 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2E-GNet: An End-to-End Skeleton-based Geometric Deep Neural Network for Human Motion Recognition
Mar 03, 2026Geometric deep learning has recently gained significant attention in the computer vision community for its ability to capture meaningful representations of data lying in a non-Euclidean space. To this end, we propose E2E-GNet, an end-to-end geometric deep neural network for skeleton-based human motion recognition. To enhance the discriminative power between different motions in the non-Euclidean space, E2E-GNet introduces a geometric transformation layer that jointly optimizes skeleton motion sequences on this space and applies a differentiable logarithm map activation to project them onto a linear space. Building on this, we further design a distortion-aware optimization layer that limits skeleton shape distortions caused by this projection, enabling the network to retain discriminative geometric cues and achieve a higher motion recognition rate. We demonstrate the impact of each layer through ablation studies and extensive experiments across five datasets spanning three domains show that E2E-GNet outperforms other methods with lower cost.
ConViViT -- A Deep Neural Network Combining Convolutions and Factorized Self-Attention for Human Activity Recognition
Oct 22, 2023



The Transformer architecture has gained significant popularity in computer vision tasks due to its capacity to generalize and capture long-range dependencies. This characteristic makes it well-suited for generating spatiotemporal tokens from videos. On the other hand, convolutions serve as the fundamental backbone for processing images and videos, as they efficiently aggregate information within small local neighborhoods to create spatial tokens that describe the spatial dimension of a video. While both CNN-based architectures and pure transformer architectures are extensively studied and utilized by researchers, the effective combination of these two backbones has not received comparable attention in the field of activity recognition. In this research, we propose a novel approach that leverages the strengths of both CNNs and Transformers in an hybrid architecture for performing activity recognition using RGB videos. Specifically, we suggest employing a CNN network to enhance the video representation by generating a 128-channel video that effectively separates the human performing the activity from the background. Subsequently, the output of the CNN module is fed into a transformer to extract spatiotemporal tokens, which are then used for classification purposes. Our architecture has achieved new SOTA results with 90.05 \%, 99.6\%, and 95.09\% on HMDB51, UCF101, and ETRI-Activity3D respectively.
Magnifying Subtle Facial Motions for Effective 4D Expression Recognition
May 05, 2021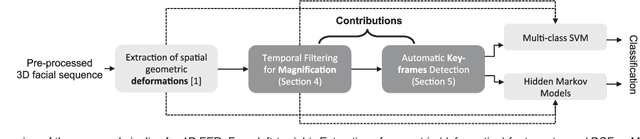

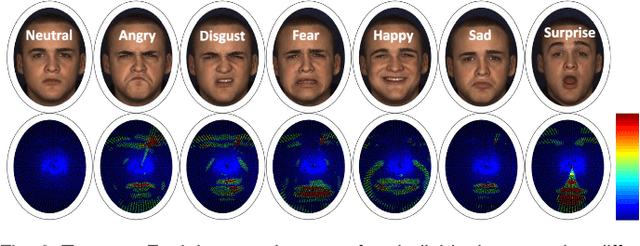
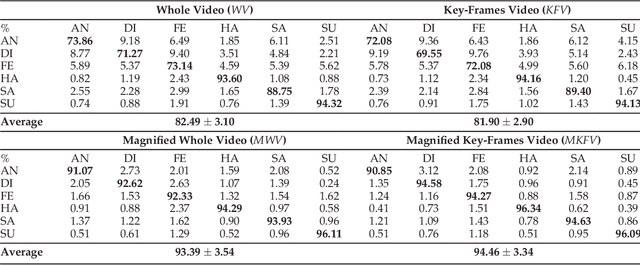
In this paper, an effective pipeline to automatic 4D Facial Expression Recognition (4D FER) is proposed. It combines two growing but disparate ideas in Computer Vision -- computing the spatial facial deformations using tools from Riemannian geometry and magnifying them using temporal filtering. The flow of 3D faces is first analyzed to capture the spatial deformations based on the recently-developed Riemannian approach, where registration and comparison of neighboring 3D faces are led jointly. Then, the obtained temporal evolution of these deformations are fed into a magnification method in order to amplify the facial activities over the time. The latter, main contribution of this paper, allows revealing subtle (hidden) deformations which enhance the emotion classification performance. We evaluated our approach on BU-4DFE dataset, the state-of-art 94.18% average performance and an improvement that exceeds 10% in classification accuracy, after magnifying extracted geometric features (deformations), are achieved.
KShapeNet: Riemannian network on Kendall shape space for Skeleton based Action Recognition
Nov 24, 2020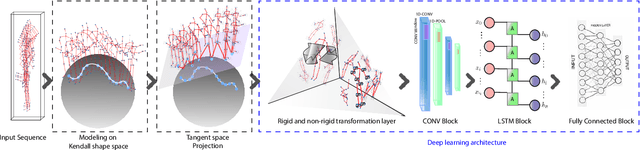
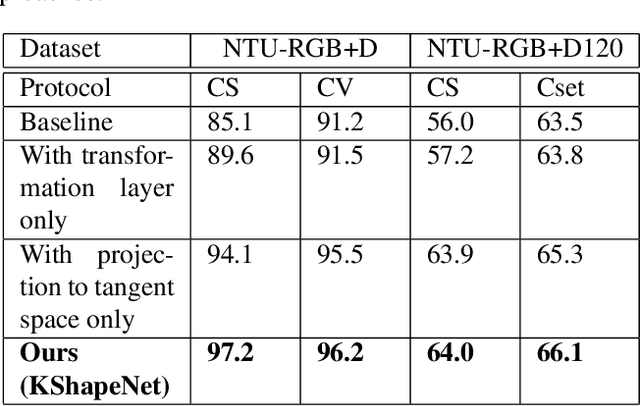
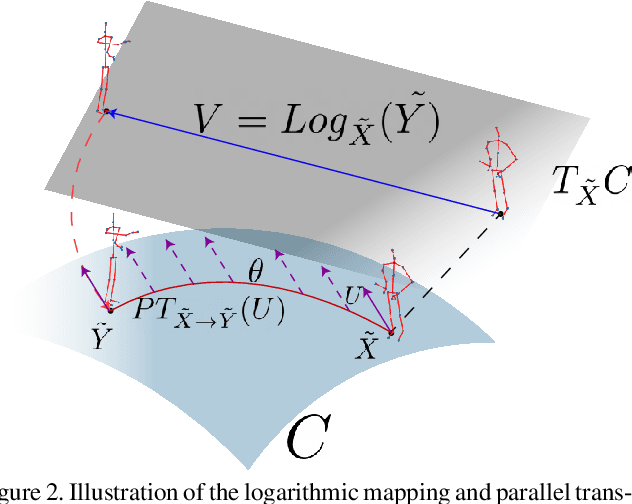
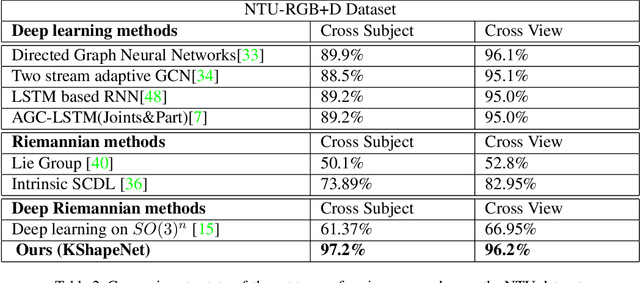
Deep Learning architectures, albeit successful in most computer vision tasks, were designed for data with an underlying Euclidean structure, which is not usually fulfilled since pre-processed data may lie on a non-linear space. In this paper, we propose a geometry aware deep learning approach for skeleton-based action recognition. Skeleton sequences are first modeled as trajectories on Kendall's shape space and then mapped to the linear tangent space. The resulting structured data are then fed to a deep learning architecture, which includes a layer that optimizes over rigid and non rigid transformations of the 3D skeletons, followed by a CNN-LSTM network. The assessment on two large scale skeleton datasets, namely NTU-RGB+D and NTU-RGB+D 120, has proven that proposed approach outperforms existing geometric deep learning methods and is competitive with respect to recently published approaches.
Sparse Coding of Shape Trajectories for Facial Expression and Action Recognition
Aug 08, 2019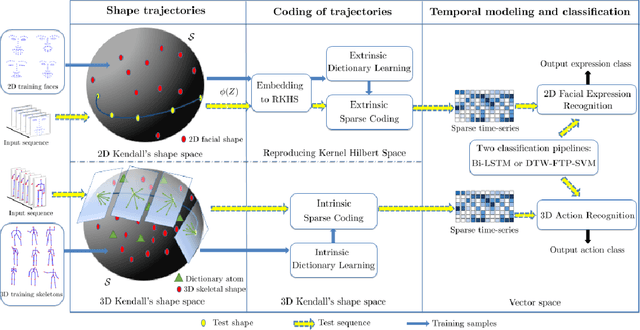
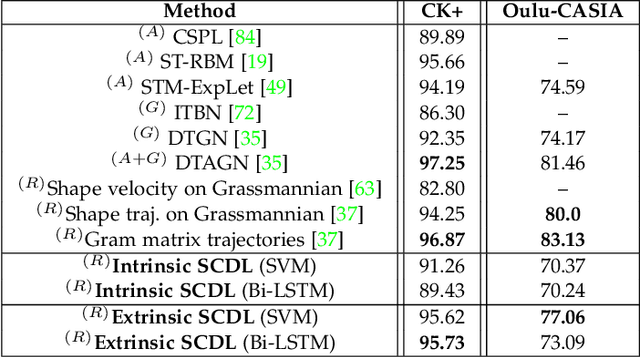
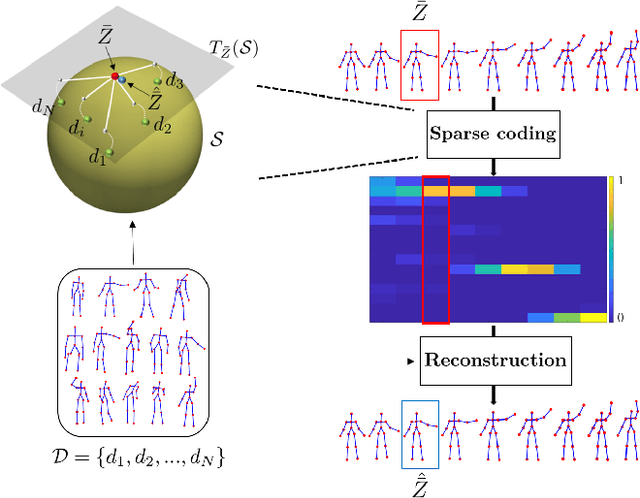
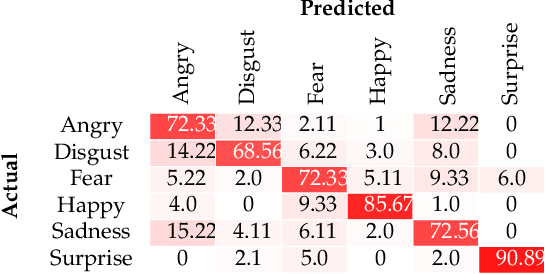
The detection and tracking of human landmarks in video streams has gained in reliability partly due to the availability of affordable RGB-D sensors. The analysis of such time-varying geometric data is playing an important role in the automatic human behavior understanding. However, suitable shape representations as well as their temporal evolution, termed trajectories, often lie to nonlinear manifolds. This puts an additional constraint (i.e., nonlinearity) in using conventional Machine Learning techniques. As a solution, this paper accommodates the well-known Sparse Coding and Dictionary Learning approach to study time-varying shapes on the Kendall shape spaces of 2D and 3D landmarks. We illustrate effective coding of 3D skeletal sequences for action recognition and 2D facial landmark sequences for macro- and micro-expression recognition. To overcome the inherent nonlinearity of the shape spaces, intrinsic and extrinsic solutions were explored. As main results, shape trajectories give rise to more discriminative time-series with suitable computational properties, including sparsity and vector space structure. Extensive experiments conducted on commonly-used datasets demonstrate the competitiveness of the proposed approaches with respect to state-of-the-art.
* 14 pages, 5 figures