 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Evasion: Preventing Body Shape Inference of Multi-Stage Approaches
May 27, 2019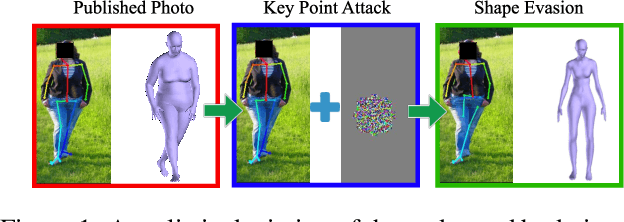



Modern approaches to pose and body shape estimation have recently achieved strong performance even under challenging real-world conditions. Even from a single image of a clothed person, a realistic looking body shape can be inferred that captures a users' weight group and body shape type well. This opens up a whole spectrum of applications -- in particular in fashion -- where virtual try-on and recommendation systems can make use of these new and automatized cues. However, a realistic depiction of the undressed body is regarded highly private and therefore might not be consented by most people. Hence, we ask if the automatic extraction of such information can be effectively evaded. While adversarial perturbations have been shown to be effective for manipulating the output of machine learning models -- in particular, end-to-end deep learning approaches -- state of the art shape estimation methods are composed of multiple stages. We perform the first investigation of different strategies that can be used to effectively manipulate the automatic shape estimation while preserving the overall appearance of the original image.
Fashion is Taking Shape: Understanding Clothing Preference Based on Body Shape From Online Sources
Jul 09, 2018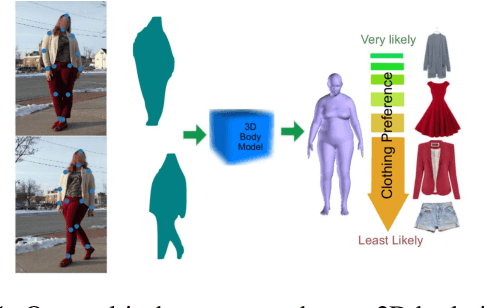
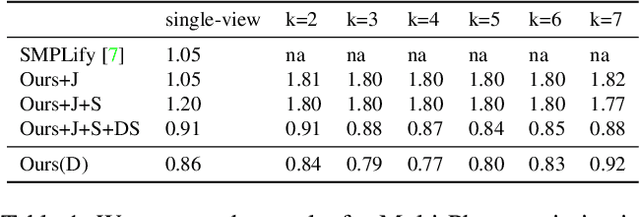
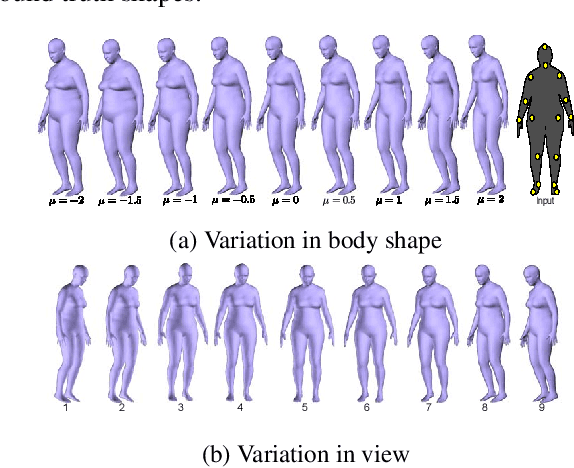
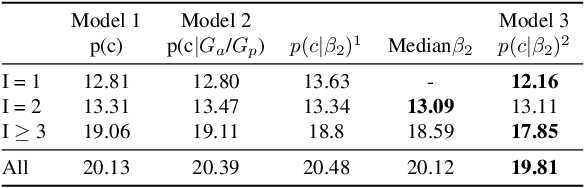
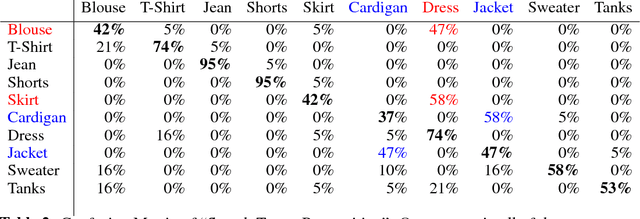
To study the correlation between clothing garments and body shape, we collected a new dataset (Fashion Takes Shape), which includes images of users with clothing category annotations. We employ our multi-photo approach to estimate body shapes of each user and build a conditional model of clothing categories given body-shape. We demonstrate that in real-world data, clothing categories and body-shapes are correlated and show that our multi-photo approach leads to a better predictive model for clothing categories compared to models based on single-view shape estimates or manually annotated body types. We see our method as the first step towards the large-scale understanding of clothing preferences from body shape.
Visual Decoding of Targets During Visual Search From Human Eye Fixations
Jun 21, 2017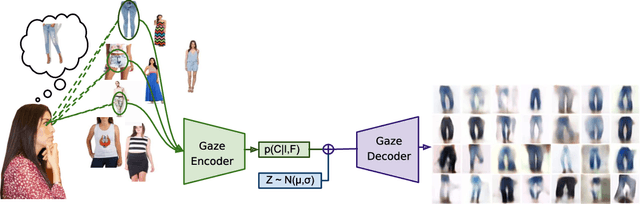


What does human gaze reveal about a users' intents and to which extend can these intents be inferred or even visualized? Gaze was proposed as an implicit source of information to predict the target of visual search and, more recently, to predict the object class and attributes of the search target. In this work, we go one step further and investigate the feasibility of combining recent advances in encoding human gaze information using deep convolutional neural networks with the power of generative image models to visually decode, i.e. create a visual representation of, the search target. Such visual decoding is challenging for two reasons: 1) the search target only resides in the user's mind as a subjective visual pattern, and can most often not even be described verbally by the person, and 2) it is, as of yet, unclear if gaze fixations contain sufficient information for this task at all. We show, for the first time, that visual representations of search targets can indeed be decoded only from human gaze fixations. We propose to first encode fixations into a semantic representation and then decode this representation into an image. We evaluate our method on a recent gaze dataset of 14 participants searching for clothing in image collages and validate the model's predictions using two human studies. Our results show that 62% (Chance level = 10%) of the time users were able to select the categories of the decoded image right. In our second studies we show the importance of a local gaze encoding for decoding visual search targets of user
Predicting the Category and Attributes of Visual Search Targets Using Deep Gaze Pooling
Apr 03, 2017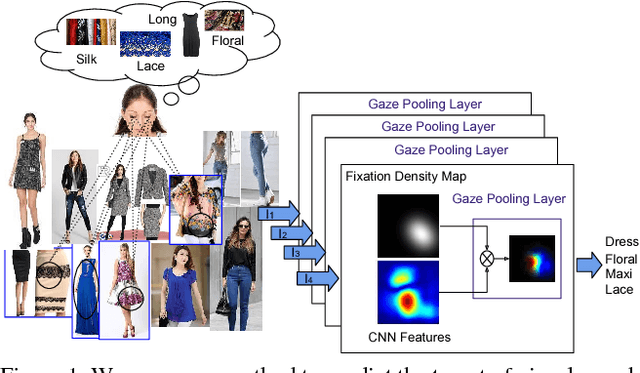
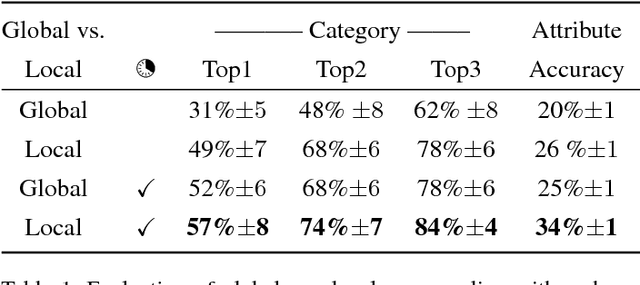

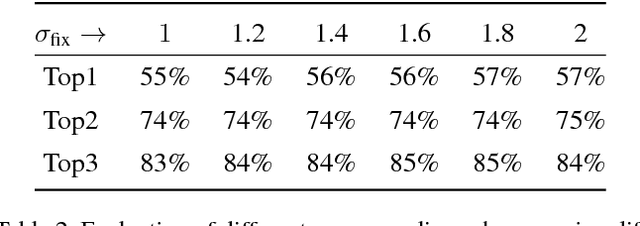
Predicting the target of visual search from eye fixation (gaze) data is a challenging problem with many applications in human-computer interaction. In contrast to previous work that has focused on individual instances as a search target, we propose the first approach to predict categories and attributes of search targets based on gaze data. However, state of the art models for categorical recognition, in general, require large amounts of training data, which is prohibitive for gaze data. To address this challenge, we propose a novel Gaze Pooling Layer that integrates gaze information into CNN-based architectures as an attention mechanism - incorporating both spatial and temporal aspects of human gaze behavior. We show that our approach is effective even when the gaze pooling layer is added to an already trained CNN, thus eliminating the need for expensive joint data collection of visual and gaze data. We propose an experimental setup and data set and demonstrate the effectiveness of our method for search target prediction based on gaze behavior. We further study how to integrate temporal and spatial gaze information most effectively, and indicate directions for future research in the gaze-based prediction of mental states.
Prediction of Search Targets From Fixations in Open-World Settings
Apr 11, 2015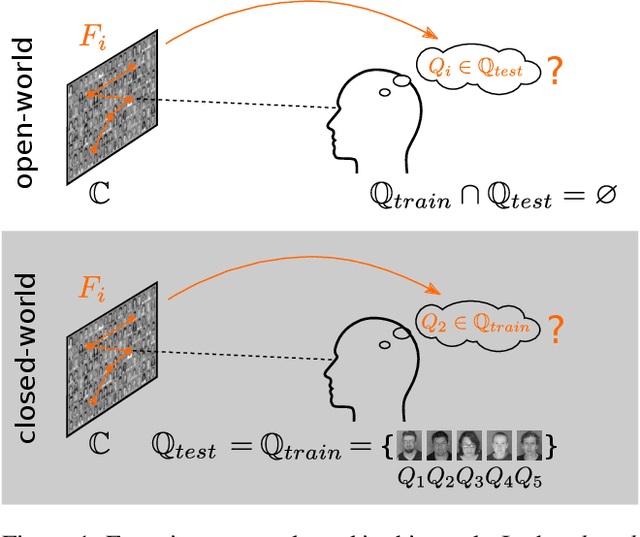


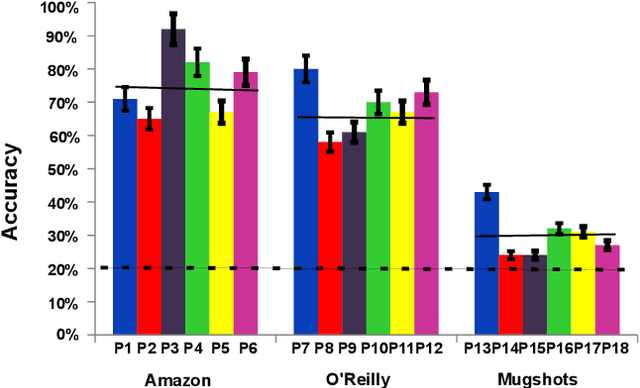
Previous work on predicting the target of visual search from human fixations only considered closed-world settings in which training labels are available and predictions are performed for a known set of potential targets. In this work we go beyond the state of the art by studying search target prediction in an open-world setting in which we no longer assume that we have fixation data to train for the search targets. We present a dataset containing fixation data of 18 users searching for natural images from three image categories within synthesised image collages of about 80 images. In a closed-world baseline experiment we show that we can predict the correct target image out of a candidate set of five images. We then present a new problem formulation for search target prediction in the open-world setting that is based on learning compatibilities between fixations and potential targets.