 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBit Error and Block Error Rate Training for ML-Assisted Communication
Oct 25, 2022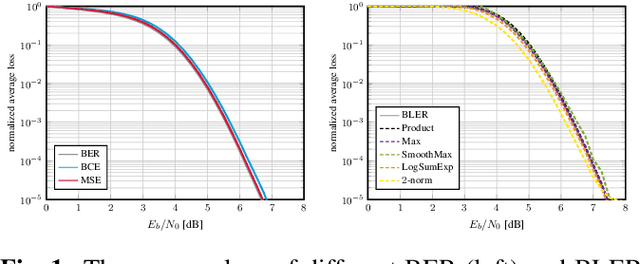
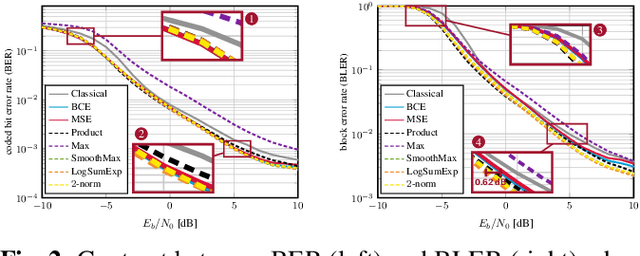
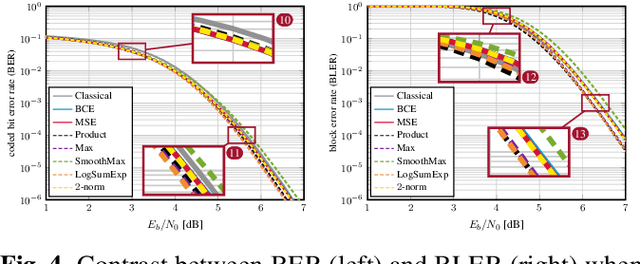
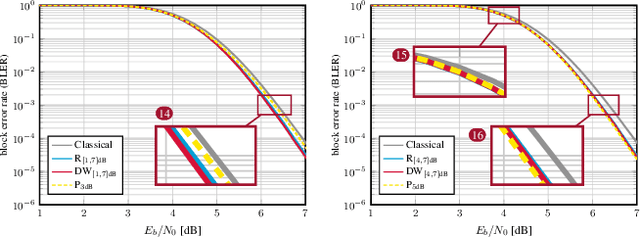
Even though machine learning (ML) techniques are being widely used in communications, the question of how to train communication systems has received surprisingly little attention. In this paper, we show that the commonly used binary cross-entropy (BCE) loss is a sensible choice in uncoded systems, e.g., for training ML-assisted data detectors, but may not be optimal in coded systems. We propose new loss functions targeted at minimizing the block error rate and SNR de-weighting, a novel method that trains communication systems for optimal performance over a range of signal-to-noise ratios. The utility of the proposed loss functions as well as of SNR de-weighting is shown through simulations in NVIDIA Sionna.
Soft-Output Joint Channel Estimation and Data Detection using Deep Unfolding
Dec 01, 2021
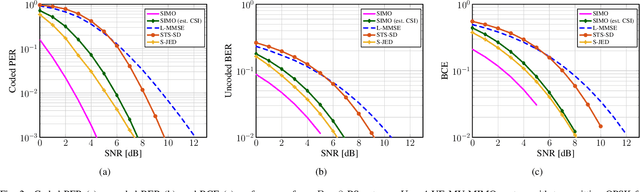
We propose a novel soft-output joint channel estimation and data detection (JED) algorithm for multiuser (MU) multiple-input multiple-output (MIMO) wireless communication systems. Our algorithm approximately solves a maximum a-posteriori JED optimization problem using deep unfolding and generates soft-output information for the transmitted bits in every iteration. The parameters of the unfolded algorithm are computed by a hyper-network that is trained with a binary cross entropy (BCE) loss. We evaluate the performance of our algorithm in a coded MU-MIMO system with 8 basestation antennas and 4 user equipments and compare it to state-of-the-art algorithms separate channel estimation from soft-output data detection. Our results demonstrate that our JED algorithm outperforms such data detectors with as few as 10 iterations.
Joint Channel Estimation and Data Detection in Cell-Free Massive MU-MIMO Systems
Oct 29, 2021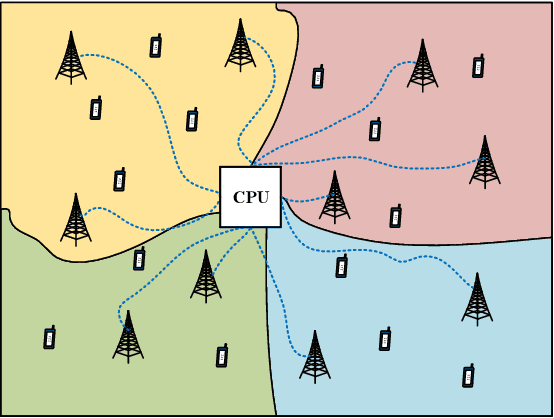
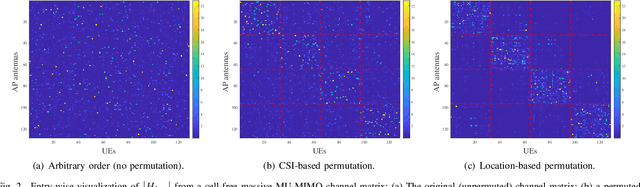
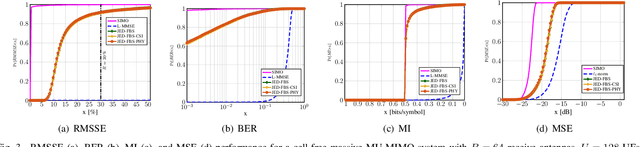
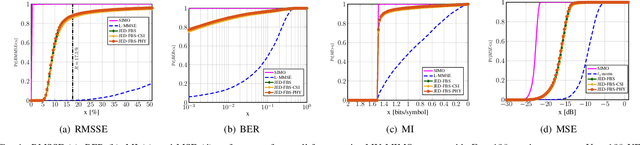
We propose a joint channel estimation and data detection (JED) algorithm for densely-populated cell-free massive multiuser (MU) multiple-input multiple-output (MIMO) systems, which reduces the channel training overhead caused by the presence of hundreds of simultaneously transmitting user equipments (UEs). Our algorithm iteratively solves a relaxed version of a maximum a-posteriori JED problem and simultaneously exploits the sparsity of cell-free massive MU-MIMO channels as well as the boundedness of QAM constellations. In order to improve the performance and convergence of the algorithm, we propose methods that permute the access point and UE indices to form so-called virtual cells, which leads to better initial solutions. We assess the performance of our algorithm in terms of root-mean-squared-symbol error, bit error rate, and mutual information, and we demonstrate that JED significantly reduces the pilot overhead compared to orthogonal training, which enables reliable communication with short packets to a large number of UEs.