 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndowing Language Models with Multimodal Knowledge Graph Representations
Jun 27, 2022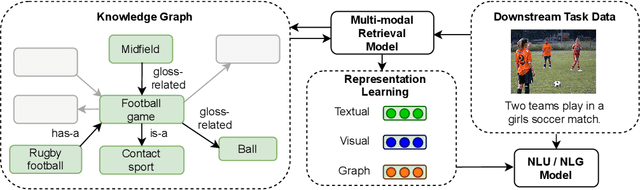
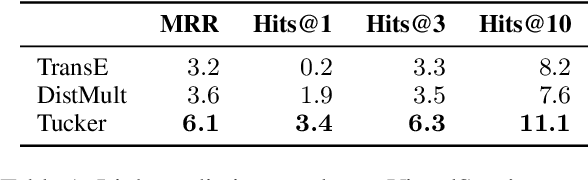
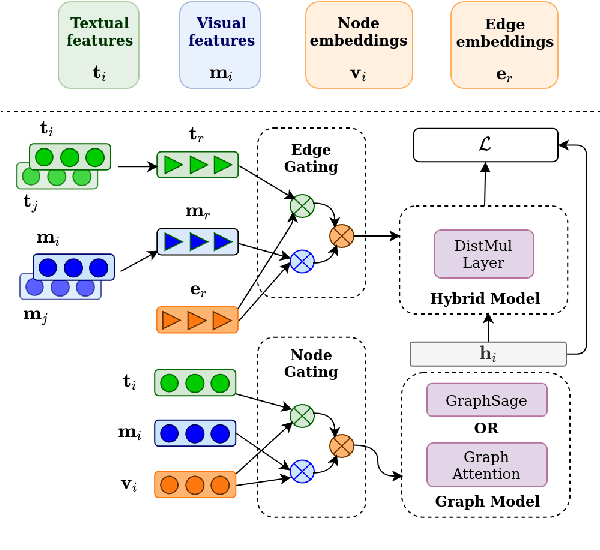
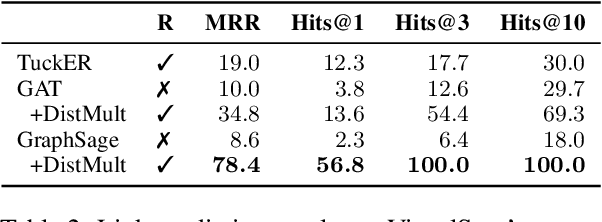
We propose a method to make natural language understanding models more parameter efficient by storing knowledge in an external knowledge graph (KG) and retrieving from this KG using a dense index. Given (possibly multilingual) downstream task data, e.g., sentences in German, we retrieve entities from the KG and use their multimodal representations to improve downstream task performance. We use the recently released VisualSem KG as our external knowledge repository, which covers a subset of Wikipedia and WordNet entities, and compare a mix of tuple-based and graph-based algorithms to learn entity and relation representations that are grounded on the KG multimodal information. We demonstrate the usefulness of the learned entity representations on two downstream tasks, and show improved performance on the multilingual named entity recognition task by $0.3\%$--$0.7\%$ F1, while we achieve up to $2.5\%$ improvement in accuracy on the visual sense disambiguation task. All our code and data are available in: \url{https://github.com/iacercalixto/visualsem-kg}.
ImagiFilter: A resource to enable the semi-automatic mining of images at scale
Aug 20, 2020
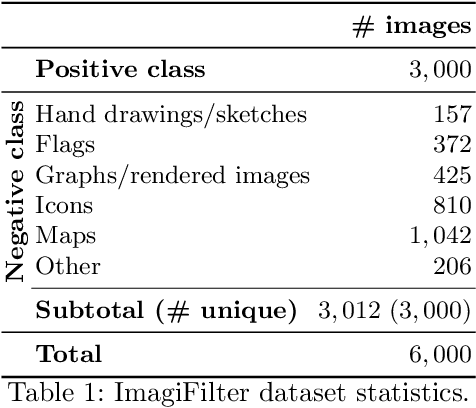
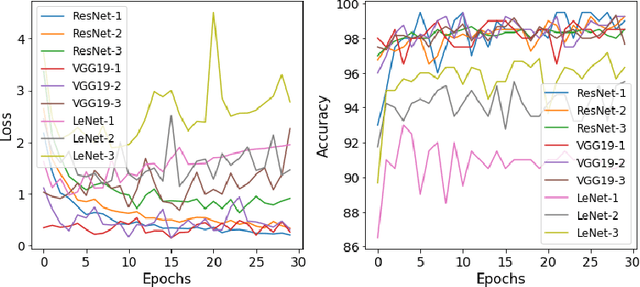
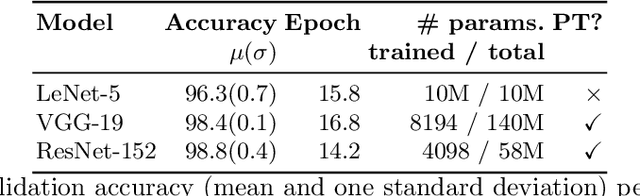
Datasets (semi-)automatically collected from the web can easily scale to millions of entries, but a dataset's usefulness is directly related to how clean and high-quality its examples are. In this paper, we describe and publicly release an image dataset along with pretrained models designed to (semi-)automatically filter out undesirable images from very large image collections, possibly obtained from the web. Our dataset focusses on photographic and/or natural images, a very common use-case in computer vision research. We provide annotations for coarse prediction, i.e. photographic vs. non-photographic, and smaller fine-grained prediction tasks where we further break down the non-photographic class into five classes: maps, drawings, graphs, icons, and sketches. Results on held out validation data show that a model architecture with reduced memory footprint achieves over 96% accuracy on coarse-prediction. Our best model achieves 88% accuracy on the hardest fine-grained classification task available. Dataset and pretrained models are available at: https://github.com/houda96/imagi-filter.
VisualSem: a high-quality knowledge graph for vision and language
Aug 20, 2020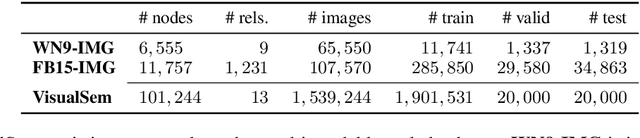


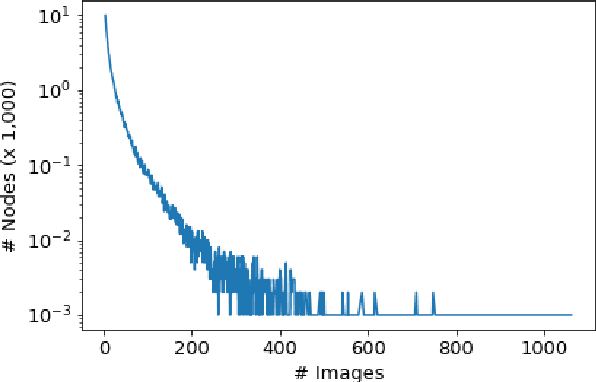
We argue that the next frontier in natural language understanding (NLU) and generation (NLG) will include models that can efficiently access external structured knowledge repositories. In order to support the development of such models, we release the VisualSem knowledge graph (KG) which includes nodes with multilingual glosses and multiple illustrative images and visually relevant relations. We also release a neural multi-modal retrieval model that can use images or sentences as inputs and retrieves entities in the KG. This multi-modal retrieval model can be integrated into any (neural network) model pipeline and we encourage the research community to use VisualSem for data augmentation and/or as a source of grounding, among other possible uses. VisualSem as well as the multi-modal retrieval model are publicly available and can be downloaded in: https://github.com/iacercalixto/visualsem.