 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Dynamics-embedded Neural Network for Long-Sequence Modeling
Feb 23, 2024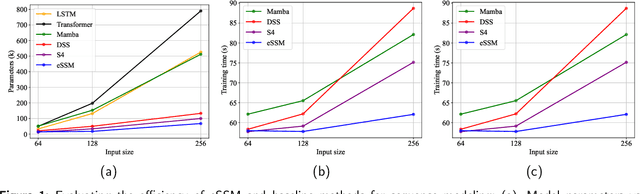

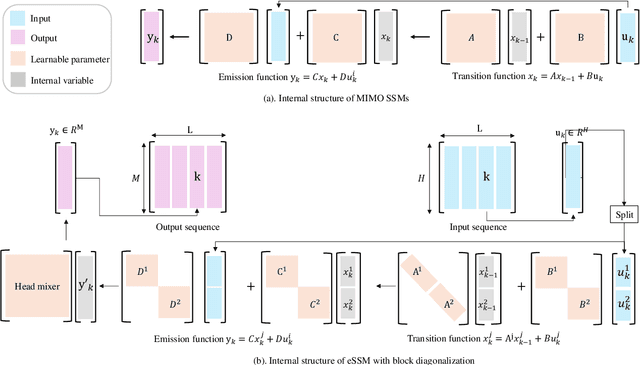
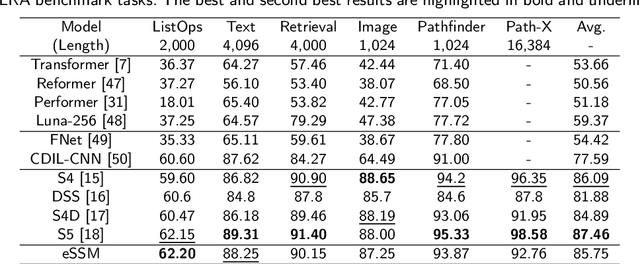
The trade-off between performance and computational efficiency in long-sequence modeling becomes a bottleneck for existing models. Inspired by the continuous state space models (SSMs) with multi-input and multi-output in control theory, we propose a new neural network called Linear Dynamics-embedded Neural Network (LDNN). SSMs' continuous, discrete, and convolutional properties enable LDNN to have few parameters, flexible inference, and efficient training in long-sequence tasks. Two efficient strategies, diagonalization and $'\text{Disentanglement then Fast Fourier Transform (FFT)}'$, are developed to reduce the time complexity of convolution from $O(LNH\max\{L, N\})$ to $O(LN\max \{H, \log L\})$. We further improve LDNN through bidirectional noncausal and multi-head settings to accommodate a broader range of applications. Extensive experiments on the Long Range Arena (LRA) demonstrate the effectiveness and state-of-the-art performance of LDNN.
Spatiotemporal Observer Design for Predictive Learning of High-Dimensional Data
Feb 23, 2024



Although deep learning-based methods have shown great success in spatiotemporal predictive learning, the framework of those models is designed mainly by intuition. How to make spatiotemporal forecasting with theoretical guarantees is still a challenging issue. In this work, we tackle this problem by applying domain knowledge from the dynamical system to the framework design of deep learning models. An observer theory-guided deep learning architecture, called Spatiotemporal Observer, is designed for predictive learning of high dimensional data. The characteristics of the proposed framework are twofold: firstly, it provides the generalization error bound and convergence guarantee for spatiotemporal prediction; secondly, dynamical regularization is introduced to enable the model to learn system dynamics better during training. Further experimental results show that this framework could capture the spatiotemporal dynamics and make accurate predictions in both one-step-ahead and multi-step-ahead forecasting scenarios.
Multiscale information fusion for fault detection and localization of battery energy storage systems
Oct 17, 2023Battery energy storage system (BESS) has great potential to combat global warming. However, internal abnormalities in the BESS may develop into thermal runaway, causing serious safety incidents. In this study, the multiscale information fusion is proposed for thermal abnormality detection and localization in BESSs. We introduce the concept of dissimilarity entropy as a means to identify anomalies for lumped variables, whereas spatial and temporal entropy measures are presented for the detection of anomalies for distributed variables. Through appropriate parameter optimization, these three entropy functions are integrated into the comprehensive multiscale detection index, which outperforms traditional single-scale detection methods. The proposed multiscale statistic has good interpretability in terms of system energy concentration. Battery system internal short circuit (ISC) experiments have demonstrated that our proposed method can swiftly identify ISC abnormalities and accurately pinpoint the problematic battery cells.
Fidelity-based Probabilistic Q-learning for Control of Quantum Systems
Jun 08, 2018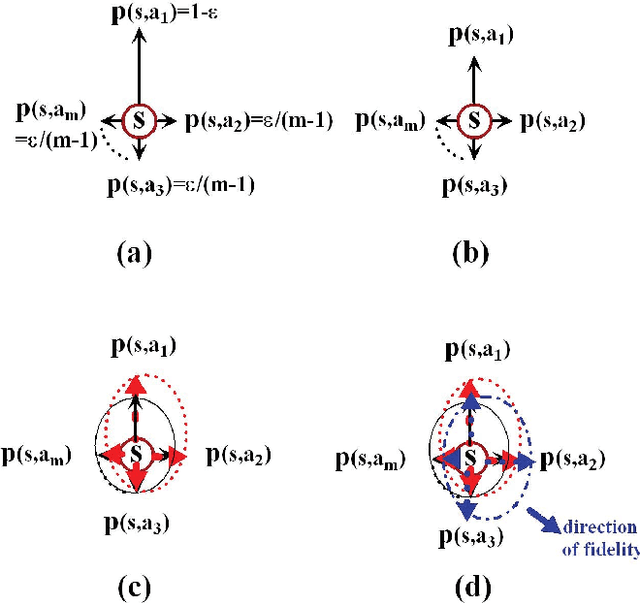
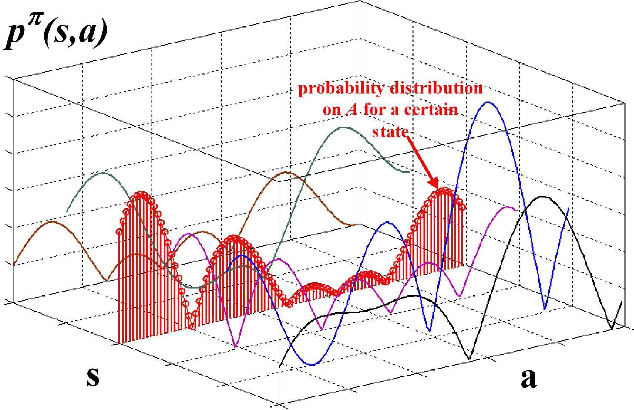
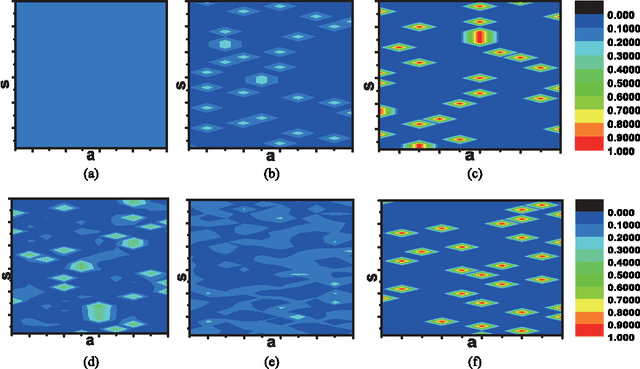

The balance between exploration and exploitation is a key problem for reinforcement learning methods, especially for Q-learning. In this paper, a fidelity-based probabilistic Q-learning (FPQL) approach is presented to naturally solve this problem and applied for learning control of quantum systems. In this approach, fidelity is adopted to help direct the learning process and the probability of each action to be selected at a certain state is updated iteratively along with the learning process, which leads to a natural exploration strategy instead of a pointed one with configured parameters. A probabilistic Q-learning (PQL) algorithm is first presented to demonstrate the basic idea of probabilistic action selection. Then the FPQL algorithm is presented for learning control of quantum systems. Two examples (a spin- 1/2 system and a lamda-type atomic system) are demonstrated to test the performance of the FPQL algorithm. The results show that FPQL algorithms attain a better balance between exploration and exploitation, and can also avoid local optimal policies and accelerate the learning process.
* 13 pages, 16 figures