 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating BERT into Parallel Sequence Decoding with Adapters
Oct 13, 2020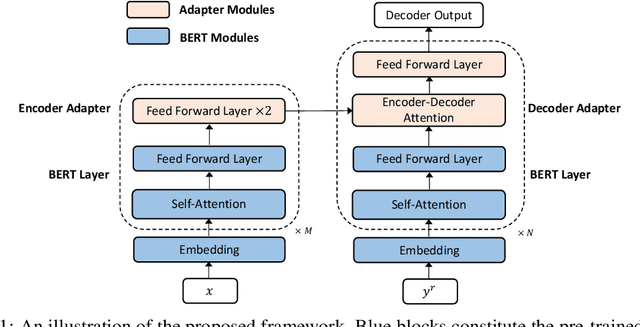
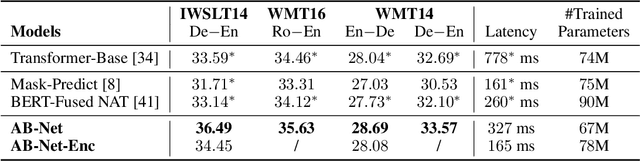

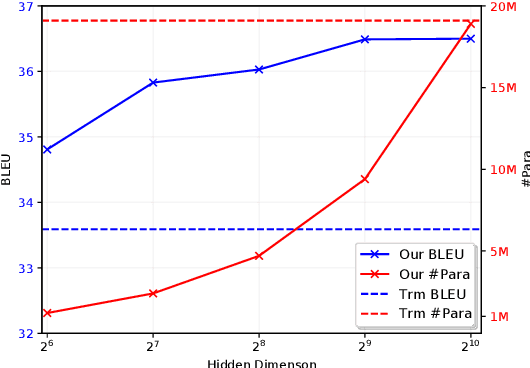
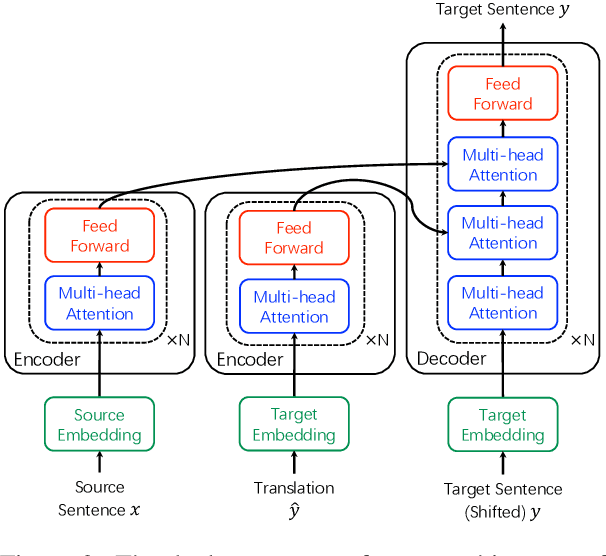
While large scale pre-trained language models such as BERT have achieved great success on various natural language understanding tasks, how to efficiently and effectively incorporate them into sequence-to-sequence models and the corresponding text generation tasks remains a non-trivial problem. In this paper, we propose to address this problem by taking two different BERT models as the encoder and decoder respectively, and fine-tuning them by introducing simple and lightweight adapter modules, which are inserted between BERT layers and tuned on the task-specific dataset. In this way, we obtain a flexible and efficient model which is able to jointly leverage the information contained in the source-side and target-side BERT models, while bypassing the catastrophic forgetting problem. Each component in the framework can be considered as a plug-in unit, making the framework flexible and task agnostic. Our framework is based on a parallel sequence decoding algorithm named Mask-Predict considering the bi-directional and conditional independent nature of BERT, and can be adapted to traditional autoregressive decoding easily. We conduct extensive experiments on neural machine translation tasks where the proposed method consistently outperforms autoregressive baselines while reducing the inference latency by half, and achieves $36.49$/$33.57$ BLEU scores on IWSLT14 German-English/WMT14 German-English translation. When adapted to autoregressive decoding, the proposed method achieves $30.60$/$43.56$ BLEU scores on WMT14 English-German/English-French translation, on par with the state-of-the-art baseline models.
Iterative Domain-Repaired Back-Translation
Oct 06, 2020


In this paper, we focus on the domain-specific translation with low resources, where in-domain parallel corpora are scarce or nonexistent. One common and effective strategy for this case is exploiting in-domain monolingual data with the back-translation method. However, the synthetic parallel data is very noisy because they are generated by imperfect out-of-domain systems, resulting in the poor performance of domain adaptation. To address this issue, we propose a novel iterative domain-repaired back-translation framework, which introduces the Domain-Repair (DR) model to refine translations in synthetic bilingual data. To this end, we construct corresponding data for the DR model training by round-trip translating the monolingual sentences, and then design the unified training framework to optimize paired DR and NMT models jointly. Experiments on adapting NMT models between specific domains and from the general domain to specific domains demonstrate the effectiveness of our proposed approach, achieving 15.79 and 4.47 BLEU improvements on average over unadapted models and back-translation.
Generating Diverse Translation by Manipulating Multi-Head Attention
Nov 21, 2019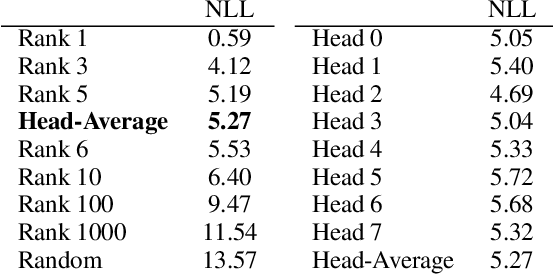


Transformer model has been widely used on machine translation tasks and obtained state-of-the-art results. In this paper, we report an interesting phenomenon in its encoder-decoder multi-head attention: different attention heads of the final decoder layer align to different word translation candidates. We empirically verify this discovery and propose a method to generate diverse translations by manipulating heads. Furthermore, we make use of these diverse translations with the back-translation technique for better data augmentation. Experiment results show that our method generates diverse translations without severe drop in translation quality. Experiments also show that back-translation with these diverse translations could bring significant improvement on performance on translation tasks. An auxiliary experiment of conversation response generation task proves the effect of diversity as well.