 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagiFilter: A resource to enable the semi-automatic mining of images at scale
Paper and Code
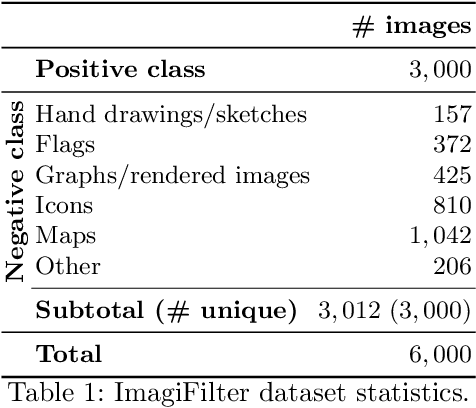
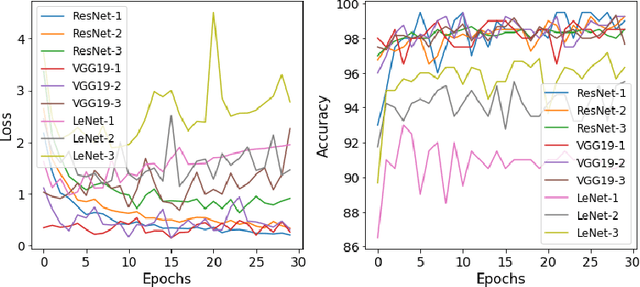
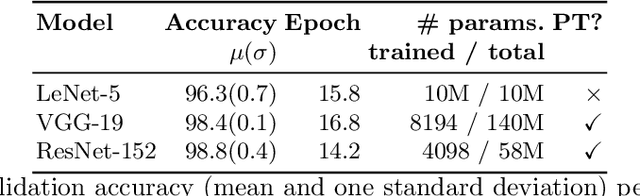
Datasets (semi-)automatically collected from the web can easily scale to millions of entries, but a dataset's usefulness is directly related to how clean and high-quality its examples are. In this paper, we describe and publicly release an image dataset along with pretrained models designed to (semi-)automatically filter out undesirable images from very large image collections, possibly obtained from the web. Our dataset focusses on photographic and/or natural images, a very common use-case in computer vision research. We provide annotations for coarse prediction, i.e. photographic vs. non-photographic, and smaller fine-grained prediction tasks where we further break down the non-photographic class into five classes: maps, drawings, graphs, icons, and sketches. Results on held out validation data show that a model architecture with reduced memory footprint achieves over 96% accuracy on coarse-prediction. Our best model achieves 88% accuracy on the hardest fine-grained classification task available. Dataset and pretrained models are available at: https://github.com/houda96/imagi-filter.