 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopeland Dueling Bandit Problem: Regret Lower Bound, Optimal Algorithm, and Computationally Efficient Algorithm
May 24, 2016
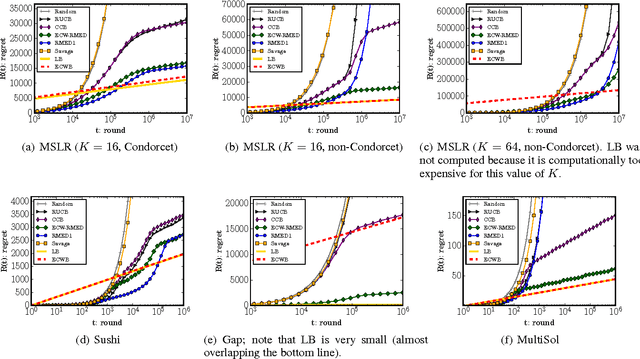


We study the K-armed dueling bandit problem, a variation of the standard stochastic bandit problem where the feedback is limited to relative comparisons of a pair of arms. The hardness of recommending Copeland winners, the arms that beat the greatest number of other arms, is characterized by deriving an asymptotic regret bound. We propose Copeland Winners Relative Minimum Empirical Divergence (CW-RMED) and derive an asymptotically optimal regret bound for it. However, it is not known whether the algorithm can be efficiently computed or not. To address this issue, we devise an efficient version (ECW-RMED) and derive its asymptotic regret bound. Experimental comparisons of dueling bandit algorithms show that ECW-RMED significantly outperforms existing ones.
Optimal Regret Analysis of Thompson Sampling in Stochastic Multi-armed Bandit Problem with Multiple Plays
May 24, 2016


We discuss a multiple-play multi-armed bandit (MAB) problem in which several arms are selected at each round. Recently, Thompson sampling (TS), a randomized algorithm with a Bayesian spirit, has attracted much attention for its empirically excellent performance, and it is revealed to have an optimal regret bound in the standard single-play MAB problem. In this paper, we propose the multiple-play Thompson sampling (MP-TS) algorithm, an extension of TS to the multiple-play MAB problem, and discuss its regret analysis. We prove that MP-TS for binary rewards has the optimal regret upper bound that matches the regret lower bound provided by Anantharam et al. (1987). Therefore, MP-TS is the first computationally efficient algorithm with optimal regret. A set of computer simulations was also conducted, which compared MP-TS with state-of-the-art algorithms. We also propose a modification of MP-TS, which is shown to have better empirical performance.
Regret Lower Bound and Optimal Algorithm in Finite Stochastic Partial Monitoring
Sep 30, 2015
Partial monitoring is a general model for sequential learning with limited feedback formalized as a game between two players. In this game, the learner chooses an action and at the same time the opponent chooses an outcome, then the learner suffers a loss and receives a feedback signal. The goal of the learner is to minimize the total loss. In this paper, we study partial monitoring with finite actions and stochastic outcomes. We derive a logarithmic distribution-dependent regret lower bound that defines the hardness of the problem. Inspired by the DMED algorithm (Honda and Takemura, 2010) for the multi-armed bandit problem, we propose PM-DMED, an algorithm that minimizes the distribution-dependent regret. PM-DMED significantly outperforms state-of-the-art algorithms in numerical experiments. To show the optimality of PM-DMED with respect to the regret bound, we slightly modify the algorithm by introducing a hinge function (PM-DMED-Hinge). Then, we derive an asymptotically optimal regret upper bound of PM-DMED-Hinge that matches the lower bound.
Regret Lower Bound and Optimal Algorithm in Dueling Bandit Problem
Jun 29, 2015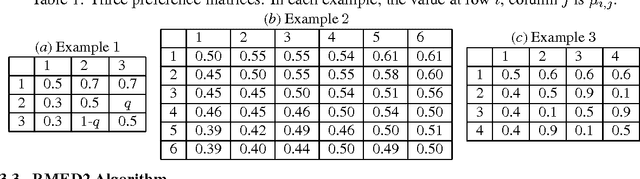
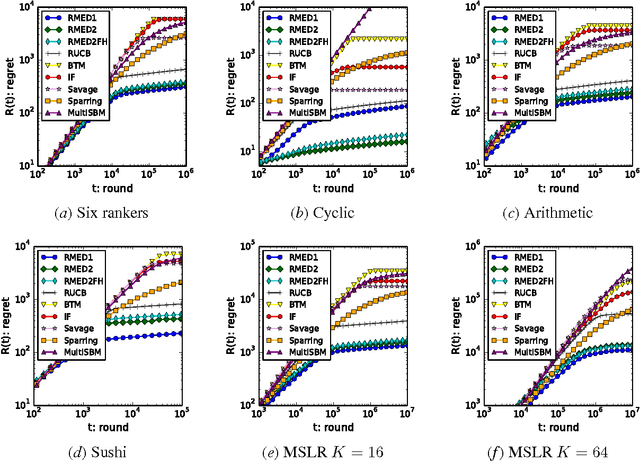
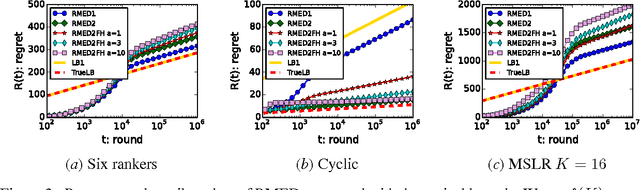

We study the $K$-armed dueling bandit problem, a variation of the standard stochastic bandit problem where the feedback is limited to relative comparisons of a pair of arms. We introduce a tight asymptotic regret lower bound that is based on the information divergence. An algorithm that is inspired by the Deterministic Minimum Empirical Divergence algorithm (Honda and Takemura, 2010) is proposed, and its regret is analyzed. The proposed algorithm is found to be the first one with a regret upper bound that matches the lower bound. Experimental comparisons of dueling bandit algorithms show that the proposed algorithm significantly outperforms existing ones.
Quantum Annealing for Variational Bayes Inference
Aug 09, 2014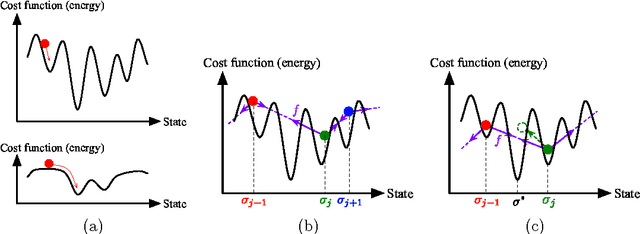
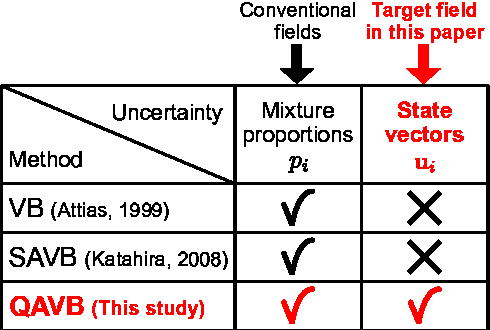
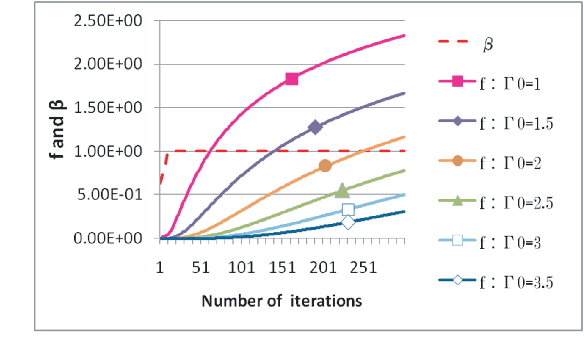
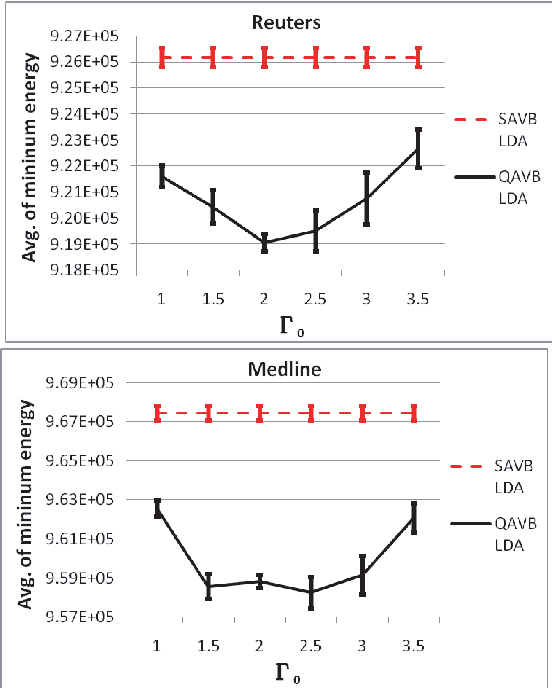
This paper presents studies on a deterministic annealing algorithm based on quantum annealing for variational Bayes (QAVB) inference, which can be seen as an extension of the simulated annealing for variational Bayes (SAVB) inference. QAVB is as easy as SAVB to implement. Experiments revealed QAVB finds a better local optimum than SAVB in terms of the variational free energy in latent Dirichlet allocation (LDA).
Quantum Annealing for Dirichlet Process Mixture Models with Applications to Network Clustering
May 19, 2013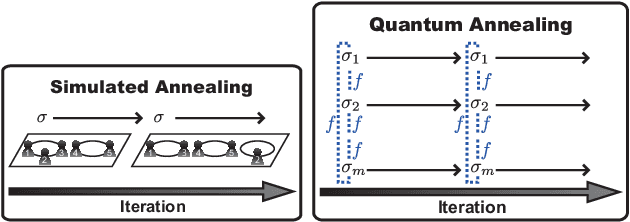


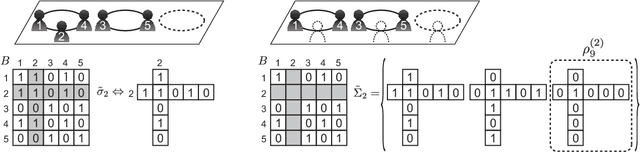
We developed a new quantum annealing (QA) algorithm for Dirichlet process mixture (DPM) models based on the Chinese restaurant process (CRP). QA is a parallelized extension of simulated annealing (SA), i.e., it is a parallel stochastic optimization technique. Existing approaches [Kurihara et al. UAI2009, Sato et al. UAI2009] and cannot be applied to the CRP because their QA framework is formulated using a fixed number of mixture components. The proposed QA algorithm can handle an unfixed number of classes in mixture models. We applied QA to a DPM model for clustering vertices in a network where a CRP seating arrangement indicates a network partition. A multi core processor was used for running QA in experiments, the results of which show that QA is better than SA, Markov chain Monte Carlo inference, and beam search at finding a maximum a posteriori estimation of a seating arrangement in the CRP. Since our QA algorithm is as easy as to implement the SA algorithm, it is suitable for a wide range of applications.
* 12 pages, 6 figures, accepted in Neurocomputing
Rethinking Collapsed Variational Bayes Inference for LDA
Jun 27, 2012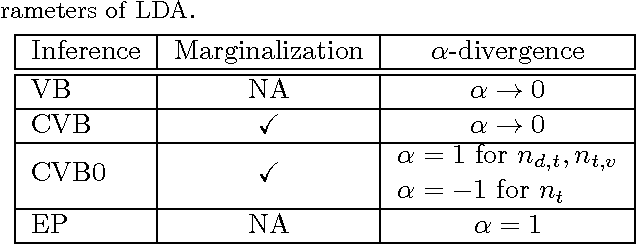
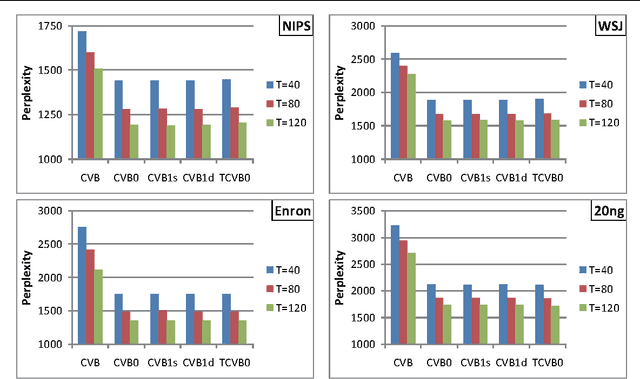
We propose a novel interpretation of the collapsed variational Bayes inference with a zero-order Taylor expansion approximation, called CVB0 inference, for latent Dirichlet allocation (LDA). We clarify the properties of the CVB0 inference by using the alpha-divergence. We show that the CVB0 inference is composed of two different divergence projections: alpha=1 and -1. This interpretation will help shed light on CVB0 works.
Semantics of Complex Sentences in Japanese
May 28, 1994


The important part of semantics of complex sentence is captured as relations among semantic roles in subordinate and main clause respectively. However if there can be relations between every pair of semantic roles, the amount of computation to identify the relations that hold in the given sentence is extremely large. In this paper, for semantics of Japanese complex sentence, we introduce new pragmatic roles called `observer' and `motivated' respectively to bridge semantic roles of subordinate and those of main clauses. By these new roles constraints on the relations among semantic/pragmatic roles are known to be almost local within subordinate or main clause. In other words, as for the semantics of the whole complex sentence, the only role we should deal with is a motivated.