 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-based gaze prediction in deep imitation learning for robot manipulation
Paper and Code
Feb 10, 2022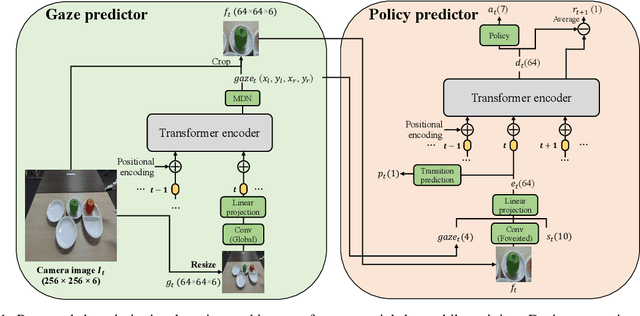
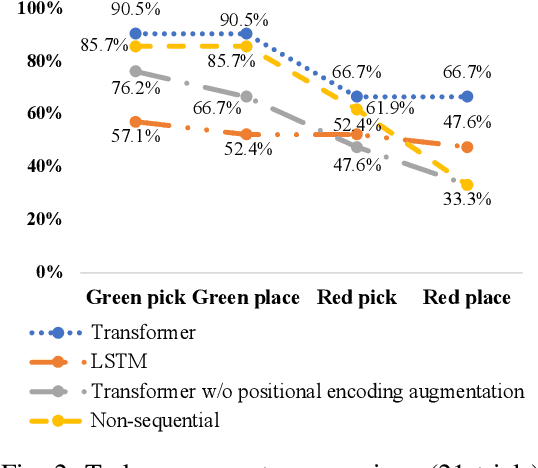


Deep imitation learning is a promising approach that does not require hard-coded control rules in autonomous robot manipulation. The current applications of deep imitation learning to robot manipulation have been limited to reactive control based on the states at the current time step. However, future robots will also be required to solve tasks utilizing their memory obtained by experience in complicated environments (e.g., when the robot is asked to find a previously used object on a shelf). In such a situation, simple deep imitation learning may fail because of distractions caused by complicated environments. We propose that gaze prediction from sequential visual input enables the robot to perform a manipulation task that requires memory. The proposed algorithm uses a Transformer-based self-attention architecture for the gaze estimation based on sequential data to implement memory. The proposed method was evaluated with a real robot multi-object manipulation task that requires memory of the previous states.