 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving FMQA via Initial Training Data Design Considering Marginal Bit Coverage in One-Hot Encoding
May 06, 2026Factorization machine with quadratic-optimization annealing (FMQA) is a black-box optimization method that combines a factorization machine (FM) surrogate with QUBO-based search by an Ising machine. When FMQA is applied to integer or discretized continuous variables via one-hot encoding, uniform random initial sampling can leave many binary variables never active in the initial training data, and the corresponding FM parameters receive no direct gradient updates from the observed responses. We address this by designing the initial training data to achieve complete marginal bit coverage, namely, ensuring that every binary variable obtained by one-hot encoding takes the value one at least once. We use two space-filling sampling methods, Latin hypercube sampling (LHS) and the Sobol' sequence, yielding LHS-FMQA and Sobol'-FMQA. On the human-powered aircraft wing-shape optimization benchmark with 17 and 32 design variables, both proposed methods achieved numerically higher mean final cruising speeds than the baseline FMQA, with the advantage more pronounced on the 32-variable problem.
Factorization Machine with Quadratic-Optimization Annealing for RNA Inverse Folding and Evaluation of Binary-Integer Encoding and Nucleotide Assignment
Feb 18, 2026The RNA inverse folding problem aims to identify nucleotide sequences that preferentially adopt a given target secondary structure. While various heuristic and machine learning-based approaches have been proposed, many require a large number of sequence evaluations, which limits their applicability when experimental validation is costly. We propose a method to solve the problem using a factorization machine with quadratic-optimization annealing (FMQA). FMQA is a discrete black-box optimization method reported to obtain high-quality solutions with a limited number of evaluations. Applying FMQA to the problem requires converting nucleotides into binary variables. However, the influence of integer-to-nucleotide assignments and binary-integer encoding on the performance of FMQA has not been thoroughly investigated, even though such choices determine the structure of the surrogate model and the search landscape, and thus can directly affect solution quality. Therefore, this study aims both to establish a novel FMQA framework for RNA inverse folding and to analyze the effects of these assignments and encoding methods. We evaluated all 24 possible assignments of the four nucleotides to the ordered integers (0-3), in combination with four binary-integer encoding methods. Our results demonstrated that one-hot and domain-wall encodings outperform binary and unary encodings in terms of the normalized ensemble defect value. In domain-wall encoding, nucleotides assigned to the boundary integers (0 and 3) appeared with higher frequency. In the RNA inverse folding problem, assigning guanine and cytosine to these boundary integers promoted their enrichment in stem regions, which led to more thermodynamically stable secondary structures than those obtained with one-hot encoding.
Effectiveness of Binary Autoencoders for QUBO-Based Optimization Problems
Feb 10, 2026In black-box combinatorial optimization, objective evaluations are often expensive, so high quality solutions must be found under a limited budget. Factorization machine with quantum annealing (FMQA) builds a quadratic surrogate model from evaluated samples and optimizes it on an Ising machine. However, FMQA requires binary decision variables, and for nonbinary structures such as integer permutations, the choice of binary encoding strongly affects search efficiency. If the encoding fails to reflect the original neighborhood structure, small Hamming moves may not correspond to meaningful modifications in the original solution space, and constrained problems can yield many infeasible candidates that waste evaluations. Recent work combines FMQA with a binary autoencoder (bAE) that learns a compact binary latent code from feasible solutions, yet the mechanism behind its performance gains is unclear. Using a small traveling salesman problem as an interpretable testbed, we show that the bAE reconstructs feasible tours accurately and, compared with manually designed encodings at similar compression, better aligns tour distances with latent Hamming distances, yields smoother neighborhoods under small bit flips, and produces fewer local optima. These geometric properties explain why bAE+FMQA improves the approximation ratio faster while maintaining feasibility throughout optimization, and they provide guidance for designing latent representations for black-box optimization.
High-Order Epistasis Detection Using Factorization Machine with Quadratic Optimization Annealing and MDR-Based Evaluation
Jan 05, 2026Detecting high-order epistasis is a fundamental challenge in genetic association studies due to the combinatorial explosion of candidate locus combinations. Although multifactor dimensionality reduction (MDR) is a widely used method for evaluating epistasis, exhaustive MDR-based searches become computationally infeasible as the number of loci or the interaction order increases. In this paper, we define the epistasis detection problem as a black-box optimization problem and solve it with a factorization machine with quadratic optimization annealing (FMQA). We propose an efficient epistasis detection method based on FMQA, in which the classification error rate (CER) computed by MDR is used as a black-box objective function. Experimental evaluations were conducted using simulated case-control datasets with predefined high-order epistasis. The results demonstrate that the proposed method successfully identified ground-truth epistasis across various interaction orders and the numbers of genetic loci within a limited number of iterations. These results indicate that the proposed method is effective and computationally efficient for high-order epistasis detection.
Statistics of Min-max Normalized Eigenvalues in Random Matrices
Dec 17, 2025Random matrix theory has played an important role in various areas of pure mathematics, mathematical physics, and machine learning. From a practical perspective of data science, input data are usually normalized prior to processing. Thus, this study investigates the statistical properties of min-max normalized eigenvalues in random matrices. Previously, the effective distribution for such normalized eigenvalues has been proposed. In this study, we apply it to evaluate a scaling law of the cumulative distribution. Furthermore, we derive the residual error that arises during matrix factorization of random matrices. We conducted numerical experiments to verify these theoretical predictions.
Optimization Performance of Factorization Machine with Annealing under Limited Training Data
Jul 28, 2025Black-box (BB) optimization problems aim to identify an input that minimizes the output of a function (the BB function) whose input-output relationship is unknown. Factorization machine with annealing (FMA) is a promising approach to this task, employing a factorization machine (FM) as a surrogate model to iteratively guide the solution search via an Ising machine. Although FMA has demonstrated strong optimization performance across various applications, its performance often stagnates as the number of optimization iterations increases. One contributing factor to this stagnation is the growing number of data points in the dataset used to train FM. It is hypothesized that as more data points are accumulated, the contribution of newly added data points becomes diluted within the entire dataset, thereby reducing their impact on improving the prediction accuracy of FM. To address this issue, we propose a novel method for sequential dataset construction that retains at most a specified number of the most recently added data points. This strategy is designed to enhance the influence of newly added data points on the surrogate model. Numerical experiments demonstrate that the proposed FMA achieves lower-cost solutions with fewer BB function evaluations compared to the conventional FMA.
Systematic and Efficient Construction of Quadratic Unconstrained Binary Optimization Forms for High-order and Dense Interactions
Jun 10, 2025Quantum Annealing (QA) can efficiently solve combinatorial optimization problems whose objective functions are represented by Quadratic Unconstrained Binary Optimization (QUBO) formulations. For broader applicability of QA, quadratization methods are used to transform higher-order problems into QUBOs. However, quadratization methods for complex problems involving Machine Learning (ML) remain largely unknown. In these problems, strong nonlinearity and dense interactions prevent conventional methods from being applied. Therefore, we model target functions by the sum of rectified linear unit bases, which not only have the ability of universal approximation, but also have an equivalent quadratic-polynomial representation. In this study, the proof of concept is verified both numerically and analytically. In addition, by combining QA with the proposed quadratization, we design a new black-box optimization scheme, in which ML surrogate regressors are inputted to QA after the quadratization process.
Initialization Method for Factorization Machine Based on Low-Rank Approximation for Constructing a Corrected Approximate Ising Model
Oct 16, 2024



This paper presents an initialization method that can approximate a given approximate Ising model with a high degree of accuracy using the Factorization Machine (FM), a machine learning model. The construction of Ising models using FM is applied to the combinatorial optimization problem using the factorization machine with quantum annealing. It is anticipated that the optimization performance of FMQA will be enhanced through the implementation of the warm-start method. Nevertheless, the optimal initialization method for leveraging the warm-start approach in FMQA remains undetermined. Consequently, the present study compares a number of initialization methods and identifies the most appropriate for use with a warm-start in FMQA through numerical experimentation. Furthermore, the properties of the proposed FM initialization method are analyzed using random matrix theory, demonstrating that the approximation accuracy of the proposed method is not significantly influenced by the specific Ising model under consideration. The findings of this study will facilitate the advancement of combinatorial optimization problem-solving through the use of Ising machines.
Continuous black-box optimization with quantum annealing and random subspace coding
Apr 30, 2021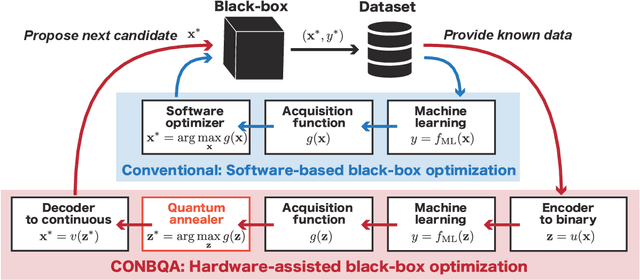
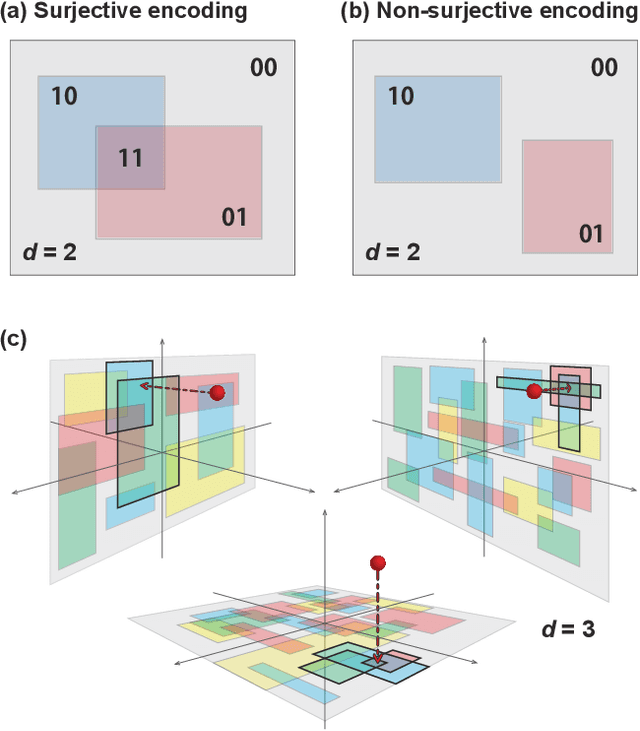


A black-box optimization algorithm such as Bayesian optimization finds extremum of an unknown function by alternating inference of the underlying function and optimization of an acquisition function. In a high-dimensional space, such algorithms perform poorly due to the difficulty of acquisition function optimization. Herein, we apply quantum annealing (QA) to overcome the difficulty in the continuous black-box optimization. As QA specializes in optimization of binary problems, a continuous vector has to be encoded to binary, and the solution of QA has to be translated back. Our method has the following three parts: 1) Random subspace coding based on axis-parallel hyperrectangles from continuous vector to binary vector. 2) A quadratic unconstrained binary optimization (QUBO) defined by acquisition function based on nonnegative-weighted linear regression model which is solved by QA. 3) A penalization scheme to ensure that the QA solution can be translated back. It is shown in benchmark tests that its performance using D-Wave Advantage$^{\rm TM}$ quantum annealer is competitive with a state-of-the-art method based on the Gaussian process in high-dimensional problems. Our method may open up a new possibility of quantum annealing and other QUBO solvers including quantum approximate optimization algorithm (QAOA) using a gated-quantum computers, and expand its range of application to continuous-valued problems.
Quantum Annealing for Variational Bayes Inference
Aug 09, 2014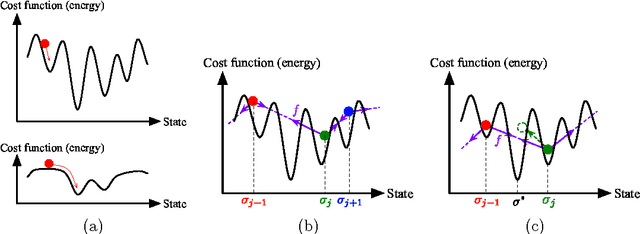
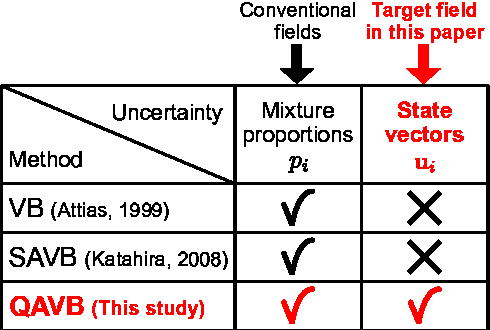
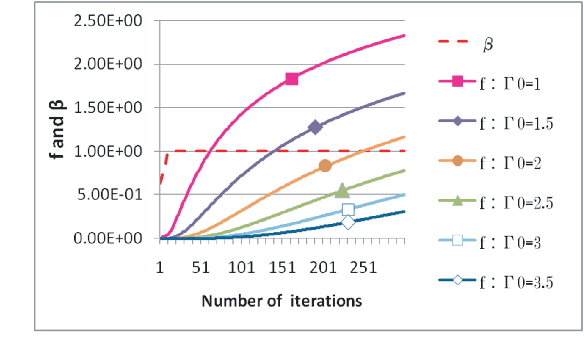
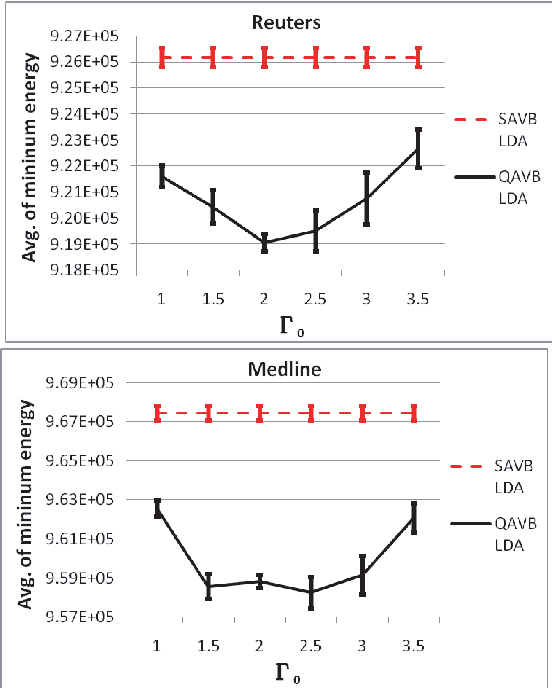
This paper presents studies on a deterministic annealing algorithm based on quantum annealing for variational Bayes (QAVB) inference, which can be seen as an extension of the simulated annealing for variational Bayes (SAVB) inference. QAVB is as easy as SAVB to implement. Experiments revealed QAVB finds a better local optimum than SAVB in terms of the variational free energy in latent Dirichlet allocation (LDA).