 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Gradient Descent Mitigates Anisotropy-Driven Misalignment: A Case Study in Phase Retrieval
Jan 30, 2026Spectral gradient methods, such as the Muon optimizer, modify gradient updates by preserving directional information while discarding scale, and have shown strong empirical performance in deep learning. We investigate the mechanisms underlying these gains through a dynamical analysis of a nonlinear phase retrieval model with anisotropic Gaussian inputs, equivalent to training a two-layer neural network with the quadratic activation and fixed second-layer weights. Focusing on a spiked covariance setting where the dominant variance direction is orthogonal to the signal, we show that gradient descent (GD) suffers from a variance-induced misalignment: during the early escaping stage, the high-variance but uninformative spike direction is multiplicatively amplified, degrading alignment with the true signal under strong anisotropy. In contrast, spectral gradient descent (SpecGD) removes this spike amplification effect, leading to stable alignment and accelerated noise contraction. Numerical experiments confirm the theory and show that these phenomena persist under broader anisotropic covariances.
Neuron Block Dynamics for XOR Classification with Zero-Margin
Jan 30, 2026The ability of neural networks to learn useful features through stochastic gradient descent (SGD) is a cornerstone of their success. Most theoretical analyses focus on regression or on classification tasks with a positive margin, where worst-case gradient bounds suffice. In contrast, we study zero-margin nonlinear classification by analyzing the Gaussian XOR problem, where inputs are Gaussian and the XOR decision boundary determines labels. In this setting, a non-negligible fraction of data lies arbitrarily close to the boundary, breaking standard margin-based arguments. Building on Glasgow's (2024) analysis, we extend the study of training dynamics from discrete to Gaussian inputs and develop a framework for the dynamics of neuron blocks. We show that neurons cluster into four directions and that block-level signals evolve coherently, a phenomenon essential in the Gaussian setting where individual neuron signals vary significantly. Leveraging this block perspective, we analyze generalization without relying on margin assumptions, adopting an average-case view that distinguishes regions of reliable prediction from regions of persistent error. Numerical experiments confirm the predicted two-phase block dynamics and demonstrate their robustness beyond the Gaussian setting.
* 47 pages, 9 figures
Learning a Single Index Model from Anisotropic Data with vanilla Stochastic Gradient Descent
Mar 31, 2025We investigate the problem of learning a Single Index Model (SIM)- a popular model for studying the ability of neural networks to learn features - from anisotropic Gaussian inputs by training a neuron using vanilla Stochastic Gradient Descent (SGD). While the isotropic case has been extensively studied, the anisotropic case has received less attention and the impact of the covariance matrix on the learning dynamics remains unclear. For instance, Mousavi-Hosseini et al. (2023b) proposed a spherical SGD that requires a separate estimation of the data covariance matrix, thereby oversimplifying the influence of covariance. In this study, we analyze the learning dynamics of vanilla SGD under the SIM with anisotropic input data, demonstrating that vanilla SGD automatically adapts to the data's covariance structure. Leveraging these results, we derive upper and lower bounds on the sample complexity using a notion of effective dimension that is determined by the structure of the covariance matrix instead of the input data dimension.
VEC-SBM: Optimal Community Detection with Vectorial Edges Covariates
Feb 29, 2024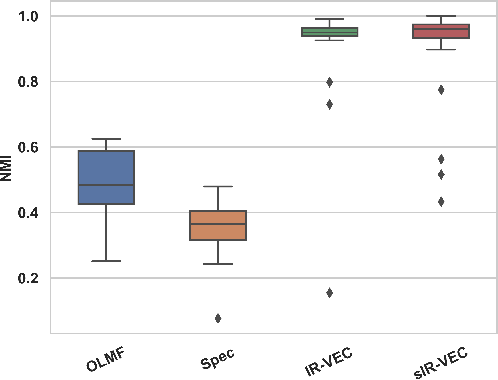
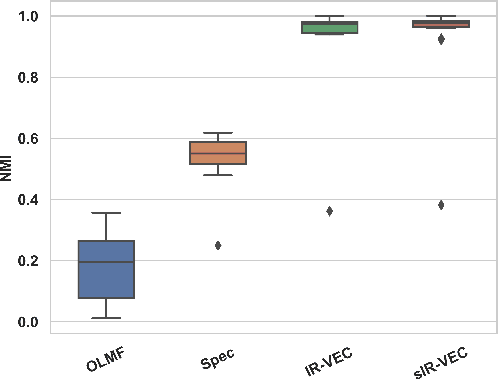
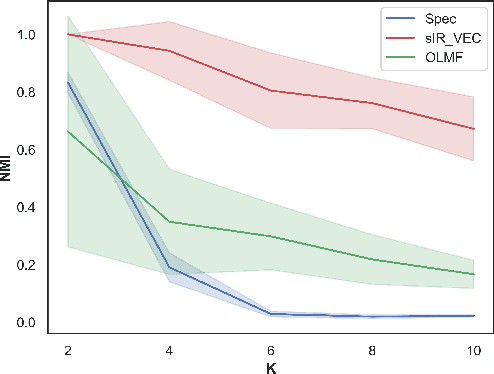
Social networks are often associated with rich side information, such as texts and images. While numerous methods have been developed to identify communities from pairwise interactions, they usually ignore such side information. In this work, we study an extension of the Stochastic Block Model (SBM), a widely used statistical framework for community detection, that integrates vectorial edges covariates: the Vectorial Edges Covariates Stochastic Block Model (VEC-SBM). We propose a novel algorithm based on iterative refinement techniques and show that it optimally recovers the latent communities under the VEC-SBM. Furthermore, we rigorously assess the added value of leveraging edge's side information in the community detection process. We complement our theoretical results with numerical experiments on synthetic and semi-synthetic data.
Seeded graph matching for the correlated Wigner model via the projected power method
Apr 08, 2022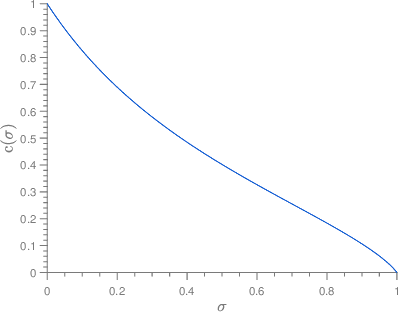
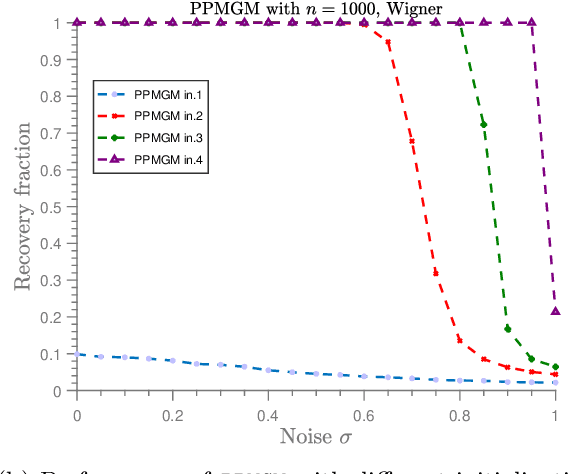
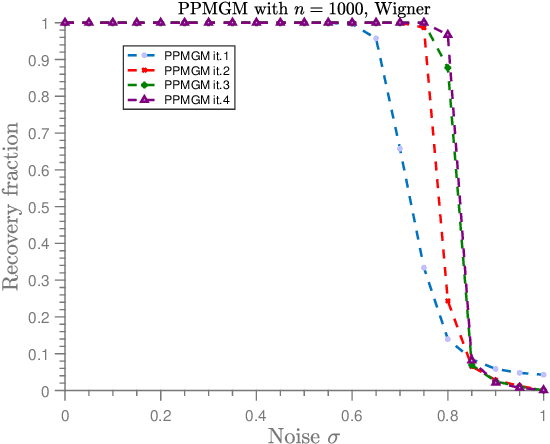
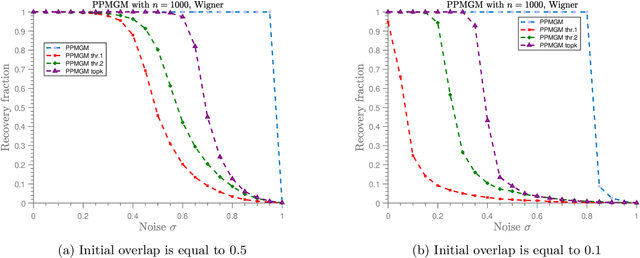
In the graph matching problem we observe two graphs $G,H$ and the goal is to find an assignment (or matching) between their vertices such that some measure of edge agreement is maximized. We assume in this work that the observed pair $G,H$ has been drawn from the correlated Wigner model -- a popular model for correlated weighted graphs -- where the entries of the adjacency matrices of $G$ and $H$ are independent Gaussians and each edge of $G$ is correlated with one edge of $H$ (determined by the unknown matching) with the edge correlation described by a parameter $\sigma\in [0,1)$. In this paper, we analyse the performance of the projected power method (PPM) as a seeded graph matching algorithm where we are given an initial partially correct matching (called the seed) as side information. We prove that if the seed is close enough to the ground-truth matching, then with high probability, PPM iteratively improves the seed and recovers the ground-truth matching (either partially or exactly) in $\mathcal{O}(\log n)$ iterations. Our results prove that PPM works even in regimes of constant $\sigma$, thus extending the analysis in (Mao et al.,2021) for the sparse Erd\"os-Renyi model to the (dense) Wigner model. As a byproduct of our analysis, we see that the PPM framework generalizes some of the state-of-art algorithms for seeded graph matching. We support and complement our theoretical findings with numerical experiments on synthetic data.
An iterative clustering algorithm for the Contextual Stochastic Block Model with optimality guarantees
Dec 20, 2021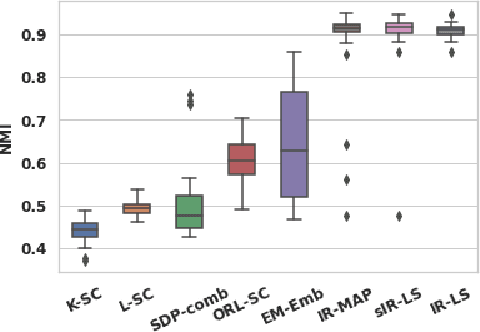

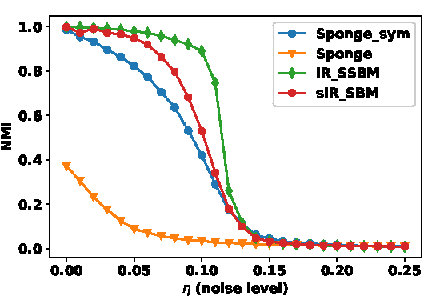
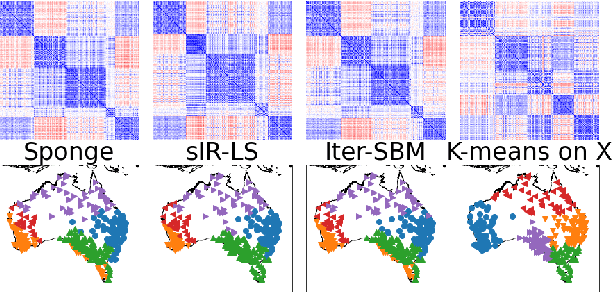
Real-world networks often come with side information that can help to improve the performance of network analysis tasks such as clustering. Despite a large number of empirical and theoretical studies conducted on network clustering methods during the past decade, the added value of side information and the methods used to incorporate it optimally in clustering algorithms are relatively less understood. We propose a new iterative algorithm to cluster networks with side information for nodes (in the form of covariates) and show that our algorithm is optimal under the Contextual Symmetric Stochastic Block Model. Our algorithm can be applied to general Contextual Stochastic Block Models and avoids hyperparameter tuning in contrast to previously proposed methods. We confirm our theoretical results on synthetic data experiments where our algorithm significantly outperforms other methods, and show that it can also be applied to signed graphs. Finally we demonstrate the practical interest of our method on real data.
Clustering multilayer graphs with missing nodes
Mar 04, 2021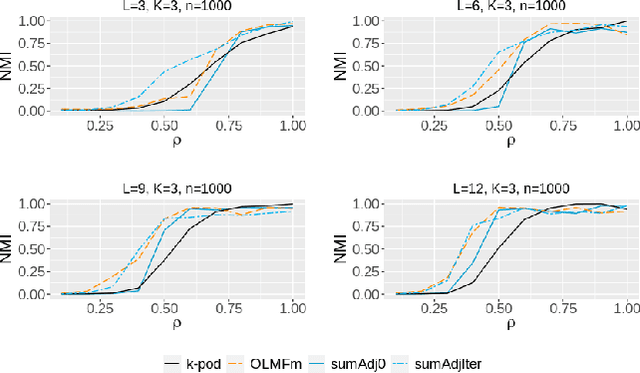
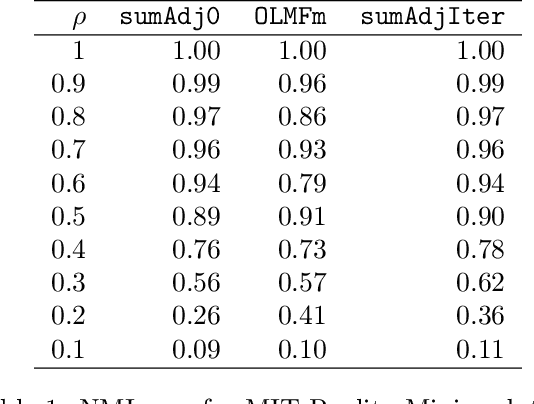
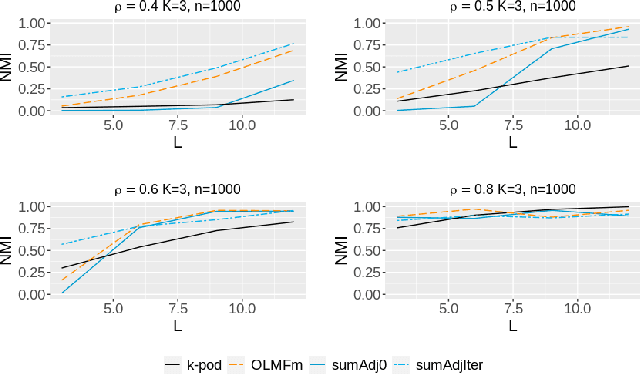
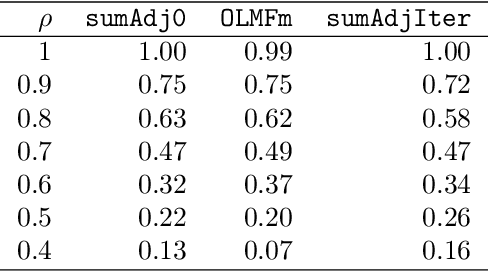
Relationship between agents can be conveniently represented by graphs. When these relationships have different modalities, they are better modelled by multilayer graphs where each layer is associated with one modality. Such graphs arise naturally in many contexts including biological and social networks. Clustering is a fundamental problem in network analysis where the goal is to regroup nodes with similar connectivity profiles. In the past decade, various clustering methods have been extended from the unilayer setting to multilayer graphs in order to incorporate the information provided by each layer. While most existing works assume - rather restrictively - that all layers share the same set of nodes, we propose a new framework that allows for layers to be defined on different sets of nodes. In particular, the nodes not recorded in a layer are treated as missing. Within this paradigm, we investigate several generalizations of well-known clustering methods in the complete setting to the incomplete one and prove some consistency results under the Multi-Layer Stochastic Block Model assumption. Our theoretical results are complemented by thorough numerical comparisons between our proposed algorithms on synthetic data, and also on real datasets, thus highlighting the promising behaviour of our methods in various settings.