 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantic Priors: Mitigating Optimization Collapse for Generalizable Visual Forensics
Mar 25, 2026While Vision-Language Models (VLMs) like CLIP have emerged as a dominant paradigm for generalizable deepfake detection, a representational disconnect remains: their semantic-centric pre-training is ill-suited for capturing non-semantic artifacts inherent to hyper-realistic synthesis. In this work, we identify a failure mode termed Optimization Collapse, where detectors trained with Sharpness-Aware Minimization (SAM) degenerate to random guessing on non-semantic forgeries once the perturbation radius exceeds a narrow threshold. To theoretically formalize this collapse, we propose the Critical Optimization Radius (COR) to quantify the geometric stability of the optimization landscape, and leverage the Gradient Signal-to-Noise Ratio (GSNR) to measure generalization potential. We establish a theorem proving that COR increases monotonically with GSNR, thereby revealing that the geometric instability of SAM optimization originates from degraded intrinsic generalization potential. This result identifies the layer-wise attenuation of GSNR as the root cause of Optimization Collapse in detecting non-semantic forgeries. Although naively reducing perturbation radius yields stable convergence under SAM, it merely treats the symptom without mitigating the intrinsic generalization degradation, necessitating enhanced gradient fidelity. Building on this insight, we propose the Contrastive Regional Injection Transformer (CoRIT), which integrates a computationally efficient Contrastive Gradient Proxy (CGP) with three training-free strategies: Region Refinement Mask to suppress CGP variance, Regional Signal Injection to preserve CGP magnitude, and Hierarchical Representation Integration to attain more generalizable representations. Extensive experiments demonstrate that CoRIT mitigates optimization collapse and achieves state-of-the-art generalization across cross-domain and universal forgery benchmarks.
Exploring Straighter Trajectories of Flow Matching with Diffusion Guidance
Nov 28, 2023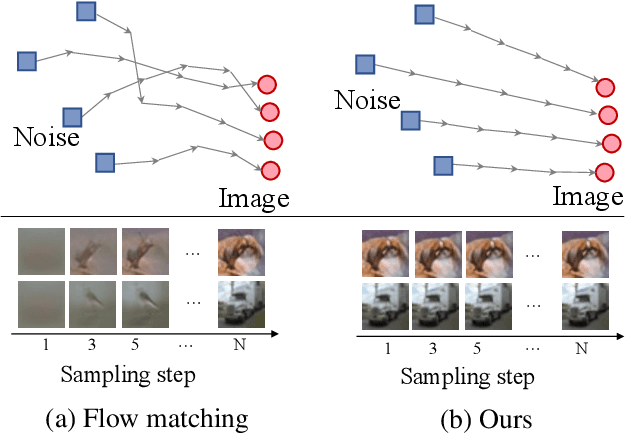
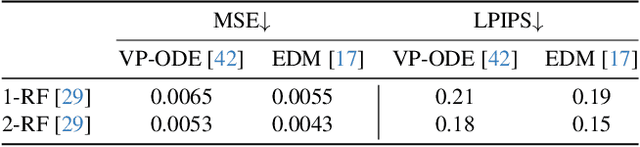

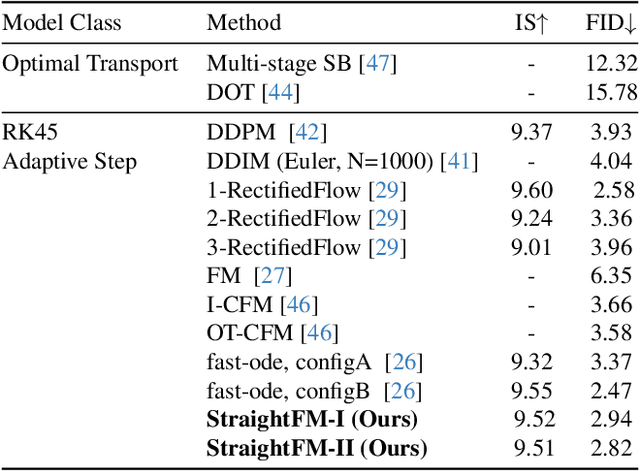
Flow matching as a paradigm of generative model achieves notable success across various domains. However, existing methods use either multi-round training or knowledge within minibatches, posing challenges in finding a favorable coupling strategy for straight trajectories. To address this issue, we propose a novel approach, Straighter trajectories of Flow Matching (StraightFM). It straightens trajectories with the coupling strategy guided by diffusion model from entire distribution level. First, we propose a coupling strategy to straighten trajectories, creating couplings between image and noise samples under diffusion model guidance. Second, StraightFM also integrates real data to enhance training, employing a neural network to parameterize another coupling process from images to noise samples. StraightFM is jointly optimized with couplings from above two mutually complementary directions, resulting in straighter trajectories and enabling both one-step and few-step generation. Extensive experiments demonstrate that StraightFM yields high quality samples with fewer step. StraightFM generates visually appealing images with a lower FID among diffusion and traditional flow matching methods within 5 sampling steps when trained on pixel space. In the latent space (i.e., Latent Diffusion), StraightFM achieves a lower KID value compared to existing methods on the CelebA-HQ 256 dataset in fewer than 10 sampling steps.
Unsupervised Domain Adaptation GAN Inversion for Image Editing
Nov 22, 2022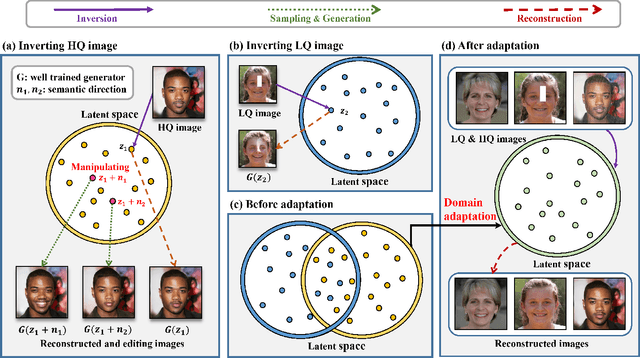



Existing GAN inversion methods work brilliantly for high-quality image reconstruction and editing while struggling with finding the corresponding high-quality images for low-quality inputs. Therefore, recent works are directed toward leveraging the supervision of paired high-quality and low-quality images for inversion. However, these methods are infeasible in real-world scenarios and further hinder performance improvement. In this paper, we resolve this problem by introducing Unsupervised Domain Adaptation (UDA) into the Inversion process, namely UDA-Inversion, for both high-quality and low-quality image inversion and editing. Particularly, UDA-Inversion first regards the high-quality and low-quality images as the source domain and unlabeled target domain, respectively. Then, a discrepancy function is presented to measure the difference between two domains, after which we minimize the source error and the discrepancy between the distributions of two domains in the latent space to obtain accurate latent codes for low-quality images. Without direct supervision, constructive representations of high-quality images can be spontaneously learned and transformed into low-quality images based on unsupervised domain adaptation. Experimental results indicate that UDA-inversion is the first that achieves a comparable level of performance with supervised methods in low-quality images across multiple domain datasets. We hope this work provides a unique inspiration for latent embedding distributions in image process tasks.