 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixKG: Mixing for harder negative samples in knowledge graph
Feb 19, 2022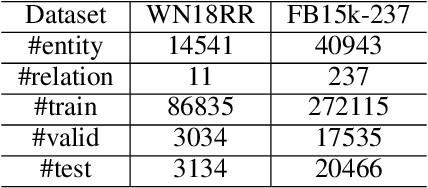
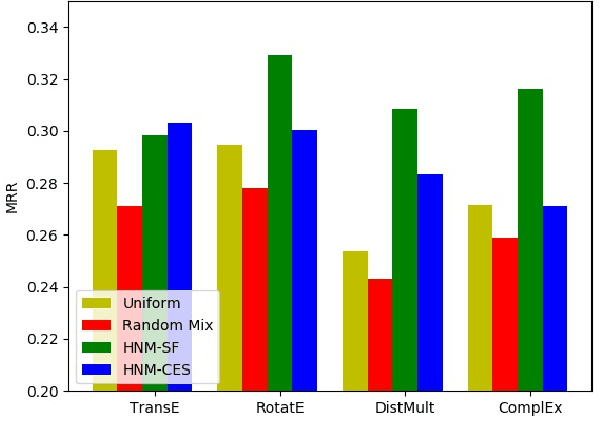

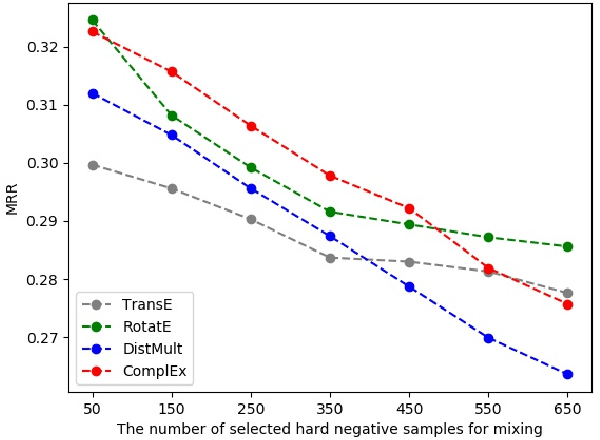
Knowledge graph embedding~(KGE) aims to represent entities and relations into low-dimensional vectors for many real-world applications. The representations of entities and relations are learned via contrasting the positive and negative triplets. Thus, high-quality negative samples are extremely important in KGE. However, the present KGE models either rely on simple negative sampling methods, which makes it difficult to obtain informative negative triplets; or employ complex adversarial methods, which requires more training data and strategies. In addition, these methods can only construct negative triplets using the existing entities, which limits the potential to explore harder negative triplets. To address these issues, we adopt mixing operation in generating harder negative samples for knowledge graphs and introduce an inexpensive but effective method called MixKG. Technically, MixKG first proposes two kinds of criteria to filter hard negative triplets among the sampled negatives: based on scoring function and based on correct entity similarity. Then, MixKG synthesizes harder negative samples via the convex combinations of the paired selected hard negatives. Experiments on two public datasets and four classical KGE methods show MixKG is superior to previous negative sampling algorithms.
Knowledge graph enhanced recommender system
Dec 17, 2021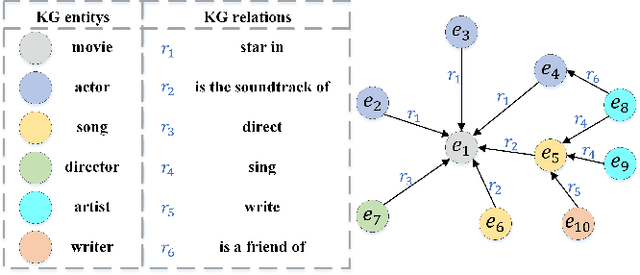
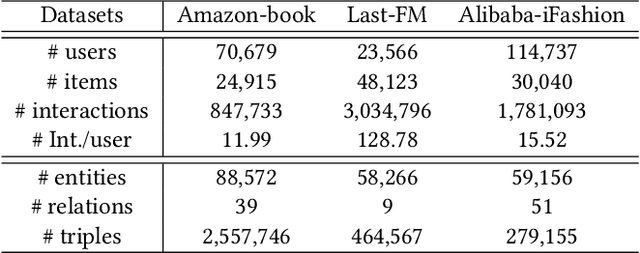
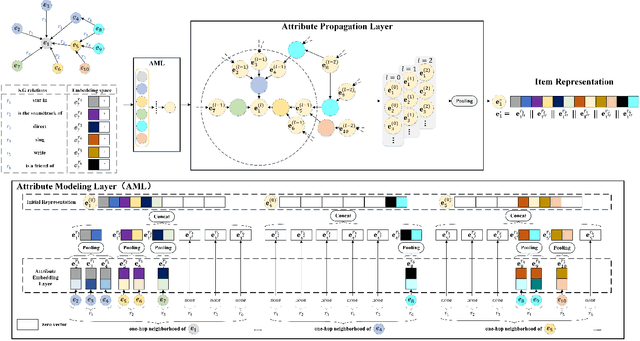

Knowledge Graphs (KGs) have shown great success in recommendation. This is attributed to the rich attribute information contained in KG to improve item and user representations as side information. However, existing knowledge-aware methods leverage attribute information at a coarse-grained level both in item and user side. In this paper, we proposed a novel attentive knowledge graph attribute network(AKGAN) to learn item attributes and user interests via attribute information in KG. Technically, AKGAN adopts a heterogeneous graph neural network framework, which has a different design between the first layer and the latter layer. With one attribute placed in the corresponding range of element-wise positions, AKGAN employs a novel interest-aware attention network, which releases the limitation that the sum of attention weight is 1, to model the complexity and personality of user interests towards attributes. Experimental results on three benchmark datasets show the effectiveness and explainability of AKGAN.
Multi-Level Graph Contrastive Learning
Jul 06, 2021

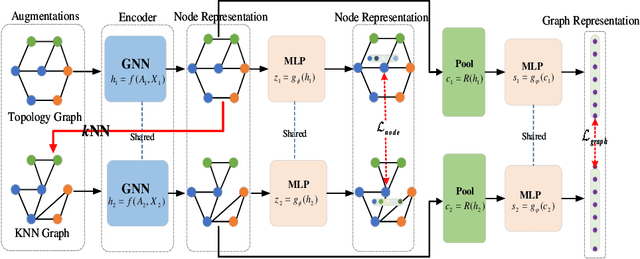
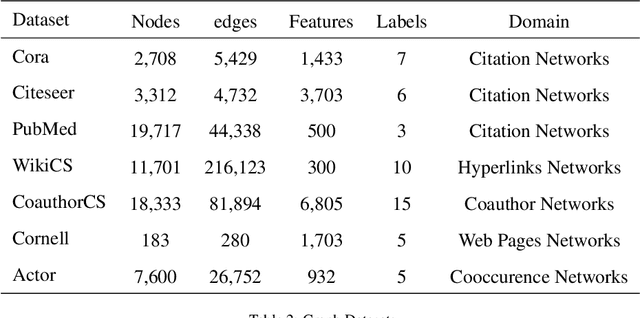
Graph representation learning has attracted a surge of interest recently, whose target at learning discriminant embedding for each node in the graph. Most of these representation methods focus on supervised learning and heavily depend on label information. However, annotating graphs are expensive to obtain in the real world, especially in specialized domains (i.e. biology), as it needs the annotator to have the domain knowledge to label the graph. To approach this problem, self-supervised learning provides a feasible solution for graph representation learning. In this paper, we propose a Multi-Level Graph Contrastive Learning (MLGCL) framework for learning robust representation of graph data by contrasting space views of graphs. Specifically, we introduce a novel contrastive view - topological and feature space views. The original graph is first-order approximation structure and contains uncertainty or error, while the $k$NN graph generated by encoding features preserves high-order proximity. Thus $k$NN graph generated by encoding features not only provide a complementary view, but is more suitable to GNN encoder to extract discriminant representation. Furthermore, we develop a multi-level contrastive mode to preserve the local similarity and semantic similarity of graph-structured data simultaneously. Extensive experiments indicate MLGCL achieves promising results compared with the existing state-of-the-art graph representation learning methods on seven datasets.
Tucker decomposition-based Temporal Knowledge Graph Completion
Nov 16, 2020
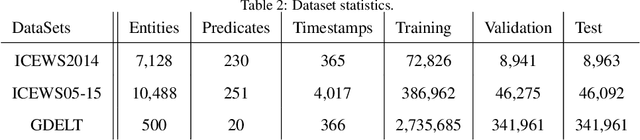
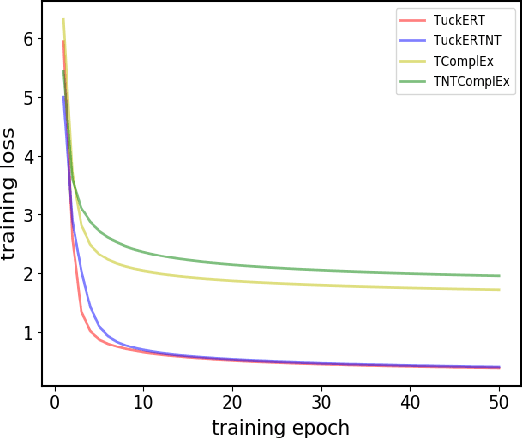
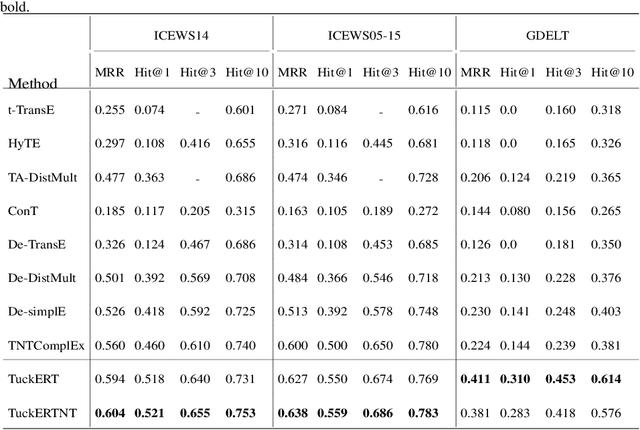
Knowledge graphs have been demonstrated to be an effective tool for numerous intelligent applications. However, a large amount of valuable knowledge still exists implicitly in the knowledge graphs. To enrich the existing knowledge graphs, recent years witness that many algorithms for link prediction and knowledge graphs embedding have been designed to infer new facts. But most of these studies focus on the static knowledge graphs and ignore the temporal information that reflects the validity of knowledge. Developing the model for temporal knowledge graphs completion is an increasingly important task. In this paper, we build a new tensor decomposition model for temporal knowledge graphs completion inspired by the Tucker decomposition of order 4 tensor. We demonstrate that the proposed model is fully expressive and report state-of-the-art results for several public benchmarks. Additionally, we present several regularization schemes to improve the strategy and study their impact on the proposed model. Experimental studies on three temporal datasets (i.e. ICEWS2014, ICEWS2005-15, GDELT) justify our design and demonstrate that our model outperforms baselines with an explicit margin on link prediction task.
Self-supervised Graph Representation Learning via Bootstrapping
Nov 12, 2020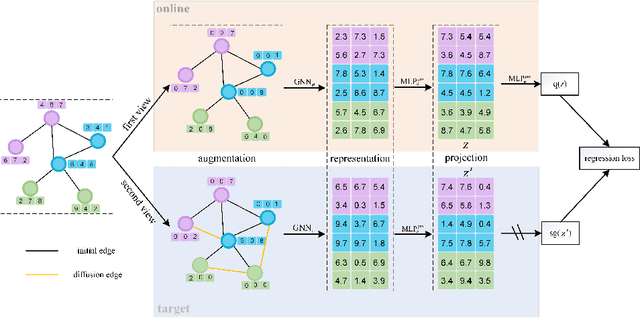
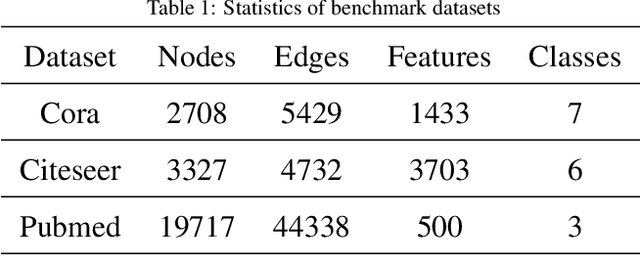
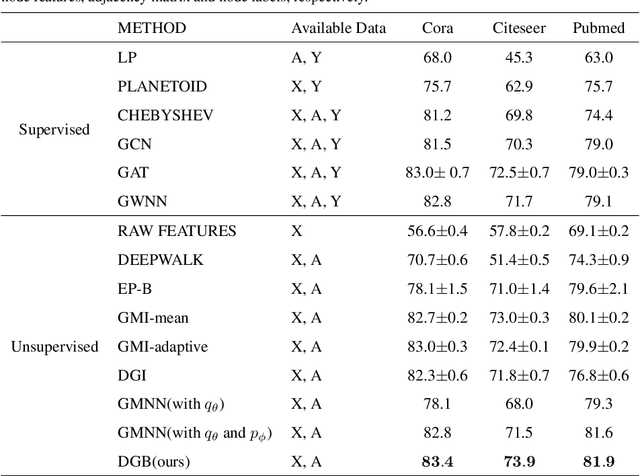
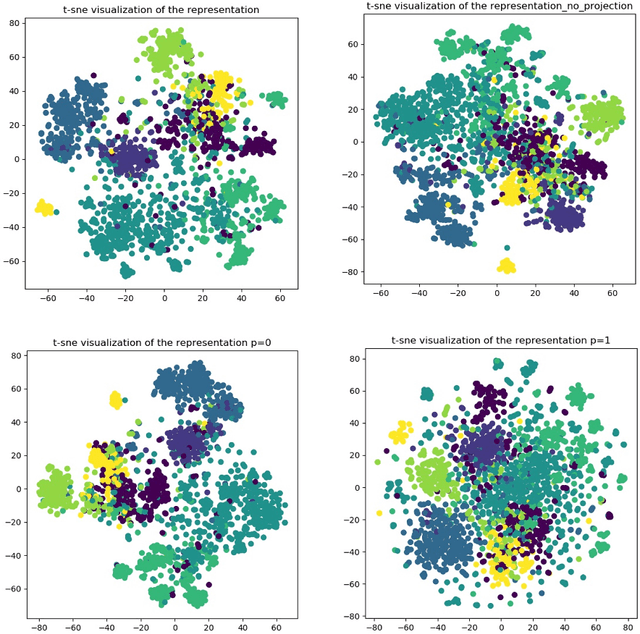
Graph neural networks~(GNNs) apply deep learning techniques to graph-structured data and have achieved promising performance in graph representation learning. However, existing GNNs rely heavily on enough labels or well-designed negative samples. To address these issues, we propose a new self-supervised graph representation method: deep graph bootstrapping~(DGB). DGB consists of two neural networks: online and target networks, and the input of them are different augmented views of the initial graph. The online network is trained to predict the target network while the target network is updated with a slow-moving average of the online network, which means the online and target networks can learn from each other. As a result, the proposed DGB can learn graph representation without negative examples in an unsupervised manner. In addition, we summarize three kinds of augmentation methods for graph-structured data and apply them to the DGB. Experiments on the benchmark datasets show the DGB performs better than the current state-of-the-art methods and how the augmentation methods affect the performances.