 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Decoding of Targets During Visual Search From Human Eye Fixations
Paper and Code
Jun 21, 2017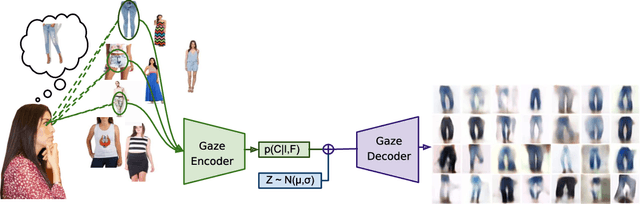


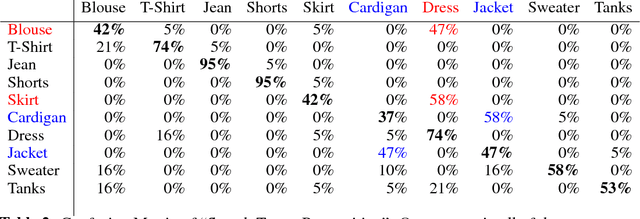
What does human gaze reveal about a users' intents and to which extend can these intents be inferred or even visualized? Gaze was proposed as an implicit source of information to predict the target of visual search and, more recently, to predict the object class and attributes of the search target. In this work, we go one step further and investigate the feasibility of combining recent advances in encoding human gaze information using deep convolutional neural networks with the power of generative image models to visually decode, i.e. create a visual representation of, the search target. Such visual decoding is challenging for two reasons: 1) the search target only resides in the user's mind as a subjective visual pattern, and can most often not even be described verbally by the person, and 2) it is, as of yet, unclear if gaze fixations contain sufficient information for this task at all. We show, for the first time, that visual representations of search targets can indeed be decoded only from human gaze fixations. We propose to first encode fixations into a semantic representation and then decode this representation into an image. We evaluate our method on a recent gaze dataset of 14 participants searching for clothing in image collages and validate the model's predictions using two human studies. Our results show that 62% (Chance level = 10%) of the time users were able to select the categories of the decoded image right. In our second studies we show the importance of a local gaze encoding for decoding visual search targets of user