 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task robot data for dual-arm fine manipulation
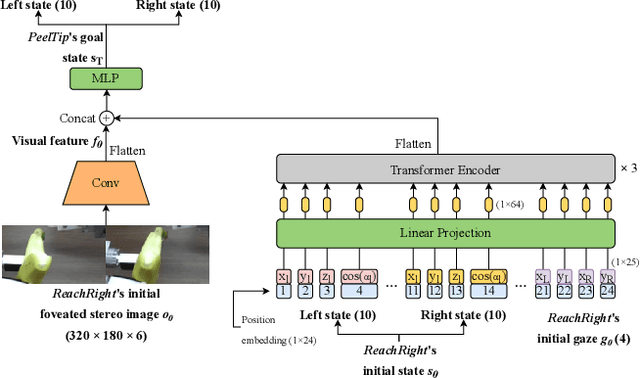
Jan 26, 2024In the field of robotic manipulation, deep imitation learning is recognized as a promising approach for acquiring manipulation skills. Additionally, learning from diverse robot datasets is considered a viable method to achieve versatility and adaptability. In such research, by learning various tasks, robots achieved generality across multiple objects. However, such multi-task robot datasets have mainly focused on single-arm tasks that are relatively imprecise, not addressing the fine-grained object manipulation that robots are expected to perform in the real world. This paper introduces a dataset of diverse object manipulations that includes dual-arm tasks and/or tasks requiring fine manipulation. To this end, we have generated dataset with 224k episodes (150 hours, 1,104 language instructions) which includes dual-arm fine tasks such as bowl-moving, pencil-case opening or banana-peeling, and this data is publicly available. Additionally, this dataset includes visual attention signals as well as dual-action labels, a signal that separates actions into a robust reaching trajectory and precise interaction with objects, and language instructions to achieve robust and precise object manipulation. We applied the dataset to our Dual-Action and Attention (DAA), a model designed for fine-grained dual arm manipulation tasks and robust against covariate shifts. The model was tested with over 7k total trials in real robot manipulation tasks, demonstrating its capability in fine manipulation. The dataset is available at https://sites.google.com/view/multi-task-fine.
Robot peels banana with goal-conditioned dual-action deep imitation learning
Mar 18, 2022


A long-horizon dexterous robot manipulation task of deformable objects, such as banana peeling, is problematic because of difficulties in object modeling and a lack of knowledge about stable and dexterous manipulation skills. This paper presents a goal-conditioned dual-action deep imitation learning (DIL) which can learn dexterous manipulation skills using human demonstration data. Previous DIL methods map the current sensory input and reactive action, which easily fails because of compounding errors in imitation learning caused by recurrent computation of actions. The proposed method predicts reactive action when the precise manipulation of the target object is required (local action) and generates the entire trajectory when the precise manipulation is not required. This dual-action formulation effectively prevents compounding error with the trajectory-based global action while respond to unexpected changes in the target object with the reactive local action. Furthermore, in this formulation, both global/local actions are conditioned by a goal state which is defined as the last step of each subtask, for robust policy prediction. The proposed method was tested in the real dual-arm robot and successfully accomplished the banana peeling task.
Training Robots without Robots: Deep Imitation Learning for Master-to-Robot Policy Transfer
Feb 19, 2022



Deep imitation learning is a promising method for dexterous robot manipulation because it only requires demonstration samples for learning manipulation skills. In this paper, deep imitation learning is applied to tasks that require force feedback, such as bottle opening. However, simple visual feedback systems, such as teleoperation, cannot be applied because they do not provide force feedback to operators. Bilateral teleoperation has been used for demonstration with force feedback; however, this requires an expensive and complex bilateral robot system. In this paper, a new master-to-robot (M2R) transfer learning system is presented that does not require robots but can still teach dexterous force feedback-based manipulation tasks to robots. The human directly demonstrates a task using a low-cost controller that resembles the kinematic parameters of the robot arm. Using this controller, the operator can naturally feel the force feedback without any expensive bilateral system. Furthermore, the M2R transfer system can overcome domain gaps between the master and robot using the gaze-based imitation learning framework and a simple calibration method. To demonstrate this, the proposed system was evaluated on a bottle-cap-opening task that requires force feedback only for the master demonstration.
Memory-based gaze prediction in deep imitation learning for robot manipulation
Feb 10, 2022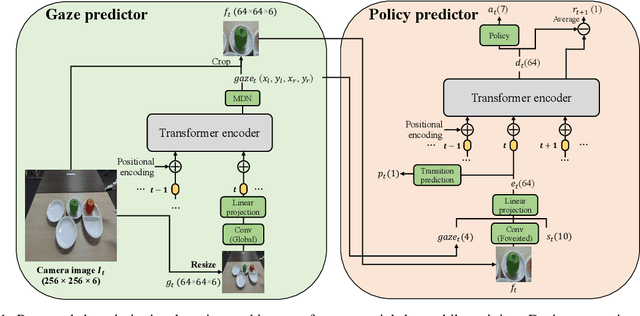


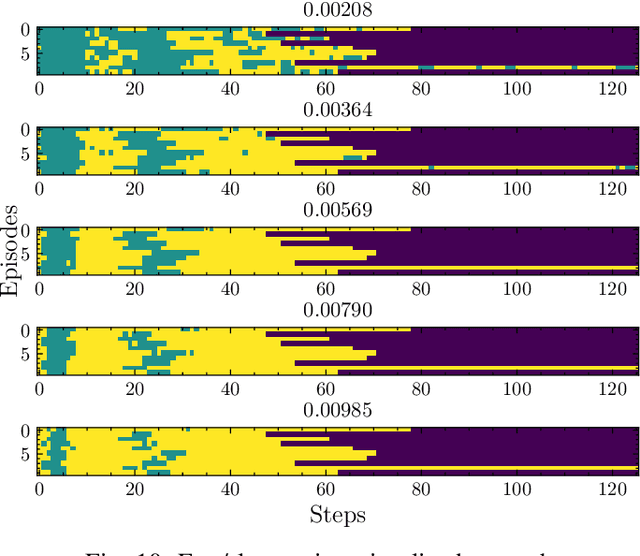
Deep imitation learning is a promising approach that does not require hard-coded control rules in autonomous robot manipulation. The current applications of deep imitation learning to robot manipulation have been limited to reactive control based on the states at the current time step. However, future robots will also be required to solve tasks utilizing their memory obtained by experience in complicated environments (e.g., when the robot is asked to find a previously used object on a shelf). In such a situation, simple deep imitation learning may fail because of distractions caused by complicated environments. We propose that gaze prediction from sequential visual input enables the robot to perform a manipulation task that requires memory. The proposed algorithm uses a Transformer-based self-attention architecture for the gaze estimation based on sequential data to implement memory. The proposed method was evaluated with a real robot multi-object manipulation task that requires memory of the previous states.
Transformer-based deep imitation learning for dual-arm robot manipulation
Aug 01, 2021



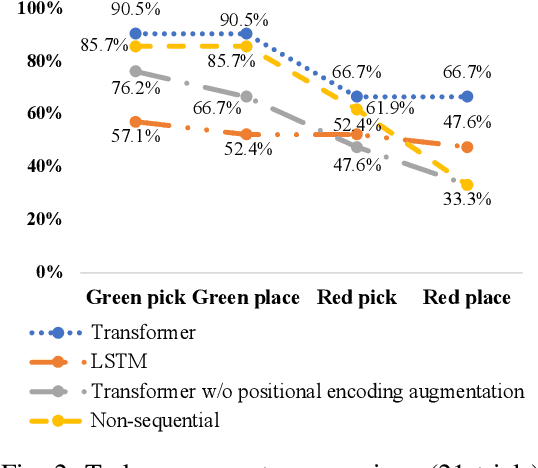
Deep imitation learning is promising for solving dexterous manipulation tasks because it does not require an environment model and pre-programmed robot behavior. However, its application to dual-arm manipulation tasks remains challenging. In a dual-arm manipulation setup, the increased number of state dimensions caused by the additional robot manipulators causes distractions and results in poor performance of the neural networks. We address this issue using a self-attention mechanism that computes dependencies between elements in a sequential input and focuses on important elements. A Transformer, a variant of self-attention architecture, is applied to deep imitation learning to solve dual-arm manipulation tasks in the real world. The proposed method has been tested on dual-arm manipulation tasks using a real robot. The experimental results demonstrated that the Transformer-based deep imitation learning architecture can attend to the important features among the sensory inputs, therefore reducing distractions and improving manipulation performance when compared with the baseline architecture without the self-attention mechanisms.
Gaze-based dual resolution deep imitation learning for high-precision dexterous robot manipulation
Mar 03, 2021
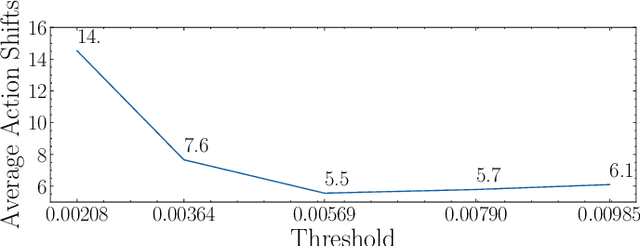

A high-precision manipulation task, such as needle threading, is challenging. Physiological studies have proposed connecting low-resolution peripheral vision and fast movement to transport the hand into the vicinity of an object, and using high-resolution foveated vision to achieve the accurate homing of the hand to the object. The results of this study demonstrate that a deep imitation learning based method, inspired by the gaze-based dual resolution visuomotor control system in humans, can solve the needle threading task. First, we recorded the gaze movements of a human operator who was teleoperating a robot. Then, we used only a high-resolution image around the gaze to precisely control the thread position when it was close to the target. We used a low-resolution peripheral image to reach the vicinity of the target. The experimental results obtained in this study demonstrate that the proposed method enables precise manipulation tasks using a general-purpose robot manipulator and improves computational efficiency.
* 8 pages. The supplementary video can be found at: https://www.youtube.com/watch?v=ytpChcFqD5g Published in IEEE Robotics and Automation Letters. Replaced to add video url in the manuscript