 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Semantic Communications: Principles and Practices
Apr 21, 2025Semantic communication leverages artificial intelligence (AI) technologies to extract semantic information from data for efficient transmission, theraby significantly reducing communication cost. With the evolution towards artificial general intelligence (AGI), the increasing demands for AGI services pose new challenges to semantic communication. In response, we propose a new paradigm for AGI-driven communications, called generative semantic communication (GSC), which utilizes advanced AI technologies such as foundation models and generative models. We first describe the basic concept of GSC and its difference from existing semantic communications, and then introduce a general framework of GSC, followed by two case studies to verify the advantages of GSC in AGI-driven applications. Finally, open challenges and new research directions are discussed to stimulate this line of research and pave the way for practical applications.
Over-the-Air Federated Learning in MIMO Cloud-RAN Systems
May 17, 2023
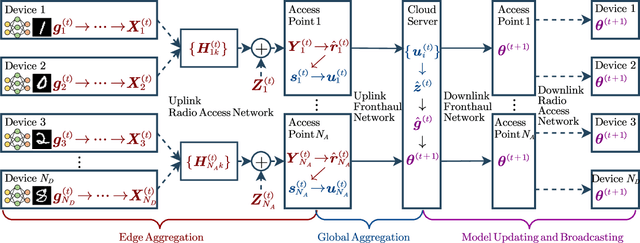


To address the limitations of traditional over-the-air federated learning (OA-FL) such as limited server coverage and low resource utilization, we propose an OA-FL in MIMO cloud radio access network (MIMO Cloud-RAN) framework, where edge devices upload (or download) model parameters to the cloud server (CS) through access points (APs). Specifically, in every training round, there are three stages: edge aggregation; global aggregation; and model updating and broadcasting. To better utilize the correlation among APs, called inter-AP correlation, we propose modeling the global aggregation stage as a lossy distributed source coding (L-DSC) problem to make analysis from the perspective of rate-distortion theory. We further analyze the performance of the proposed OA-FL in MIMO Cloud-RAN framework. Based on the analysis, we formulate a communication-learning optimization problem to improve the system performance by considering the inter-AP correlation. To solve this problem, we develop an algorithm by using alternating optimization (AO) and majorization-minimization (MM), which effectively improves the FL learning performance. Furthermore, we propose a practical design that demonstrates the utilization of inter-AP correlation. The numerical results show that the proposed practical design effectively leverages inter-AP correlation, and outperforms other baseline schemes.
Over-the-Air Federated Multi-Task Learning via Model Sparsification and Turbo Compressed Sensing
May 08, 2022
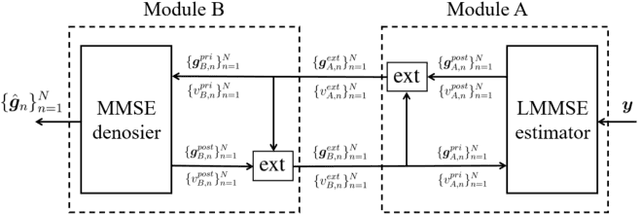

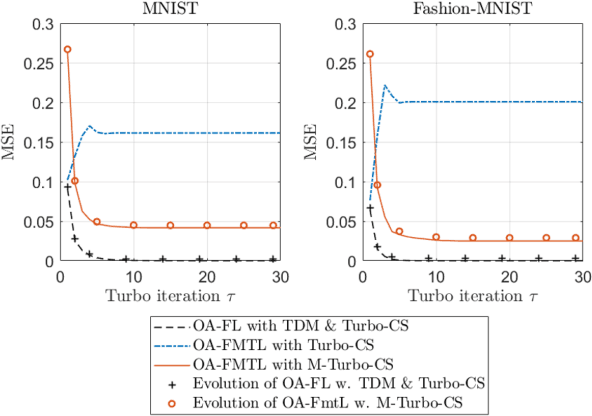
To achieve communication-efficient federated multitask learning (FMTL), we propose an over-the-air FMTL (OAFMTL) framework, where multiple learning tasks deployed on edge devices share a non-orthogonal fading channel under the coordination of an edge server (ES). In OA-FMTL, the local updates of edge devices are sparsified, compressed, and then sent over the uplink channel in a superimposed fashion. The ES employs over-the-air computation in the presence of intertask interference. More specifically, the model aggregations of all the tasks are reconstructed from the channel observations concurrently, based on a modified version of the turbo compressed sensing (Turbo-CS) algorithm (named as M-Turbo-CS). We analyze the performance of the proposed OA-FMTL framework together with the M-Turbo-CS algorithm. Furthermore, based on the analysis, we formulate a communication-learning optimization problem to improve the system performance by adjusting the power allocation among the tasks at the edge devices. Numerical simulations show that our proposed OAFMTL effectively suppresses the inter-task interference, and achieves a learning performance comparable to its counterpart with orthogonal multi-task transmission. It is also shown that the proposed inter-task power allocation optimization algorithm substantially reduces the overall communication overhead by appropriately adjusting the power allocation among the tasks.
Multi-task Over-the-Air Federated Learning: A Non-Orthogonal Transmission Approach
Jun 29, 2021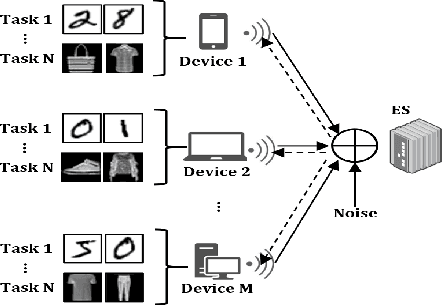
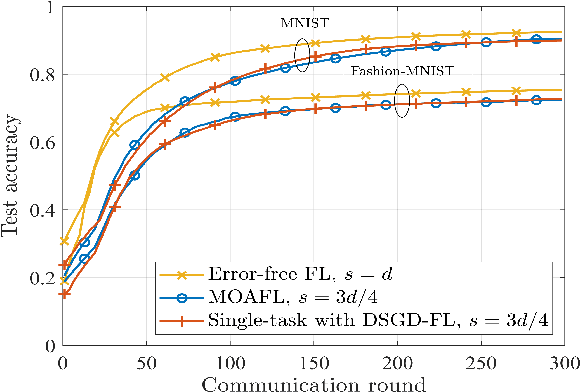

In this letter, we propose a multi-task over-theair federated learning (MOAFL) framework, where multiple learning tasks share edge devices for data collection and learning models under the coordination of a edge server (ES). Specially, the model updates for all the tasks are transmitted and superpositioned concurrently over a non-orthogonal uplink channel via over-the-air computation, and the aggregation results of all the tasks are reconstructed at the ES through an extended version of the turbo compressed sensing algorithm. Both the convergence analysis and numerical results demonstrate that the MOAFL framework can significantly reduce the uplink bandwidth consumption of multiple tasks without causing substantial learning performance degradation.