 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Secure Retrieval-Augmented Generation: A Comprehensive Review of Threats, Defenses and Benchmarks
Mar 23, 2026Retrieval-Augmented Generation (RAG) significantly mitigates the hallucinations and domain knowledge deficiency in large language models by incorporating external knowledge bases. However, the multi-module architecture of RAG introduces complex system-level security vulnerabilities. Guided by the RAG workflow, this paper analyzes the underlying vulnerability mechanisms and systematically categorizes core threat vectors such as data poisoning, adversarial attacks, and membership inference attacks. Based on this threat assessment, we construct a taxonomy of RAG defense technologies from a dual perspective encompassing both input and output stages. The input-side analysis reviews data protection mechanisms including dynamic access control, homomorphic encryption retrieval, and adversarial pre-filtering. The output-side examination summarizes advanced leakage prevention techniques such as federated learning isolation, differential privacy perturbation, and lightweight data sanitization. To establish a unified benchmark for future experimental design, we consolidate authoritative test datasets, security standards, and evaluation frameworks. To the best of our knowledge, this paper presents the first end-to-end survey dedicated to the security of RAG systems. Distinct from existing literature that isolates specific vulnerabilities, we systematically map the entire pipeline-providing a unified analysis of threat models, defense mechanisms, and evaluation benchmarks. By enabling deep insights into potential risks, this work seeks to foster the development of highly robust and trustworthy next-generation RAG systems.
Cross-Modal ASR Post-Processing System for Error Correction and Utterance Rejection
Jan 10, 2022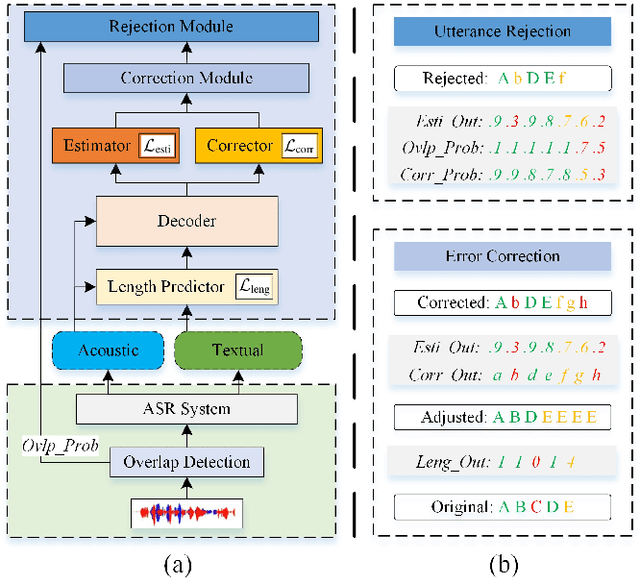

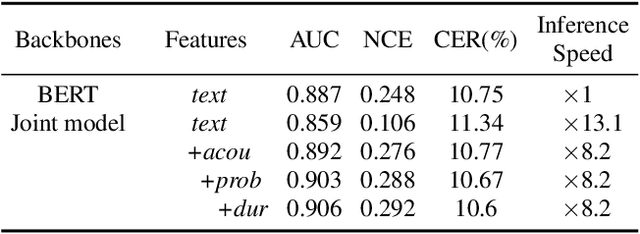
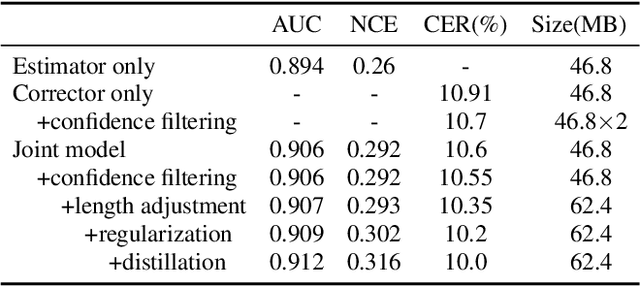
Although modern automatic speech recognition (ASR) systems can achieve high performance, they may produce errors that weaken readers' experience and do harm to downstream tasks. To improve the accuracy and reliability of ASR hypotheses, we propose a cross-modal post-processing system for speech recognizers, which 1) fuses acoustic features and textual features from different modalities, 2) joints a confidence estimator and an error corrector in multi-task learning fashion and 3) unifies error correction and utterance rejection modules. Compared with single-modal or single-task models, our proposed system is proved to be more effective and efficient. Experiment result shows that our post-processing system leads to more than 10% relative reduction of character error rate (CER) for both single-speaker and multi-speaker speech on our industrial ASR system, with about 1.7ms latency for each token, which ensures that extra latency introduced by post-processing is acceptable in streaming speech recognition.
Financial Market Directional Forecasting With Stacked Denoising Autoencoder
Dec 02, 2019
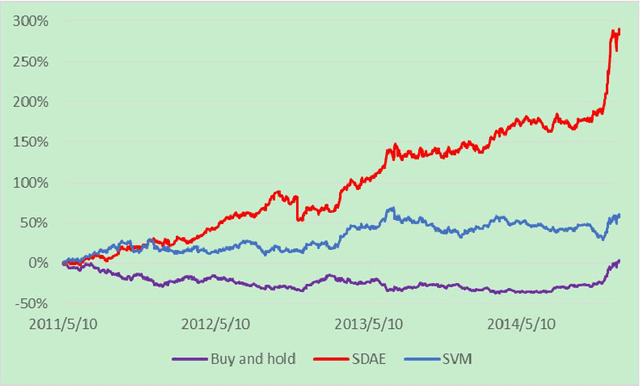

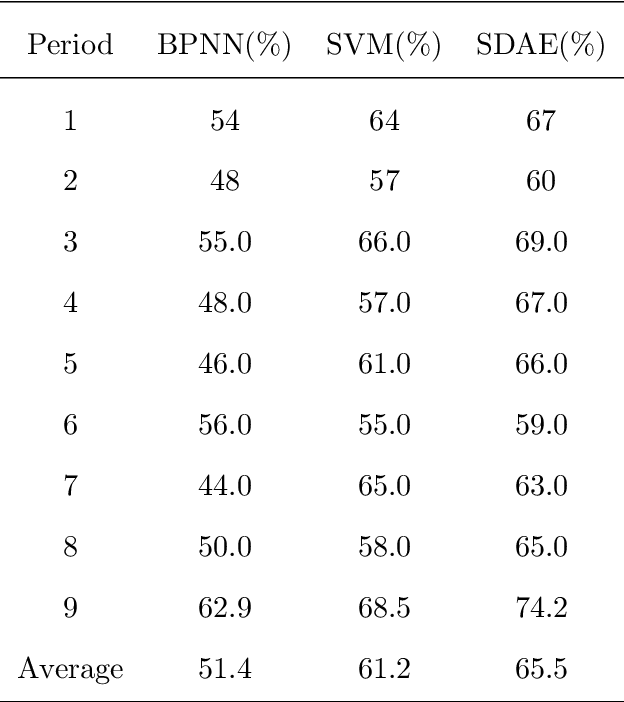
Forecasting stock market direction is always an amazing but challenging problem in finance. Although many popular shallow computational methods (such as Backpropagation Network and Support Vector Machine) have extensively been proposed, most algorithms have not yet attained a desirable level of applicability. In this paper, we present a deep learning model with strong ability to generate high level feature representations for accurate financial prediction. Precisely, a stacked denoising autoencoder (SDAE) from deep learning is applied to predict the daily CSI 300 index, from Shanghai and Shenzhen Stock Exchanges in China. We use six evaluation criteria to evaluate its performance compared with the back propagation network, support vector machine. The experiment shows that the underlying financial model with deep machine technology has a significant advantage for the prediction of the CSI 300 index.