 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGNet: A Multi-Scale Attention-Guided Graph Fusion Network for DRC Violation Detection
Jun 08, 2025Design rule checking (DRC) is of great significance for cost reduction and design efficiency improvement in integrated circuit (IC) designs. Machine-learning-based DRC has become an important approach in computer-aided design (CAD). In this paper, we propose MAGNet, a hybrid deep learning model that integrates an improved U-Net with a graph neural network for DRC violation prediction. The U-Net backbone is enhanced with a Dynamic Attention Module (DAM) and a Multi-Scale Convolution Module (MSCM) to strengthen its capability in extracting fine-grained and multi-scale spatial features. In parallel, we construct a pixel-aligned graph structure based on chip layout tiles, and apply a specialized GNN to model the topological relationships among pins. During graph construction, a graph-to-grid mapping is generated to align GNN features with the layout image. In addition, a label amplification strategy is adopted during training to enhance the model's sensitivity to sparse violation patterns. Overall, MAGNet effectively combines spatial, semantic, and structural information, achieving improved prediction accuracy and reduced false positive rates in DRC hotspot detection. Subsequently, through incremental training, we achieve a more sensitive discrimination ability for hotspots. The results demonstrate that, in comparison with ibUnet, RouteNet, and J-Net, MAGnet significantly outperforms these models, achieving substantial improvements in overall performance.
Hybrid Time-Domain Behavior Model Based on Neural Differential Equations and RNNs
Mar 28, 2025



Nonlinear dynamics system identification is crucial for circuit emulation. Traditional continuous-time domain modeling approaches have limitations in fitting capability and computational efficiency when used for modeling circuit IPs and device behaviors.This paper presents a novel continuous-time domain hybrid modeling paradigm. It integrates neural network differential models with recurrent neural networks (RNNs), creating NODE-RNN and NCDE-RNN models based on neural ordinary differential equations (NODE) and neural controlled differential equations (NCDE), respectively.Theoretical analysis shows that this hybrid model has mathematical advantages in event-driven dynamic mutation response and gradient propagation stability. Validation using real data from PIN diodes in high-power microwave environments shows NCDE-RNN improves fitting accuracy by 33\% over traditional NCDE, and NODE-RNN by 24\% over CTRNN, especially in capturing nonlinear memory effects.The model has been successfully deployed in Verilog-A and validated through circuit emulation, confirming its compatibility with existing platforms and practical value.This hybrid dynamics paradigm, by restructuring the neural differential equation solution path, offers new ideas for high-precision circuit time-domain modeling and is significant for complex nonlinear circuit system modeling.
Neural Network Graph Similarity Computation Based on Graph Fusion
Feb 25, 2025Graph similarity learning, crucial for tasks such as graph classification and similarity search, focuses on measuring the similarity between two graph-structured entities. The core challenge in this field is effectively managing the interactions between graphs. Traditional methods often entail separate, redundant computations for each graph pair, leading to unnecessary complexity. This paper revolutionizes the approach by introducing a parallel graph interaction method called graph fusion. By merging the node sequences of graph pairs into a single large graph, our method leverages a global attention mechanism to facilitate interaction computations and to harvest cross-graph insights. We further assess the similarity between graph pairs at two distinct levels-graph-level and node-level-introducing two innovative, yet straightforward, similarity computation algorithms. Extensive testing across five public datasets shows that our model not only outperforms leading baseline models in graph-to-graph classification and regression tasks but also sets a new benchmark for performance and efficiency. The code for this paper is open-source and available at https://github.com/LLiRarry/GFM-code.git
Advanced Chain-of-Thought Reasoning for Parameter Extraction from Documents Using Large Language Models
Feb 23, 2025Extracting parameters from technical documentation is crucial for ensuring design precision and simulation reliability in electronic design. However, current methods struggle to handle high-dimensional design data and meet the demands of real-time processing. In electronic design automation (EDA), engineers often manually search through extensive documents to retrieve component parameters required for constructing PySpice models, a process that is both labor-intensive and time-consuming. To address this challenge, we propose an innovative framework that leverages large language models (LLMs) to automate the extraction of parameters and the generation of PySpice models directly from datasheets. Our framework introduces three Chain-of-Thought (CoT) based techniques: (1) Targeted Document Retrieval (TDR), which enables the rapid identification of relevant technical sections; (2) Iterative Retrieval Optimization (IRO), which refines the parameter search through iterative improvements; and (3) Preference Optimization (PO), which dynamically prioritizes key document sections based on relevance. Experimental results show that applying all three methods together improves retrieval precision by 47.69% and reduces processing latency by 37.84%. Furthermore, effect size analysis using Cohen's d reveals that PO significantly reduces latency, while IRO contributes most to precision enhancement. These findings underscore the potential of our framework to streamline EDA processes, enhance design accuracy, and shorten development timelines. Additionally, our algorithm has model-agnostic generalization, meaning it can improve parameter search performance across different LLMs.
EDocNet: Efficient Datasheet Layout Analysis Based on Focus and Global Knowledge Distillation
Feb 23, 2025



When designing circuits, engineers obtain the information of electronic devices by browsing a large number of documents, which is low efficiency and heavy workload. The use of artificial intelligence technology to automatically parse documents can greatly improve the efficiency of engineers. However, the current document layout analysis model is aimed at various types of documents and is not suitable for electronic device documents. This paper proposes to use EDocNet to realize the document layout analysis function for document analysis, and use the electronic device document data set created by myself for training. The training method adopts the focus and global knowledge distillation method, and a model suitable for electronic device documents is obtained, which can divide the contents of electronic device documents into 21 categories. It has better average accuracy and average recall rate. It also greatly improves the speed of model checking.
Seminar Learning for Click-Level Weakly Supervised Semantic Segmentation
Aug 30, 2021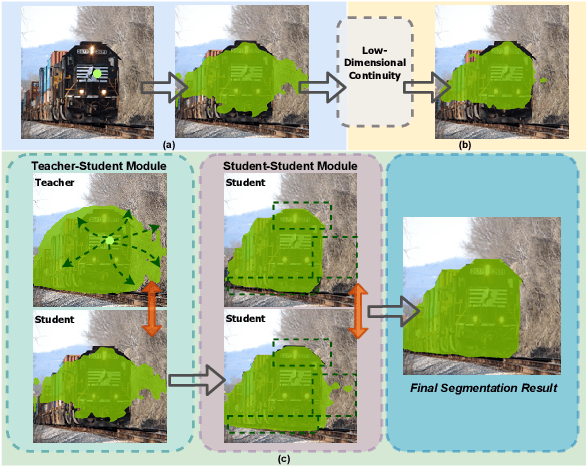
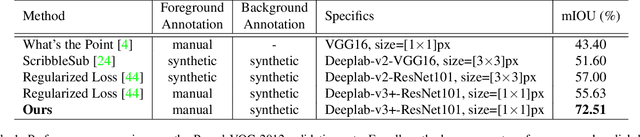

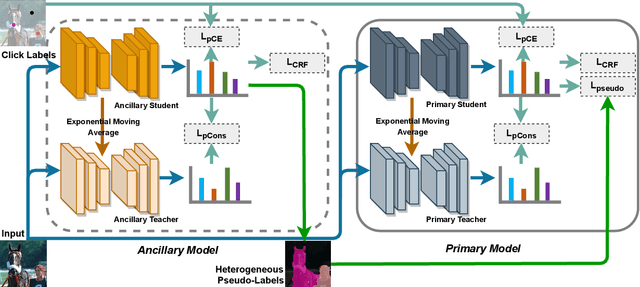
Annotation burden has become one of the biggest barriers to semantic segmentation. Approaches based on click-level annotations have therefore attracted increasing attention due to their superior trade-off between supervision and annotation cost. In this paper, we propose seminar learning, a new learning paradigm for semantic segmentation with click-level supervision. The fundamental rationale of seminar learning is to leverage the knowledge from different networks to compensate for insufficient information provided in click-level annotations. Mimicking a seminar, our seminar learning involves a teacher-student and a student-student module, where a student can learn from both skillful teachers and other students. The teacher-student module uses a teacher network based on the exponential moving average to guide the training of the student network. In the student-student module, heterogeneous pseudo-labels are proposed to bridge the transfer of knowledge among students to enhance each other's performance. Experimental results demonstrate the effectiveness of seminar learning, which achieves the new state-of-the-art performance of 72.51% (mIOU), surpassing previous methods by a large margin of up to 16.88% on the Pascal VOC 2012 dataset.