 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConViViT -- A Deep Neural Network Combining Convolutions and Factorized Self-Attention for Human Activity Recognition
Oct 22, 2023



The Transformer architecture has gained significant popularity in computer vision tasks due to its capacity to generalize and capture long-range dependencies. This characteristic makes it well-suited for generating spatiotemporal tokens from videos. On the other hand, convolutions serve as the fundamental backbone for processing images and videos, as they efficiently aggregate information within small local neighborhoods to create spatial tokens that describe the spatial dimension of a video. While both CNN-based architectures and pure transformer architectures are extensively studied and utilized by researchers, the effective combination of these two backbones has not received comparable attention in the field of activity recognition. In this research, we propose a novel approach that leverages the strengths of both CNNs and Transformers in an hybrid architecture for performing activity recognition using RGB videos. Specifically, we suggest employing a CNN network to enhance the video representation by generating a 128-channel video that effectively separates the human performing the activity from the background. Subsequently, the output of the CNN module is fed into a transformer to extract spatiotemporal tokens, which are then used for classification purposes. Our architecture has achieved new SOTA results with 90.05 \%, 99.6\%, and 95.09\% on HMDB51, UCF101, and ETRI-Activity3D respectively.
KShapeNet: Riemannian network on Kendall shape space for Skeleton based Action Recognition
Nov 24, 2020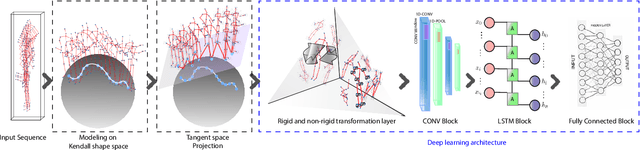
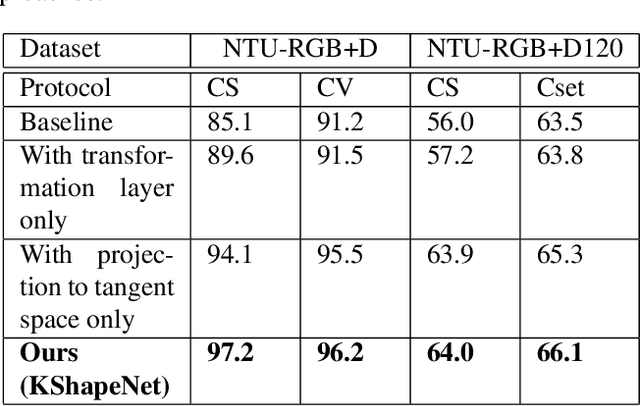
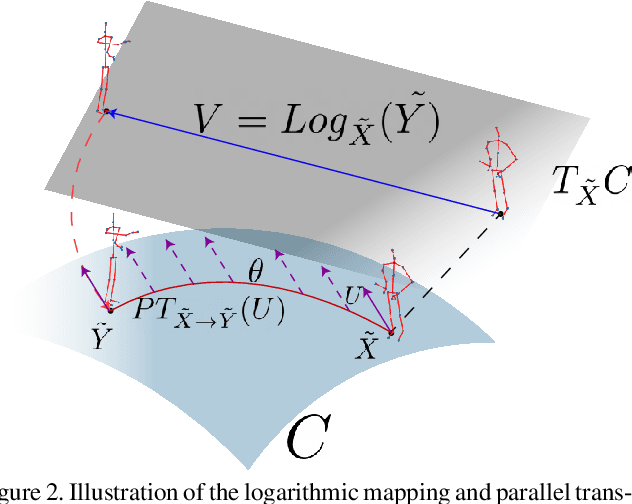
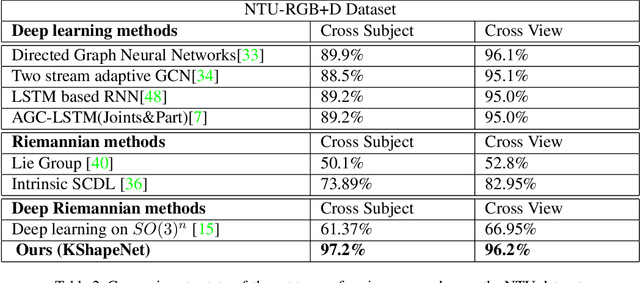
Deep Learning architectures, albeit successful in most computer vision tasks, were designed for data with an underlying Euclidean structure, which is not usually fulfilled since pre-processed data may lie on a non-linear space. In this paper, we propose a geometry aware deep learning approach for skeleton-based action recognition. Skeleton sequences are first modeled as trajectories on Kendall's shape space and then mapped to the linear tangent space. The resulting structured data are then fed to a deep learning architecture, which includes a layer that optimizes over rigid and non rigid transformations of the 3D skeletons, followed by a CNN-LSTM network. The assessment on two large scale skeleton datasets, namely NTU-RGB+D and NTU-RGB+D 120, has proven that proposed approach outperforms existing geometric deep learning methods and is competitive with respect to recently published approaches.