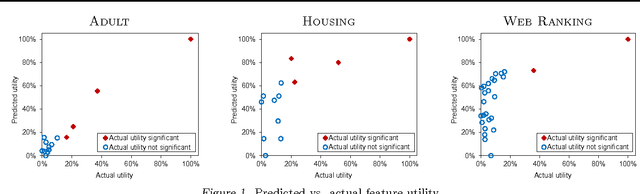
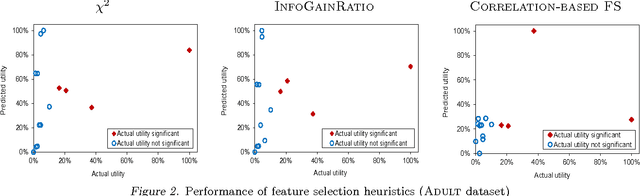
We study the new feature utility prediction problem: statistically testing whether adding a new feature to the data representation can improve predictive accuracy on a supervised learning task. In many applications, identifying new informative features is the primary pathway for improving performance. However, evaluating every potential feature by re-training the predictor with it can be costly. The paper describes an efficient, learner-independent technique for estimating new feature utility without re-training based on the current predictor's outputs. The method is obtained by deriving a connection between loss reduction potential and the new feature's correlation with the loss gradient of the current predictor. This leads to a simple yet powerful hypothesis testing procedure, for which we prove consistency. Our theoretical analysis is accompanied by empirical evaluation on standard benchmarks and a large-scale industrial dataset.