 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
Dec 30, 2025While Vision-Language Models (VLMs) can solve complex tasks through agentic reasoning, their capabilities remain largely constrained to text-oriented chain-of-thought or isolated tool invocation. They fail to exhibit the human-like proficiency required to seamlessly interleave dynamic tool manipulation with continuous reasoning, particularly in knowledge-intensive and visually complex scenarios that demand coordinated external tools such as search and image cropping. In this work, we introduce SenseNova-MARS, a novel Multimodal Agentic Reasoning and Search framework that empowers VLMs with interleaved visual reasoning and tool-use capabilities via reinforcement learning (RL). Specifically, SenseNova-MARS dynamically integrates the image search, text search, and image crop tools to tackle fine-grained and knowledge-intensive visual understanding challenges. In the RL stage, we propose the Batch-Normalized Group Sequence Policy Optimization (BN-GSPO) algorithm to improve the training stability and advance the model's ability to invoke tools and reason effectively. To comprehensively evaluate the agentic VLMs on complex visual tasks, we introduce the HR-MMSearch benchmark, the first search-oriented benchmark composed of high-resolution images with knowledge-intensive and search-driven questions. Experiments demonstrate that SenseNova-MARS achieves state-of-the-art performance on open-source search and fine-grained image understanding benchmarks. Specifically, on search-oriented benchmarks, SenseNova-MARS-8B scores 67.84 on MMSearch and 41.64 on HR-MMSearch, surpassing proprietary models such as Gemini-3-Flash and GPT-5. SenseNova-MARS represents a promising step toward agentic VLMs by providing effective and robust tool-use capabilities. To facilitate further research in this field, we will release all code, models, and datasets.
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Apr 29, 2024



In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$\times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
Unsupervised Domain Adaptation GAN Inversion for Image Editing
Nov 22, 2022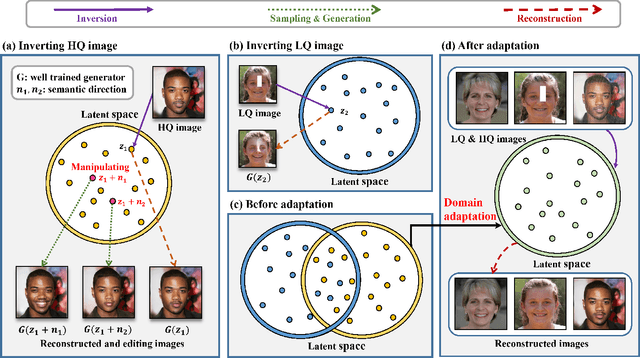



Existing GAN inversion methods work brilliantly for high-quality image reconstruction and editing while struggling with finding the corresponding high-quality images for low-quality inputs. Therefore, recent works are directed toward leveraging the supervision of paired high-quality and low-quality images for inversion. However, these methods are infeasible in real-world scenarios and further hinder performance improvement. In this paper, we resolve this problem by introducing Unsupervised Domain Adaptation (UDA) into the Inversion process, namely UDA-Inversion, for both high-quality and low-quality image inversion and editing. Particularly, UDA-Inversion first regards the high-quality and low-quality images as the source domain and unlabeled target domain, respectively. Then, a discrepancy function is presented to measure the difference between two domains, after which we minimize the source error and the discrepancy between the distributions of two domains in the latent space to obtain accurate latent codes for low-quality images. Without direct supervision, constructive representations of high-quality images can be spontaneously learned and transformed into low-quality images based on unsupervised domain adaptation. Experimental results indicate that UDA-inversion is the first that achieves a comparable level of performance with supervised methods in low-quality images across multiple domain datasets. We hope this work provides a unique inspiration for latent embedding distributions in image process tasks.