 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Prediction of New Feature Utility
Paper and Code
Jun 18, 2012
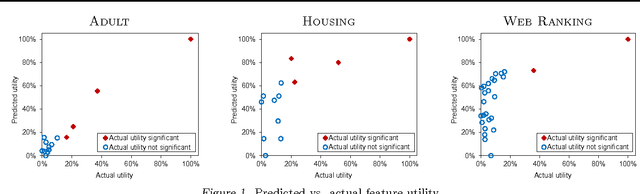
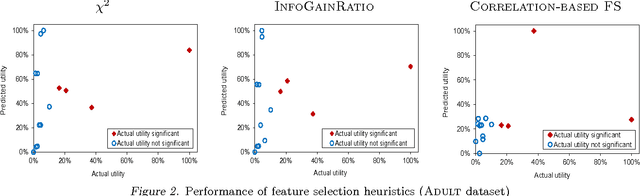
We study the new feature utility prediction problem: statistically testing whether adding a new feature to the data representation can improve predictive accuracy on a supervised learning task. In many applications, identifying new informative features is the primary pathway for improving performance. However, evaluating every potential feature by re-training the predictor with it can be costly. The paper describes an efficient, learner-independent technique for estimating new feature utility without re-training based on the current predictor's outputs. The method is obtained by deriving a connection between loss reduction potential and the new feature's correlation with the loss gradient of the current predictor. This leads to a simple yet powerful hypothesis testing procedure, for which we prove consistency. Our theoretical analysis is accompanied by empirical evaluation on standard benchmarks and a large-scale industrial dataset.