 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked Intelligent Metasurfaces-Based Electromagnetic Wave Domain Interference-Free Precoding
Jan 27, 2026This paper introduces an interference-free multi-stream transmission architecture leveraging stacked intelligent metasurfaces (SIMs), from a new perspective of interference exploitation. Unlike traditional interference exploitation precoding (IEP) which relies on computational hardware circuitry, we perform the precoding operations within the analog wave domain provided by SIMs. However, the benefits of SIM-enabled IEP are limited by the nonlinear distortion (NLD) caused by power amplifiers. A hardware-efficient interference-free transmitter architecture is developed to exploit SIM's high and flexible degree of freedom (DoF), where the NLD on modulated symbols can be directly compensated in the wave domain. Moreover, we design a frame-level SIM configuration scheme and formulate a maxmin problem on the safety margin function. With respect to the optimization of SIM phase shifts, we propose a recursive oblique manifold (ROM) algorithm to tackle the complex coupling among phase shifts across multiple layers. A flexible DoF-driven antenna selection (AS) scheme is explored in the SIM-enabled IEP system. Using an ROM-based alternating optimization (ROM-AO) framework, our approach jointly optimizes transmit AS, SIM phase shift design, and power allocation (PA), and develops a greedy safety margin-based AS algorithm. Simulations show that the proposed SIM-enabled frame-level IEP scheme significantly outperforms benchmarks. Specifically, the strategy with AS and PA can achieve a 20 dB performance gain compared to the case without any strategy under the 12 dB signal-to-noise ratio, which confirms the superiority of the NLD-aware IEP scheme and the effectiveness of the proposed algorithm.
Probing the Emergence of Cross-lingual Alignment during LLM Training
Jun 19, 2024Multilingual Large Language Models (LLMs) achieve remarkable levels of zero-shot cross-lingual transfer performance. We speculate that this is predicated on their ability to align languages without explicit supervision from parallel sentences. While representations of translationally equivalent sentences in different languages are known to be similar after convergence, however, it remains unclear how such cross-lingual alignment emerges during pre-training of LLMs. Our study leverages intrinsic probing techniques, which identify which subsets of neurons encode linguistic features, to correlate the degree of cross-lingual neuron overlap with the zero-shot cross-lingual transfer performance for a given model. In particular, we rely on checkpoints of BLOOM, a multilingual autoregressive LLM, across different training steps and model scales. We observe a high correlation between neuron overlap and downstream performance, which supports our hypothesis on the conditions leading to effective cross-lingual transfer. Interestingly, we also detect a degradation of both implicit alignment and multilingual abilities in certain phases of the pre-training process, providing new insights into the multilingual pretraining dynamics.
Intelligent Reflecting Surfaces and Next Generation Wireless Systems
Feb 27, 2024Intelligent reflecting surface (IRS) is a potential candidate for massive multiple-input multiple-output (MIMO) 2.0 technology due to its low cost, ease of deployment, energy efficiency and extended coverage. This chapter investigates the slot-by-slot IRS reflection pattern design and two-timescale reflection pattern design schemes, respectively. For the slot-by-slot reflection optimization, we propose exploiting an IRS to improve the propagation channel rank in mmWave massive MIMO systems without need to increase the transmit power budget. Then, we analyze the impact of the distributed IRS on the channel rank. To further reduce the heavy overhead of channel training, channel state information (CSI) estimation, and feedback in time-varying MIMO channels, we present a two-timescale reflection optimization scheme, where the IRS is configured relatively infrequently based on statistical CSI (S-CSI) and the active beamformers and power allocation are updated based on quickly outdated instantaneous CSI (I-CSI) per slot. The achievable average sum-rate (AASR) of the system is maximized without excessive overhead of cascaded channel estimation. A recursive sampling particle swarm optimization (PSO) algorithm is developed to optimize the large-timescale IRS reflection pattern efficiently with reduced samplings of channel samples.
Accelerating Laboratory Automation Through Robot Skill Learning For Sample Scraping
Sep 29, 2022
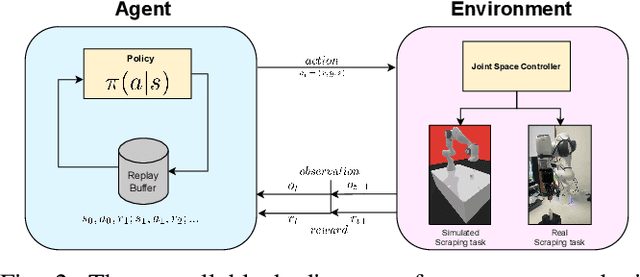


The potential use of robotics for laboratory experiments offers an attractive route to alleviate scientists from tedious tasks while accelerating the process of obtaining new materials, where topical issues such as climate change and disease risks worldwide would greatly benefit. While some experimental workflows can already benefit from automation, it is common that sample preparation is still carried out manually due to the high level of motor function required when dealing with heterogeneous systems, e.g., different tools, chemicals, and glassware. A fundamental workflow in chemical fields is crystallisation, where one application is polymorph screening, i.e., obtaining a three dimensional molecular structure from a crystal. For this process, it is of utmost importance to recover as much of the sample as possible since synthesising molecules is both costly in time and money. To this aim, chemists have to scrape vials to retrieve sample contents prior to imaging plate transfer. Automating this process is challenging as it goes beyond robotic insertion tasks due to a fundamental requirement of having to execute fine-granular movements within a constrained environment that is the sample vial. Motivated by how human chemists carry out this process of scraping powder from vials, our work proposes a model-free reinforcement learning method for learning a scraping policy, leading to a fully autonomous sample scraping procedure. To realise that, we first create a simulation environment with a Panda Franka Emika robot using a laboratory scraper which is inserted into a simulated vial, to demonstrate how a scraping policy can be learned successfully. We then evaluate our method on a real robotic manipulator in laboratory settings, and show that our method can autonomously scrape powder across various setups.