 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster than real-time detection of shot boundaries, sampling structure and dynamic keyframes in video
Feb 13, 2025The detection of shot boundaries (hardcuts and short dissolves), sampling structure (progressive / interlaced / pulldown) and dynamic keyframes in a video are fundamental video analysis tasks which have to be done before any further high-level analysis tasks. We present a novel algorithm which does all these analysis tasks in an unified way, by utilizing a combination of inter-frame and intra-frame measures derived from the motion field and normalized cross correlation. The algorithm runs four times faster than real-time due to sparse and selective calculation of these measures. An initial evaluation furthermore shows that the proposed algorithm is extremely robust even for challenging content showing large camera or object motion, flashlights, flicker or low contrast / noise.
Porting Large Language Models to Mobile Devices for Question Answering
Apr 24, 2024
Deploying Large Language Models (LLMs) on mobile devices makes all the capabilities of natural language processing available on the device. An important use case of LLMs is question answering, which can provide accurate and contextually relevant answers to a wide array of user queries. We describe how we managed to port state of the art LLMs to mobile devices, enabling them to operate natively on the device. We employ the llama.cpp framework, a flexible and self-contained C++ framework for LLM inference. We selected a 6-bit quantized version of the Orca-Mini-3B model with 3 billion parameters and present the correct prompt format for this model. Experimental results show that LLM inference runs in interactive speed on a Galaxy S21 smartphone and that the model delivers high-quality answers to user queries related to questions from different subjects like politics, geography or history.
A real-time algorithm for human action recognition in RGB and thermal video
Apr 04, 2023Monitoring the movement and actions of humans in video in real-time is an important task. We present a deep learning based algorithm for human action recognition for both RGB and thermal cameras. It is able to detect and track humans and recognize four basic actions (standing, walking, running, lying) in real-time on a notebook with a NVIDIA GPU. For this, it combines state of the art components for object detection (Scaled YoloV4), optical flow (RAFT) and pose estimation (EvoSkeleton). Qualitative experiments on a set of tunnel videos show that the proposed algorithm works robustly for both RGB and thermal video.
FastHebb: Scaling Hebbian Training of Deep Neural Networks to ImageNet Level
Jul 07, 2022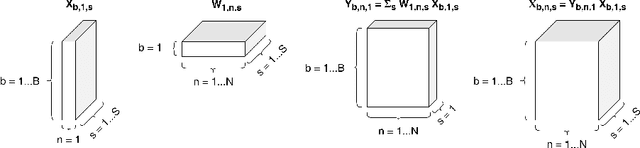
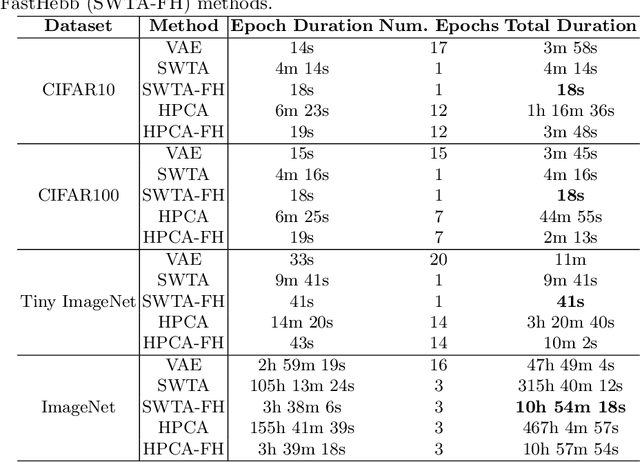
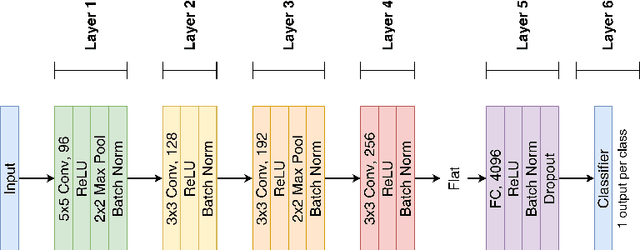
Learning algorithms for Deep Neural Networks are typically based on supervised end-to-end Stochastic Gradient Descent (SGD) training with error backpropagation (backprop). Backprop algorithms require a large number of labelled training samples to achieve high performance. However, in many realistic applications, even if there is plenty of image samples, very few of them are labelled, and semi-supervised sample-efficient training strategies have to be used. Hebbian learning represents a possible approach towards sample efficient training; however, in current solutions, it does not scale well to large datasets. In this paper, we present FastHebb, an efficient and scalable solution for Hebbian learning which achieves higher efficiency by 1) merging together update computation and aggregation over a batch of inputs, and 2) leveraging efficient matrix multiplication algorithms on GPU. We validate our approach on different computer vision benchmarks, in a semi-supervised learning scenario. FastHebb outperforms previous solutions by up to 50 times in terms of training speed, and notably, for the first time, we are able to bring Hebbian algorithms to ImageNet scale.
A qualitative investigation of optical flow algorithms for video denoising
Apr 19, 2022


A good optical flow estimation is crucial in many video analysis and restoration algorithms employed in application fields like media industry, industrial inspection and automotive. In this work, we investigate how well optical flow algorithms perform qualitatively when integrated into a state of the art video denoising algorithm. Both classic optical flow algorithms (e.g. TV-L1) as well as recent deep learning based algorithm (like RAFT or BMBC) will be taken into account. For the qualitative investigation, we will employ realistic content with challenging characteristic (noisy content, large motion etc.) instead of the standard images used in most publications.
AdaFamily: A family of Adam-like adaptive gradient methods
Mar 03, 2022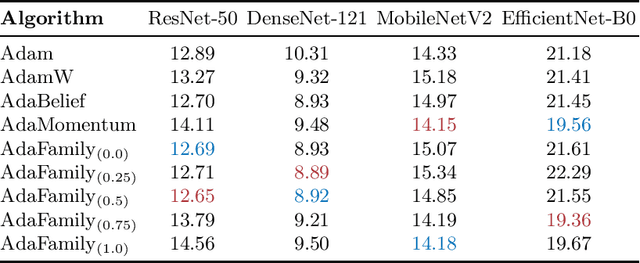
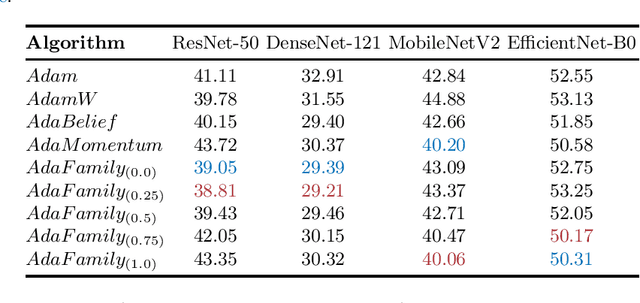
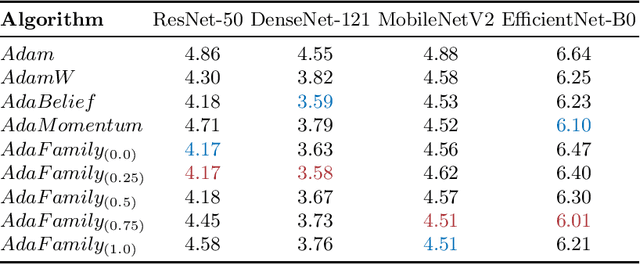
We propose AdaFamily, a novel method for training deep neural networks. It is a family of adaptive gradient methods and can be interpreted as sort of a blend of the optimization algorithms Adam, AdaBelief and AdaMomentum. We perform experiments on standard datasets for image classification, demonstrating that our proposed method outperforms these algorithms.
Some like it tough: Improving model generalization via progressively increasing the training difficulty
Oct 25, 2021
In this work, we propose to progressively increase the training difficulty during learning a neural network model via a novel strategy which we call mini-batch trimming. This strategy makes sure that the optimizer puts its focus in the later training stages on the more difficult samples, which we identify as the ones with the highest loss in the current mini-batch. The strategy is very easy to integrate into an existing training pipeline and does not necessitate a change of the network model. Experiments on several image classification problems show that mini-batch trimming is able to increase the generalization ability (measured via final test error) of the trained model.
Detecting speaking persons in video
Oct 25, 2021
We present a novel method for detecting speaking persons in video, by extracting facial landmarks with a neural network and analysing these landmarks statistically over time
Hyper360 -- a Next Generation Toolset for Immersive Media
Aug 01, 2021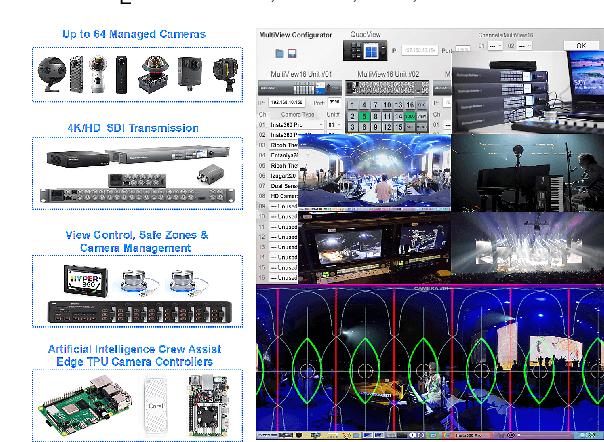
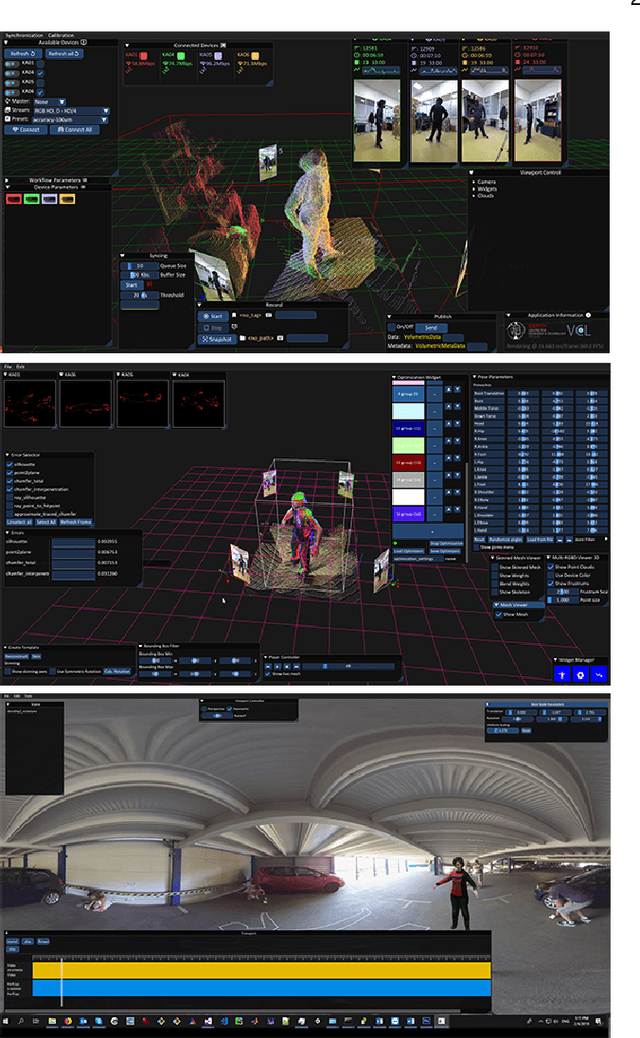

Spherical 360{\deg} video is a novel media format, rapidly becoming adopted in media production and consumption of immersive media. Due to its novelty, there is a lack of tools for producing highly engaging interactive 360{\deg} video for consumption on a multitude of platforms. In this work, we describe the work done so far in the Hyper360 project on tools for mixed 360{\deg} video and 3D content. Furthermore, the first pilots which have been produced with the Hyper360 tools and results of the audience assessment of the produced pilots are presented.
Automatic cinematography for 360 video
Sep 02, 2020
We describe our method for automatic generation of a visually interesting camera path (automatic cinematography)from a 360 video. Based on the information from the scene objects, multiple shot hypotheses for different shot types are constructed and the best one is rendered.