 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-based Graph Neural Network for Heterogeneous Structural Learning
Dec 19, 2019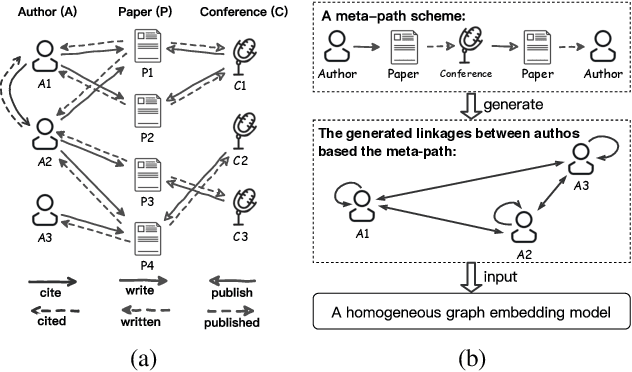
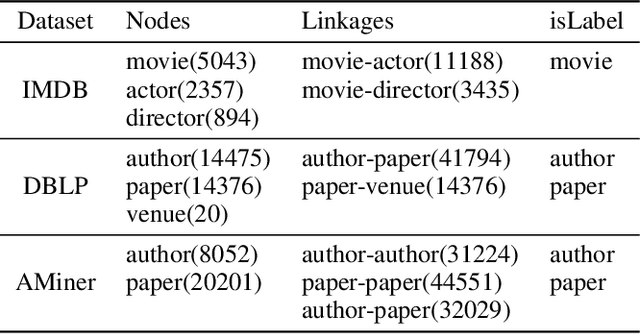
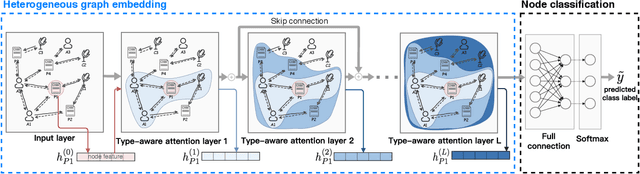
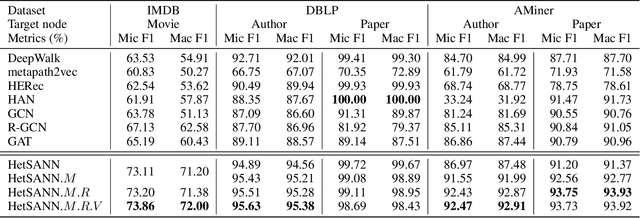
In this paper, we focus on graph representation learning of heterogeneous information network (HIN), in which various types of vertices are connected by various types of relations. Most of the existing methods conducted on HIN revise homogeneous graph embedding models via meta-paths to learn low-dimensional vector space of HIN. In this paper, we propose a novel Heterogeneous Graph Structural Attention Neural Network (HetSANN) to directly encode structural information of HIN without meta-path and achieve more informative representations. With this method, domain experts will not be needed to design meta-path schemes and the heterogeneous information can be processed automatically by our proposed model. Specifically, we implicitly represent heterogeneous information using the following two methods: 1) we model the transformation between heterogeneous vertices through a projection in low-dimensional entity spaces; 2) afterwards, we apply the graph neural network to aggregate multi-relational information of projected neighborhood by means of attention mechanism. We also present three extensions of HetSANN, i.e., voices-sharing product attention for the pairwise relationships in HIN, cycle-consistency loss to retain the transformation between heterogeneous entity spaces, and multi-task learning with full use of information. The experiments conducted on three public datasets demonstrate that our proposed models achieve significant and consistent improvements compared to state-of-the-art solutions.
Virtual Adversarial Training on Graph Convolutional Networks in Node Classification
Feb 28, 2019
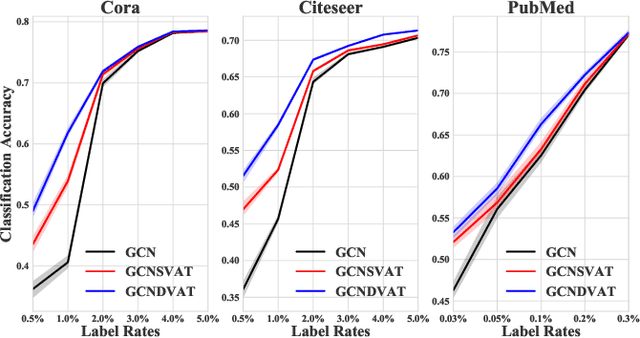


The effectiveness of Graph Convolutional Networks (GCNs) has been demonstrated in a wide range of graph-based machine learning tasks. However, the update of parameters in GCNs is only from labeled nodes, lacking the utilization of unlabeled data. In this paper, we apply Virtual Adversarial Training (VAT), an adversarial regularization method based on both labeled and unlabeled data, on the supervised loss of GCN to enhance its generalization performance. By imposing virtually adversarial smoothness on the posterior distribution in semi-supervised learning, VAT yields improvement on the Symmetrical Laplacian Smoothness of GCNs. In addition, due to the difference of property in features, we perturb virtual adversarial perturbations on sparse and dense features, resulting in GCN Sparse VAT (GCNSVAT) and GCN Dense VAT (GCNDVAT) algorithms, respectively. Extensive experiments verify the effectiveness of our two methods across different training sizes. Our work paves the way towards better understanding the direction of improvement on GCNs in the future.